






上一篇文章中写到了TCP协议的一些特点,这篇文章对http协议的大体内容做出一些解释,同时,更详细的协议参照RFC文档。这里写官方一点
http协议(超文本传输协议HyperText Transfer Protocol),它是基于TCP协议的应用层传输协议,就是客户端和服务器进行数据传输的一种规则。
Http协议
首先 先了解一下Http协议的基本格式,http是平时我们在使用浏览器过程中很常见的一个协议。下面的协议不一定是真实存在的,仅仅用作说明
- http://www.baidu.com:8080/stu/demo?id=1#ch1
上面是一条字节随便写的http协议, 其中
- http: 表示协议名,也就是使用的协议
- www.baidu.com 表示域名或者IP地址(是同一个内容 域名用NAT技术转变之后就是IP)
- 8080 表示端口号,平时很多时候没有写的话就是使用的http默认端口号80
- /stu/demo 表示访问的文件目录,如果省略该部分访问则是/ 根目录,因为服务器也是有组织的是一个树形结构。根节点一般对应服务器主页。(一般的约定,开发者遵不遵守不确立了)
- ?id=1 ? 号后面的表示查询字符串 这个是程序员自己定义的,不是开发者一般不知道别人定义的是啥意思。
- ch1 表示的是片段表示符,是前端的内容,我也不太了解,平时也不怎么常见,但大概的作用好像是用来记录当时网页所到的位置。
对于上述部分,很多内容是可以省略的。正因为这个灵活的特性,http协议被广泛应用现在。
url encode
当我们在www.baidu.com搜索C++为例
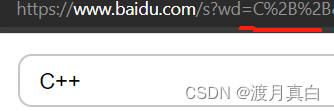
可以看到,搜索之后在查询字符串中C++变成了C%2B%2B,这是为什么呢,其实这个和编程中的反斜杠的含义差不多
因为在在查询字符中 可能会有一些特殊符号,同时这些特殊符号在url中本身就有一定的特殊含义,所以我们需要对一些特殊符号进行处理,来保证浏览器解析成功。
所以这里的url encode本质是一个转义字符。
- 转换规则,把每个需要转义的内容的二进制数据的每个字节都用十六进制来表示,然后再前面加上百分号就好了。
“ + ”号的assic码值就是0x2B
方法
有些学后端的同学可能,经常使用到方法,但是问具体是什么可能也不是很清楚。 方法就是描述当前http协议大概是干什么的,也是一种约定方法
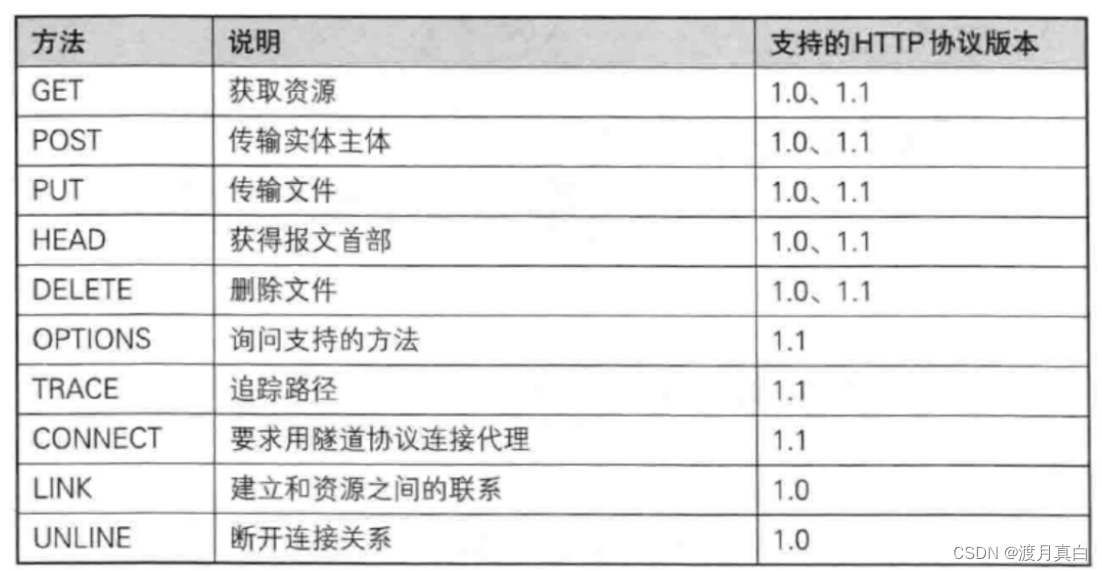
不一定要遵守后面约定,说明板块只是表示最好是干嘛。但具体内容还是有程序员设计的。很多时候设计的过程中,开发者都会放飞自我。
但是大部分开发中,get和post2个方法独占9成使用率,剩下的方法占剩下一成的使用率。
- get方法,一般会将自定义参数放到查询字符串中(query string) body一般是空的
- post方法,一般会将自定义参数放到body中 ,查询字符串是空的。
最大的差别就是用户在访问中能不能直接看到。
一些GET和POST方法的误区
1.get数据有长度限制
本人在对一些网络资料进行阅读的时候,看到好多都说,长数据使用post,因为get方法的url有长度的限制,但是在 RFC文档中明确指出了对url的长度不做任何的限制 ,但是在以前计算机资源短缺的情况下,在浏览器中确实有长度限制,但具体限制的多少,取决于浏览器
2. post比get方法安全
首先先明确一点安全的定义( 安全是指,在网络通信的过程中,数据不容易被黑客截取到,即使截取到了也不容易破解) 但是post请求只是保证了普通用户无法直接看到,对黑客完全没啥影响,保证安全的关键是加密
3. get是幂等的 post不是幂等的
这里先解释一个含义,什么是幂等,幂等就是每次相同的输入,输出的结果都能保持一致。就叫做幂等。 就比如gpt在运行过程中,就不能是幂等的,就是每次问相同的话,出来的结果就不同。
这句话出自RFC文档,当时上面写的是建议这么设计,就是实际开发中,是否遵守,另当别论所以说太绝对了就是不对的。
4.get可以缓存 post不能缓存
这一个机制其实是承接上述幂等的,因为在网页请求的过程中,有些操作可能很耗时,所以与其每次都进行计算机,不如直接缓存下来,但是缓存的前提是幂等,幂等就涉及到上述内容,所以说太绝对的话也是不对的。
这一段想讲的核心其实是,学到的每一个知识都应该要有自己的理解和判断,而不是看到网上说什么,八股是什么就直接去背。
请求报头
headers

这就是一条请求的报头 他也是键值对形式的结构每一行是一个键值对 同时键值对由 : 空格 分开 headers中的键值对是有标准规定的,但是查询字符串和body中的键值对就是开发者自己定义的了。
- host:表示服务器主机的地址和端口号
- Content-Length 描述了请求的body长度是多少个字节,如果有body这个字段必须要有
- Content-type 描述了body中的请求格式 就是针对这个数据http该怎么解析 因为http用途广泛,传输的数据是很多的
- User-Agent: 简称UA,表示浏览器和操作系统的属性,就是是什么浏览器和是什么操作系统发起的请求。 现在一般用来区分移动端和pc端
- Referer:用来描述从哪里来的,通俗讲就是如果是通过浏览器的输出地址打开了一个网页,这时候的这个请求是不带referer的,但是如果是在一个页面通过跳转进入了另一个页面,此时这个请求所携带的referer就是当前网页的。
这里给大家讲一个故事,在浏览器中,一个利润非常高的板块就是广告了,百度的广告占了百度的很大一部分,但是广告商一般是怎么来统计广告的呢,一般就是通过referer,要是这个链接是通过百度点进来的,通过referer就统计百度这边一次,要是搜狗浏览器点进来的,就统计搜狗一次,最后通过有效点击次数的多少,来决定金钱的大小。但是Referer这个东西是明文传输的,是否会有人偷偷改这个referer呢,答案是肯定的,而且这一个现象在2014年左右特别的火,而且修改的人也就是大家人尽皆知的运营商(移动,联通,电信)
在请求路由的过程中是通过路由器(交换机)进行转发的,运营商完全有技术在其中加入一个程序,来分析是否是广告的跳转请求,要是是的话,就进行修改referer
而且运营商也有自己的广告平台,运营商可以把referer改成自己的平台,所以有很大的利润。比如一个用户通过搜狗点进的一个广告,此时运营商把referer改成了自己的运营平台,然后运营商就可以自己赚钱了,要是搜狗那边程序员发现对不上账,肯定也会对数据一条一条的进行查询,但是查不出来的话,就不了了之了。
这个故事就是著名的故事 运营商劫持 所以这是一个非常恶劣的事情。所以百度搜狗这些肯定会告运营商的,但是打官司的过程中,一边一直在拖。打官司肯定能打赢,但一边的法务就是一直托着。详细自己去百度。
d
当然除了法律上的武器,肯定还要采取技术手段,这里的技术手段就是我们后面要讲的https也就是http的加密传输一般就是2014年左右开始流行的。
- cookie 是浏览器本地存储数据的一个机制 用户在网页操作的过程中会产生很多的数据,重要的数据会在服务器进行存储,但是有些数据是需要存储在用户电脑上的,而服务器不能对用户电脑的文件进行操作,此时就可以通过cookie进行一些键值对的存储,cookie中的值也是键值对的形式。 键值对之间用“ ;”号进行分割,键与值之间通过等号进行分割。
- session 前面已经讲到了cookie 那肯定需要把session也单独拎出来,cookie是一个存储在浏览器的存储键值对的东西,而session则是存储在服务器中的,cookie在一个用户换了一个浏览器之后之后,就会全部清除,但是session即使在用户换了浏览器之后,也会保留,因为他是存储在服务器中的一个程序 并且在服务器中,每个用户都单独对应了一个session,一般是通过哈希表这类数据结构进行维护的
下一篇文章https















 447
447

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









