






Dispatch Queue
Dispatch Queue 对于我们开发者来说应该是非常熟悉了,运用的场景非常之多,但是他的内部是如何实现的呢?
- 用于管理追加的Block的C语言层实现的FIFO队列
- Atomic函数中实现的用于排他控制的轻量级信号
- 用于管理线程的C语言层实现的一些容器
不难想象,GCD的实现需要使用以上这些工具,但是如果仅用这些内容便可实现,那么就不需要内核级实现了。(实际上在一般的Linux内核中可能使用面向Linux操作系统而移植的GCD)。
甚至有人会想,只要努力编写线程管理的代码,就根本用不到GCD,是这样的吗?
我们先来回顾一下苹果的官方说明:
通常,应用程序中编写的线程管理用的代码要在系统级实现。
实际上正如这句话所说,在系统级即iOS和OS X的核心XNU内核级上实现,因此无论编程人员如何努力编写管理线程的代码,在性能方面也不可能胜过XNU内核级所实现的GCD。
使用GCD要比使用pthreads和NSThread这些一般的多线程编程API更好。并且,如果用GCD就不必编写为操作线程反复出现的类似的源代码(这里被称为固定源代码片段),而可以在线程中集中实现处理内容,真的是好处多多。我们尽量多使用GCD或者使用了Cocoa框架GCD的NSOperationQueue类等API。
那么首先确认一下用于实现Dispatch Queue 而使用的软件组件。如表所示:

编程人员所使用GCD的API全部包含在libdispatch库的C语言函数。Dispatch Queue通过结构体和链表,被实现为FIFO队列。FIFO队列主要是负责管理通过dispatch_async等函数所追加的一系列Blocks。所以我们可以理解为一旦我们在程序中由上到下追加了一组Blocks,那么排除掉dispatch_after,其内部的追加过程是一个先进先出原则。
但是Block本身并不是直接加入到这个FIFO队列中,而是先加入Dispatch Continuation这一dispatch_continuation_t类型结构体中,然后再进入FIFO队列。该结构体用于记忆Block所属的Dispatch Group和其他一些信息,相当于一般常说的执行上下文(execution context)。
Dispatch Queue可通过dipatch_set_target_queue函数设定,可以设定执行该Dispatch Queue处理的Dispatch Queue为目标。该目标可像串珠子一样,设定多个连接在一起的Dispatch Queue,但是在连接串的最后必须设定为Main Dispatch Queue,或各种优先级的Global Dispatch Queue,或是准备用于Serial Dispatch Queue的各种优先级的Global Dispatch Queue。
Main Dispatch Queue 在RunLoop中执行Block。这并不是令人耳目一新的新技术。
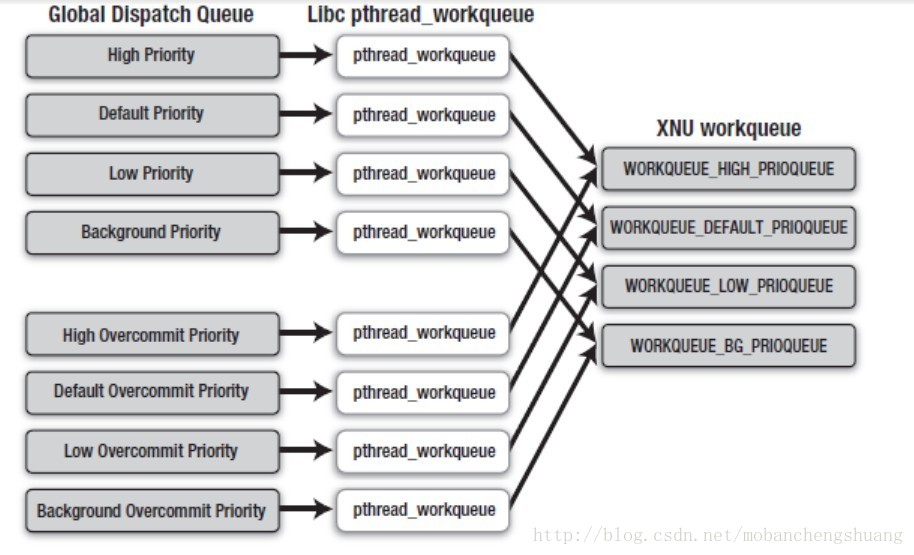
Global Dispatch Queue有如下8种:
Global Dispatch Queue (High priority)
Global Dispatch Queue (Default priority)
Global Dispatch Queue (Low priority)
Global Dispatch Queue (Background priority)
Global Dispatch Queue (High overcommit priority)
Global Dispatch Queue (Default overcommit priority)
Global Dispatch Queue (Low overcommit priority)
Global Dispatch Queue (Background overcommit priority)
注意前面四种 和后面四种不同优先级的Queue有一词之差:Overcommit。其区别就在于Overcommit Queue不管系统状态如何都会强制生成线程队列。
这8种Global Dispatch Queue 各使用一个pthread_workqueue。GCD初始化时,使用pthread_workqueue_create_np函数生成pthread_wrokqueue。
pthread_wrokqueue包含在Libc提供的pthreads API中。它通过系统的bsdthread_register和workq_open函数调用,在初始化XNU内核的workqueue之后获取其信息。
XNU内核有4种workqueue:
WORKQUEUE_HIGH_PRIOQUEUE
WORKQUEUE_DEFAULT_PRIOQUEUE
WORKQUEUE_LOW_PRIOQUEUE
WORKQUEUE_BG_PRIOQUEUE
以上为4种执行优先级的workqueue。该执行优先级与Global Dispatch Queue的4种执行优先级相同。
下面看一下Dispatch Queue中执行Block的过程。当在Global Dispatch Queue 中执行Block时,libdispatch 从Global Dispatch Queue自身的FIFO队列取出Dispatch Continuation,调用pthread_workqueue_additem_np函数。将该Global Dispatch Queue 本身、符合其优先级的workqueue信息以及执行Dispatch Continuation的回调函数等传递给参数。
pthread_workqueue_additem_np函数使用workq_kernreturn系统调用,通知workqueue增加应当执行的项目。根据该通知,XNU内核基于系统状态判断是否要生成线程。如果是Overcommit优先级的Global Dispatch Queue ,workqueue则始终生成线程。
该线程虽然与iOS和OS X中通常使用的线程大致相同,但是有一部分pthread API不能使用。详细信息可以参考苹果的官方文档《并发编程指南》的“Compatibility with POSIX Threads“这一章节。
另外,因为workqueue生成的线程在实现用于workqueue的线程计划表中运行,他的上下文切换(shift context)与普通的线程有很大的不同。这也是我们使用GCD的原因。
workqueue的线程执行pthread_workqueue函数,该函数调用libdispatch的回调函数。在该回调函数中执行加入到Global Dispatch Queue中的下一个Block。
以上就是Dispatch Queue执行的大概过程。
由此可知,在编程人员自己编写的线程管理代码中想发挥出原生GCD的性能是不可能的。
原文链接:http://blog.csdn.net/mobanchengshuang/article/details/10839049















 6058
6058

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









