







MongoDB是一个很像关系型数据库的非关系型数据库,它对于大数据很大的优势是支持数据分片,对MapReduce引擎内置支持。
| 关系型数据库 | 非关系型数据库 |
|---|---|
| 支持事务 | 无事务(性能提升) |
| 表之间有关联 | 数据与数据之间没关联 |
| 有表结构约束 | Key-Value |
表结构命名区别
| mysql | MongoDB |
|---|---|
| 数据库 | 数据库 |
| 表 | 集合 Colliection |
| 行 | 文档 Document |
| 列 | 字段 Field |
| 索引 | 索引 |
| MongoDB不支持表关联 | |
| 主键 | ObjectId |
MongoDB数据类型
MongoDB并不需要定义表结构字段,而是以BSON的形式在插入数据属性取并集,所为一张表(集合)的所有字段,过程是动态的。
MongoDB也是采取分片的形式(理想是均匀分布,设计类似HDFS里MapReduce:先map分发数据,计算完再reduce总合;实现方式类似于Redis集群里的hash槽,通过hash值把数据以较均衡的形式插入hash槽),并非所有数据都存储于同一台机器上。
应用场景
适用于:
MongoDB有非关系数据库的优势,也拥有部分关系型数据库的特点,它支持磁盘存储,但操作的索引数据则都是在内存中,所以性能优,很适合实时的插入更新。
2,对一些大尺寸、低价值(对一致性没那么严谨的数据来说),在关系型数据库存储过于昂贵(就例如网盘,上面存储的海量数据量,很适合具备高伸缩性、复制特性的Mongodb,当然mongodb也主要是存储文件索引,而不是实际好几G的文件)
3,MongoDB很适合由数十或百台服务器组成的数据库,mongodb路线图也包含对MapReduce引擎的内置支持。

安装与操作
国内官网下载很卡,建议用这个地址 http://dl.mongodb.org/dl/win32/x86_64
下载完解压,bin录用mongod就是数据库服务,mongo是客户端,mongos是路由
首先我们建立一个Data文件夹,用于存放数据,然后如下指定启动mongodb:
mongod.exe --dbpath=F:\devSoftware\mongodb\mongodb-win32-x86_64-2012plus-4.2.5-25-gd70b0b0\Data
客户端启动
mongo.exe --host=xxx.xxx.xxx.xxx --port=xxxxx
CURD基本法
//创建数据库和插入数据(mongodb创建数据库在插入数据之前,数据库是未提交生成的)
use mytestdb; //创建mytestdb数据库,此时不可见
db.t_student.insert({name:"小强",age:17}); //创建t_student表,并插入一条数据,插入后数据库和表才均可见
1)mongodb是ObjectID,所以id查询比较特别
db.ProcessDefinition.find({"_id": ObjectId("60f66f082073c4c34f04f93b")});
2)3.2以上不推荐使用insert()插入,而是insertOne() insertMany()
db.users.insertOne(
{
name: "sue",
age: 19,
status: "P"
}
)
db.users.insertMany(
[
{
_id: 1,
name: "sue",
age: 19,
type: 1,
status: "P",
favorites: { artist: "Picasso", food: "pizza" },
finished: [ 17, 3 ],
badges: [ "blue", "black" ],
points: [
{ points: 85, bonus: 20 },
{ points: 85, bonus: 10 }
]
},
{
_id: 2,
name: "bob",
age: 42,
type: 1,
status: "A",
favorites: { artist: "Miro", food: "meringue" },
finished: [ 11, 25 ],
badges: [ "green" ],
points: [
{ points: 85, bonus: 20 },
{ points: 64, bonus: 12 }
]
},
{
_id: 3,
name: "ahn",
age: 22,
type: 2,
status: "A",
favorites: { artist: "Cassatt", food: "cake" },
finished: [ 6 ],
badges: [ "blue", "Picasso" ],
points: [
{ points: 81, bonus: 8 },
{ points: 55, bonus: 20 }
]
}
]
)
3)其他查询
# and条件
db.users.find( { status: "A", age: { $lt: 30 } } )
db.users.find({$and:[{name:"sue"},{age:19}]}).explain();
# and 和 or条件
db.users.find(
{
status: { $in: [ "P", "D" ] },
$or: [ { age: { $lt: 30 } }, { type: 1 } ]
}
)
# 分页排序
db.users.find({age:{$lt:30}}).skip(0).limit(10).sort({"name":-1});
# 正则模糊匹配
db.users.find({name:/e/});
db.users.find({name:{$regex:"e"}});
db.users.find({name:{$regex:"^s"}});
4)update
# 根据artist更新一个匹配的数据
db.users.updateOne(
{ "artist": "Picasso" },
{
$set: { "favorites.food": "pie", type: 3 },
}
)
# 更新多个数据,{ upsert: true },它可以清晰的返回你修改后的值
db.inspectors.updateMany(
{ "Sector" : { $gt : 4 }, "inspector" : "R. Coltrane" },
{ $set: { "Patrolling" : false } },
{ upsert: true }
);
# 文档替换
db.users.replaceOne(
{ name: "abc" },
{ name: "amy", age: 34, type: 2, status: "P", favorites: { "artist": "Dali", food: "donuts" } }
)
5)delete
db.users.deleteOne( { status: "D" } )
db.users.deleteMany({status: "D"})
#删除所有文档
db.users.deleteMany({})
mongodb也支持类似js的写法。
6) js 实现循环操作

7.索引查询分析
# 查询分析
db.users.find({name:"sue"}).explain();
# 创建索引
db.users.createIndex({age:-1});
# 创建联合索引,注意mongo类似mysql也有覆盖索引一说,它索引使用B树
db.users.createIndex({name:1,age:-1});

document更新



条件查找
条件操作符

$type 操作符

查找所有name为字符串的数据。

索引

高可用主从集群
linux环境下集群部署,mongodb也是主从仲裁节点的套路,但默认情况,slave库只是一个备份,不允许读写(需要调用rs.slaveOk()函数后,才允许操作),但仲裁节点任何数据都不存储,也不参与操作比较鸡肋,建议更换为混合模式(不指定区分主从和仲裁,只把节点群放在同一个副本集里,让mongo自己选举产生不同角色)
专用术语
RouteServer(路由服务器)
ConfigServer(配置服务器)
Replica Set(副本集)
Shard(切片)
Chunk(分块)
集群部署图

部署架构图:客户端访问的是Route server集群,route server再去副本集(分片)里取数据【这一步是关键】,外搭config集群。
正式启动mongodb服务,需要的参数比较多,如果官方下载mongo没有自带默认配置文件,那需要自己创建一个mongodb.cfg文件,配置内容类似下图:
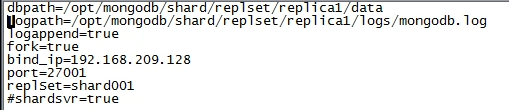
#fork 代表后台启动
#bind_ip 是绑定ip,避免自动绑定127.0.0.1,导致外部无法访问
#replSet 是集群组名称,集群里一致
#shardsvr=true 指定服务分片,否则不允许插入分片数据
启动完集群服务后,需要在“副本集服务”添加副本集关系,这里只说思路,不赘述指令

然后调用 rs.initiate(cfg); //初始化副本集
rs.status() 可以查看副本集状态
副本集不需要addShard的,addShard是在路由服务添加。
然后需要在路由服务,添加分片规则
sh.addShard(…)
对表testcon,根据name进行分片,整体数据根据计算的hash值,插入不同的hash槽里,数据分别插入副本集1(分片1)跟副本集2(分片2)里,只有从Route Server查询表testcon,出来的数据才是完整的,分片里查询只能查到自己存储的那部分。
配置完后,可以查看分片分块信息
use config;
db.shards.find();
db.chunks.find();
下面是分块信息:

不难看出上述情况自动分块的话,被分成了4个分块,区间分别为后面的分析结论。














 96
96











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









