







Redis 文档
Redis数据库内部结构
Redis中的每个数据库,都由一个redis.h/redisDb结构表示:
typedef struct redisDb{
int id; //保存着数据库以整数表示的号码
dict *dict;//保存着所有键值对数据,这个属性也被称为键空间(keyspace)
dict *expires; //保存着键的过期信息;
dict *blocking_keys; //实现列表阻塞原语,在列表类型一章有详细的讨论
dict *watched_keys; //用于实现WATCH命令
}redisDb因为Redis是一个键值对数据库(key-value pair database),所以它的数据库本身也是一个字典(俗称key space)
- 字典的键是一个字符串对象
- 字典的值则可以是包括字符串、列表、哈希表、集合或有序集在内的任意一种Redis类型对象。
Redis数据库内部结构
键法的书法约定
命令
Redis中的命令不区分大小写,SET与set效果是一样的。
主键(key)
可以用任何二进制序列作为key值,从形如“foo”的简单字符串到一个JPEG文件的内容都可以。空字符串也是有效key值。
关于key的规则
- 可以用任何二进制序列作为key值
- 格式约定:object-type:id:field
- 不用太长的键值。不仅消耗内容,而且在数据查找中计算成本很高。
- 太短的键值通常也不是好主意,可读性差。如用“user:1000:password”来代替”u:1000:pwd”
String数据类型简介
String类型介绍
String是Redis最基本的类型,而且String类型是二进制安全的。意思是Redis的String可以包含任何数据。比如jpg图片或者序列化的对象。从内部实现来看其实String可以看作byte数组,最大上限是1GB.下面是String类型的定义。
struct sdshdr{
long len; //len是buf数组的长度。
long free; //free是数组中剩余可用字节数。
char buf[]; //char数组用于存储实际的字符串内容
}String;
应用场景
String是最常用的一种数据类型,普通的key/value存储。
实现方式
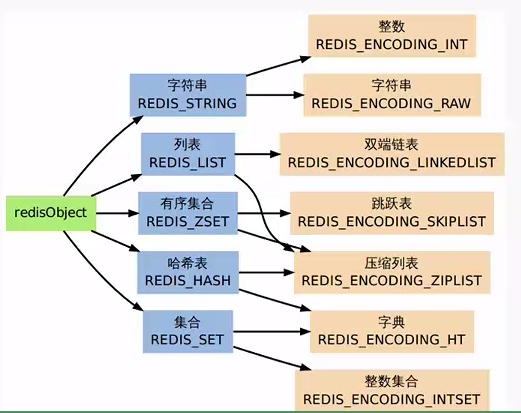
String在Redis内部存储默认就是一个字符串,被RedisObject所引用,当遇到incr,decr等操作时会转成数值型进行计算,此时RedisObject的encoding字段为int。
新增相关命令
Set
语法:set key value
解释:把值value赋给key,如果key不存在,新增;否则,更新。
Setnx
语法:setnx key value
解释:只insert不update,即,仅仅key不存在时,则设置key的值为value,并返回1,否则返回0。setnx是set if not exists的缩写。
Setex
语法:setex key seconds value
解释:设置key的过期时间和值。过期时间seconds单位是秒。设置过期时间和值是源自操作,如果redis仅仅当作缓存,这个命令很有用。
mset
语法:mset key value [key value…]
解释:同时设置多个key-value
msetnx
语法:msetnx key value[key value…]
解释:所有key都不存在才执行set操作。
查询相关命令
get
语法:get key
解释:获取key所set的值。
mget
语法:mget key[key…]
解释:批量获取key的值。程序一次获取多个值,可以减少网络连接损耗。
getrange
语法:getrange key start end
解释:获取存储在key中value的字串。字符串的截取由start和end决定,字符串的第一个字符编号是0,第二个是1,依次类推;如果是负数,-1是最后一个字符,-2是倒数第二个字符,依次类推。
getset
语法:getset key value
解释:设置key的值,并返回key的旧值
修改相关命令
append
语法:append key value
解释:key存在,在旧值的后面追加value;key不存在,直接set,返回长度。
setrange(替换部分字串)
语法:setrange key offset value
解释:用value重写key值的一部分,偏移量由offset指定。返回值为字符串长度
incr/decr
语法:incr/devr key
解释:key中如果存储的是数字,则可以通过incr递增key的值,返回递增后的值。
如果key不能存在,视为初始值为0.
incrby/decrby
语法:incrby key increment
解释:用指定的步长增加key存储的数字。如果步长increment是负数,则减。如果key不能存在,视为初始值为0
删除及其他命令
del
语法:del key[key]
解释:删除指定的key,返回删除key的个数。
strlen
语法:strlen key
解释:获取key中所存储值的长度。
场景案例
案例:博客系统的设计与开发
需求与实现
文章的访问量:定义post:articleID:pageView,通过INCR命令递增
自增ID:定义键article:count,通过INCR递增
存储文章的数据:伪代码如下
首先获得新文章的ID
$postID = INCR posts:count
将博客文章的诸多元素序列化成字符串
$serializedPost = serialize($title,$content,$author,$time)
把序列化后的字符串存入一个字符串类型的键中
SET post:$postID:data $serilizedPost
获取文章数据的伪代码
从Redis中读取文章的数据
$serializePost = GET post:42:data
将文章数据反序列化成文章的各个元素
$title,$content,$author,$time = unserialize($serializePost)
获取并递增文章的访问量
$count=INCR postL42:pageViewHash类型介绍
概念
Redis hash是一个String类型的field和value的映射表,一个key可对应多个field,一个field对应一个value。可以将Redis中Hash类型看成具有String Key和StringValue的map容器。将一个对象存储为Hash类型,较于每个字段都存储成String类型更能节省内存。没一个Hash可以存储2的32次方-1一个键值对
底层实现
Hash对应Value内部实际就是一个HashMap,实际这里会有2中不同实现,这个Hash的成员比较少时Redis为了节省内存会采用类似一维数组的方式来紧凑存储即zipmap(压缩列表),而不会采用真正的HashMap结构,对应的value redisObject的encoding为zipmap,当成员数量增大时会自动转成真正的HashMap,此时encoding为ht
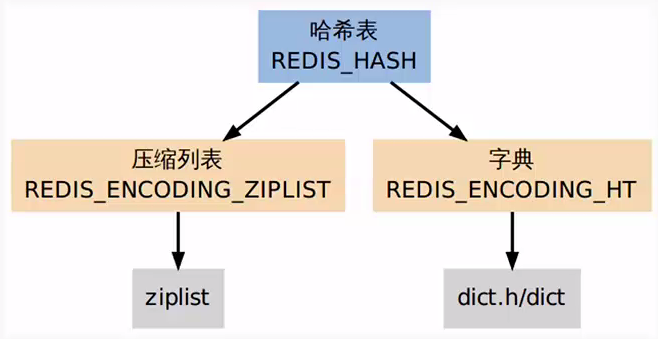
dict.h/dict给出了这个字典的定义:
Typedef struct dict{
dictType *type; //特定于类型的处理函数
void *privdate; //类型处理函数的私有数据
dictht ht[2]; //哈希表
int rehashidx; //纪录rehash进度的标志,值为-1表示rehash未进行
int iterators; //当前正在运作的安全迭代器数量
}dict;字典所使用的哈希表实现有dict.h/dictht类型定义:
typedef struct dictht{
dictEntry **table;//哈希表节点指针数组(俗称桶,bucket)
unsigned long size;//指针数组的大小
unsigned long sizemask; //指针数组的长度掩码,用于计算索引值
unsigned long used; //哈希表现有的节点数量
}dictht;















 890
890

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









