




 本文详细介绍了在大数据查询中,Impala如何利用Parquet的字典编码,特别是混合使用RLE和Bit-Packing的编码策略。着重讨论了字典解码过程,包括Bit-Packing解码算法和批量处理方法,以及UnpackValue函数的实现。
本文详细介绍了在大数据查询中,Impala如何利用Parquet的字典编码,特别是混合使用RLE和Bit-Packing的编码策略。着重讨论了字典解码过程,包括Bit-Packing解码算法和批量处理方法,以及UnpackValue函数的实现。
在Impala+Hive表的大数据查询实践中,Parquet是目前比较流行的列存文件格式,虽然文档上支持多种编码,但实际使用的只有普通编码和字典编码,且字典编码使用较多。Parquet的字典编码key使用的是混合了RLE(Run-length encoding,变长编码)和Bit-Packing的编码(RLE/Bit-Packing Hybrid),RLE编码时会先检测值重复出现了连续的多少次(run length),然后存储值和对应的重复次数,对于大量重复值的场景有较好的效果。

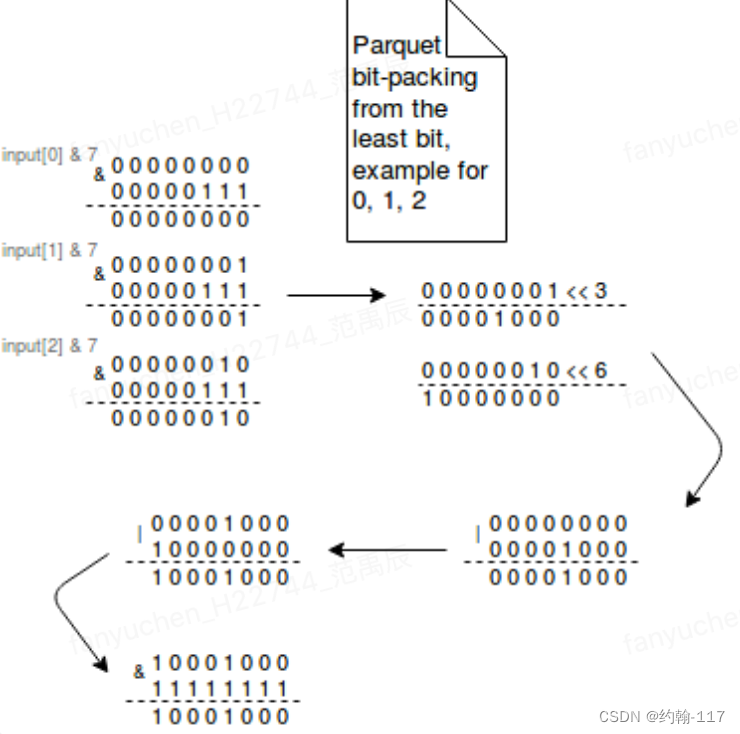
Bit-Packing编码的思想基于一个假设:一般使用int32或int64的值在大部分情况下用不到其类型支持的最大长度,因此只需要存储其有效长度就够了。在编码过程中,事先划分好一个指定位宽(BIT_WIDTH)的空间,将有效数据的二进制格式通过多次位运算按小端序打包到空间中,从最低有效位开始,每个位宽长度的二进制数据被称为一个有效值(Word),下图举例了位宽为3的情况下,打包0、1、2到一个8位二进制值的过程:
Impala对于Parquet文件的字典解码也是根据对应算法进行实现的,首先读取原始Parquet数据字典和打包过的值(字典key),然后先将key按Bit-Packing进行解码为有效key,再用有效key去数据字典进行检索,返回读取到的数据,其实现参考了开源的FrameOfReference算法,下面进行分析。
由于数据可能很长,Impala对于数据的解码和读取采用了batch的思路,每次读取的数据分为若干个batch,每个batch规定只包含32个有效值,剩余不足一个batch的数据则单独进行读取。单个batch中32个有效值的读取,通过重复执行以下代码实现:
#define DECODE_VALUE_CALL(ignore1, i, ignore2) \
{
\
uint32_t idx = UnpackValue<BIT_WIDTH, i, true>(in); \
uint8_t* out_pos = reinterpret_cast<uint8_t*>(out) + i * stride; \
DecodeValue(dict, dict_len, idx, reinterpret_cast 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 519
519

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









