







SIMD简介
向量化引擎的实现离不开SIMD的思路,Doris的许多代码部分都应用了基于SIMD的思想。举一个常见的乘法计算案例来说,以下两种计算方式的效率是有很大区别的:

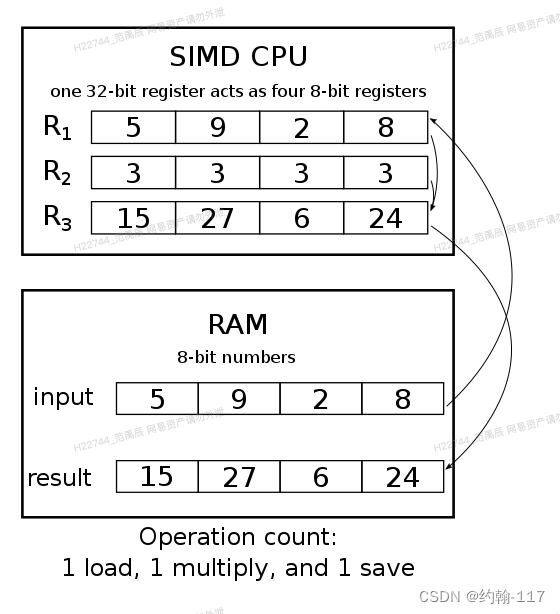
SIMD的CPU指令可以一次性执行多个传统CPU指令,优化了重复计算场景下的执行效率,但也有一定的前提条件:重复执行的输入输出不能有数据依赖,数据要进行内存对齐,可能会占用更多的寄存器空间。SIMD可以交给编译器去自动优化,也可以自行基于CPU指令集实现,当开启-O3编译时GCC就会自行进行向量化优化,但需要循环逻辑比较简单,不能有太复杂的逻辑。自行实现SIMD需要对各种CPU指令集有一定了解,Doris代码中就有一些自行实现的SIMD函数,如count 0或1、string大小写转换、消除string前后空格、数据过滤等等。
Doris SIMD实现分析
下面举例分析Doris中的SIMD相关优化实现。在读取字符串类型数据时,Doris会先进行解码,解码过程会每次读取一个Block的数据,并对其分配内存,内存大小是根据字符串大小进行对齐之后的结果,相关实现:
Status next_batch(size_t* n, ColumnBlockView* dst) override {
// ...一些前置检查...
// 取出数据,计算每个字符串的长度
Slice* out = reinterpret_cast<Slice*>(dst->data());
size_t mem_len[max_fetch];
for (size_t i = 0; i < max_fetch; i++, out++, _cur_idx++) {
*out = string_at_index(_cur_idx);
if constexpr (Type == OLAP_FIELD_TYPE_OBJECT) {
if (_options.need_check_bitmap) {
RETURN_IF_ERROR(BitmapTypeCode::validate(*(out->data)));
}
}
mem_len[i] = out->size;
}
// 计算大于每个字符串长度,且最接近的2的整数幂,此处使用SIMD优化
size_t mem_size = 0;
for (int i = 0; i < max_fetch; ++i) {
mem_len[i] = BitUtil::RoundUpToPowerOf2Int32(mem_len[i], MemPool::DEFAULT_ALIGNMENT);
mem_size += mem_len[i];
}
// ...清理临时变量,并分配对齐后的内存...
char* destination = (char*)dst->column_block()->pool()->allocate(mem_size);
for (int i = 0; i < max_fetch; ++i) {
out->relocate(destination);
destination += mem_len[i];
++out;
}
return Status::OK();
}
其中使用了SIMD优化改造的函数RoundUpToPowerOf2Int32,函数含义为将value向上取整,取到最接近且大于value的2的整数幂:
// GCC会自动对此函数进行向量化展开
static inline size_t RoundUpToPowerOf2Int32(size_t value, size_t factor) {
// factor是取整的基数,写死16,即返回的都是2^16、2^16^2、2^16^3;value是要进行取整的值
// 这里要先检查基数必须大于0,然后基数必须是2的整数幂,如16就是10000b & 1111b=0,符合条件
DCHECK((factor > 0) && ((factor & (factor - 1)) == 0));
// 表达式中,lhs为将取整值与基数-1后相加,rhs为基数-1后取反,表示rhs是基数的一个掩码,任何数与其相与 都会得到<=操作数的基数整倍数,且最接近操作数,lhs与rhs相与的结果就表示是最接近且<=lhs的基数整倍数,同时比value大。即无论value为多少,lhs&rhs的值都会介于value和value+factor-1之间
return (value + (factor - 1)) & ~(factor - 1);
}
这样实现的目的是能够让128位sse指令集同时进行4个int32类型数值的计算,即next_batch函数中分配内存的循环次数最少只需执行原来的1/4就可结束。这种设计在Doris代码中多次出现,虽没有vectorize的字眼,但也体现了向量化执行的思想。需要注意的是,Impala中也有这种设计,但Doris把Impala中的一些SIMD相关函数名进行了修改,函数体不变,因此也可以说是借用了一些Impala内核原有的设计:
Doris

Impala
以上是Doris中优化代码,以实现GCC自动向量化优化的案例,下面简要分析一个Doris自行实现的SIMD案例。
Doris中的大小写转换使用了基于SSE指令的SIMD实现,先放代码以供分析,这部分代码参考了ClickHouse的实现:
/// 参数中的src为待转换的字符串起始地址,src_end为结束地址,dst为目标指针
static void transfer(const uint8_t* src, const uint8_t* src_end, uint8_t* dst) {
/// 大小写转换掩码
const auto flip_case_mask = 'A' ^ 'a';
/// 支持SSE2指令集,使用SIMD实现
#if defined(__SSE2__) || defined(__aarch64__)
/// 取寄存器大小,128位即16个字符
const auto bytes_sse = sizeof(__m128i);
/// src_end-src取字符串总大小,与bytes_sse取余获得按寄存器大小划分字符串数组后剩余几位,最终与src_end相减得到的是,去掉剩余几位后,能够被128位寄存器存取整次数的下标位置
const auto src_end_sse = src_end - (src_end - src) % bytes_sse;
/// not_case_lower_bound和not_case_upper_bound是类实例化时传入的值,表示小写字母的上下界或大写字母的上下界'a'/'z'和'A'/'Z'。这里表示将'A'或'a'-1和'Z'或'z'+1的结果分别放到两个128位寄存器中,因为后面用到的_mm_cmpgt_epi8和_mm_cmplt_epi8的判断是大于或小于,不带等号
const auto v_not_case_lower_bound = _mm_set1_epi8(not_case_lower_bound - 1);
const auto v_not_case_upper_bound = _mm_set1_epi8(not_case_upper_bound + 1);
/// 将掩码放到一个128位寄存器中
const auto v_flip_case_mask = _mm_set1_epi8(flip_case_mask);
/// 每次取bytes_sse个字符,即16个,刚好128位可放到一个寄存器
for (; src < src_end_sse; src += bytes_sse, dst += bytes_sse) {
/// 加载src中的16个字符到寄存器
const auto chars = _mm_loadu_si128(reinterpret_cast<const __m128i*>(src));
/// _mm_cmpgt_epi8判断左操作数是否大于右操作数,_mm_cmplt_epi8反过来,_mm_and_si128对两个结果相与,即判断chars是否大于'A'或'a'同时小于'Z'或'z',is_not_case存储的是相与结果,表示16个字符中是否为大写或小写
const auto is_not_case = _mm_and_si128(_mm_cmpgt_epi8(chars, v_not_case_lower_bound),
_mm_cmplt_epi8(chars, v_not_case_upper_bound));
/// 大小写转换掩码与chars大小写判断结果相与,得到异或掩码,其中的1表示要进行大小写转换,0表示不转换,异或掩码与chars异或的结果就是全部转换为大写或小写的字符串,然后调用_mm_storeu_si128将其存入dst目标指针
const auto xor_mask = _mm_and_si128(v_flip_case_mask, is_not_case);
const auto cased_chars = _mm_xor_si128(chars, xor_mask);
_mm_storeu_si128(reinterpret_cast<__m128i*>(dst), cased_chars);
}
#endif
///不支持SSE2,退化为for循环逐个flip,同时也可以处理src_end_sse后面的剩余字符
}
这个大小写转换函数使用起来比较简单,实例化时传入<‘A’, ‘Z’>或<‘a’, ‘z’>表示要进行转换小写或大写,然后将字符串划分为两个部分:SSE寄存器大小的整数倍部分和剩余字符,使用src_end_sse进行标记,随后每次填充16个字符到128位的SSE寄存器中进行处理。以转小写为例,因为要调用_mm_cmpgt_epi8和_mm_cmplt_epi8来进行大于小于的比较(不带等号),所以v_not_case_lower_bound和v_not_case_upper_bound表示的分别是’A’的前一个字符和’Z’的后一个字符,两个函数通过chars是否处于’A’和’Z’之间来判断chars中的16个字符是否为需要进行转换的大写字符,结果相与后的判断码中1就是要进行转换,0不转换,随后和翻转掩码(‘a’ and 'A’的结果)相与,得到的是异或掩码,目的是过滤掉不需要转换的字符,最终异或掩码和chars进行异或运算,得到的就是转换为小写的字符,寄存器大小整数倍的字符转换完成后,用普通for循环继续逐个转换剩余字符。下图展示了以"Hello, World!"字符串为例的小写转换流程,其中简化为每次转换4个字符。
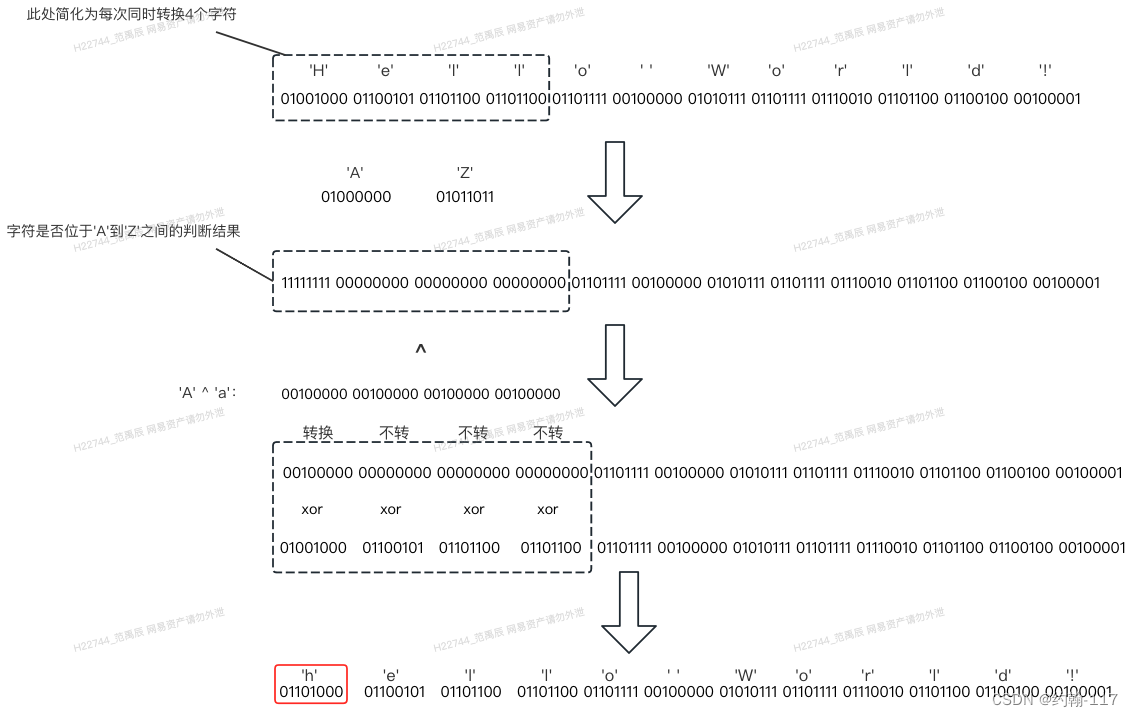
相比普通逐个转换,这种方式最大程度利用了SSE指令集和寄存器,假如字符串长度为1024,则仅需执行16次循环就可以完成大小写转换,每次同时转换最多16个字符。
总结
SIMD的相关实现在代码层面难度不大,但需要了解部分CPU指令集的依赖和相关调用,如果对NDH Impala进行向量化优化,相比于改动较大的RowBatch数据结构替换、聚合算子、Join算子等内核逻辑的改进,先通过CPU热点分析找到一些性能热点,再对热点相关的基础操作进行SIMD优化可能是比较容易进行的向量化改造,目前也有一些比较成熟的案例用于参考。















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









