







本学习笔记参考自Andrew的机器学习课程(点此打开), 内容来自视频以及其讲义, 部分内容引用网友的学习笔记,会特别注明
本集内容
1.事件模型
2.神经网络简单介绍
3.支持向量机(上)
事件模型
多值伯努利事件模型
在前面介绍的一个垃圾邮件分类的例子中,输入特征的分向量要么取0或1,即p(x|y)中的x是服从伯努利分布的,这样的朴素贝叶斯算法叫做多值伯努利事件模型
多项式事件模型
上面的垃圾邮件分类器的特征并没有完全描述邮件的性质,比如单词出现的次数,下面会改造一下。一般的,输入特征的分向量可能取值为1,2,3..k种,就不能用上面的处理方式了,这里对垃圾邮件分类器重新改变一下,来处理这种并非二元取值的情况,相应的模型叫做多项式事件模型,就是p(x|y)中的x服从多项式分布。输入特征重新如下输入特征如下:
(x 1 ,x 2 ,.x i..,x n )
i表示邮件中第i个单词,自然的n就是最后一个单词,也就是邮件的长度了,所以输入特征向量的维度根据样本而变化。其中x i的取值为1,2,3...|V|,|V|是词典的大小,不再是原来的0或1了,xi相当于单词在词典中的索引。这个输入特征的直观理解就是把邮件内容的每个单词用词典中的序号替代了。根据朴素贝叶斯算法以及前面介绍过的多项式分布,可以得到该模型的参数如下:
1. φ y = p(y)
2. φ i|y=1 = p(x j = i|y = 1)
3. φ i|y=0 = p(x j = i|y = 0)
为了获得参数,同样的最大化参数的似然性
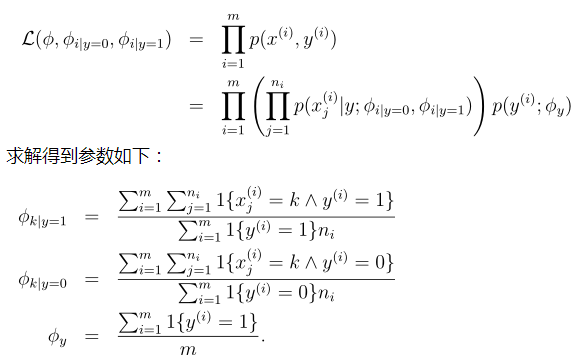
这里举一个例子,例子内容来自一个JerryLead的学习笔记,很详细,这里引用一下
![]()


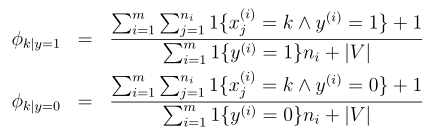
神经网络简单介绍
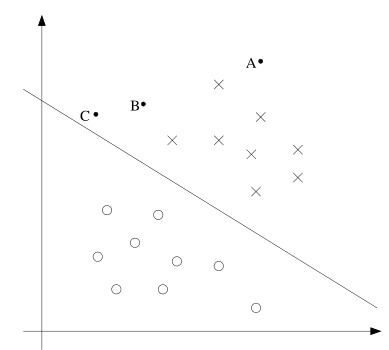
这里简单的介绍了一下神经网络,目的还是引出支持向量机。从逻辑回归开始,该模型实现分类是线性的,也就是能够用一条直线去分隔两个类别,如图:
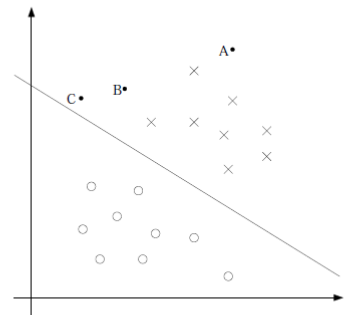
但是如果训练样本是这样的:
线性分类器就没有办法处理了,神经网络可以处理非线性分类问题,神经网络的基本单位可以表示如下:

支持向量机(SVM 上)
两种间隔(Margins)的直观理解
为了介绍函数间隔和几何间隔的概念,先对两种间隔直观的进行介绍。从逻辑回归举例,从逻辑函数中可以看到
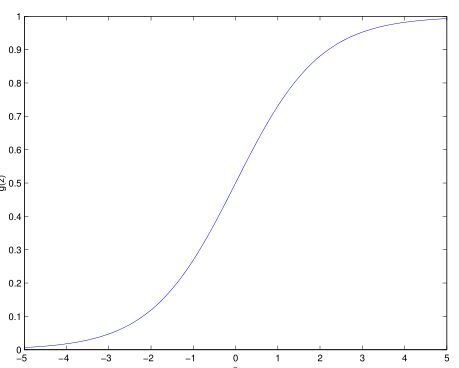
当 h θ (x) ≥ 0.5 即 θ T x ≥ 0 时 我们认为 y = 1,否则 y = 0
更加的,当 θ T x 远大于 0时,我们更有把我确定 y = 1,当 θ T x 远小于0时,我们更加有把握确定 y = 0。如果对于对训练集中的样本,我们都能够得到θ T x远大于0或者远小于0,那么该模型将表现的更好,因为我们可以预测的更有把握,在下面要介绍的函数间隔就回达到这样的目标。另外几何间隔的一种直观介绍如图:
一些新的符号
和原来不一样,需要定义一些新的符号,现在假设 y ∈ {−1,1} ,原来的逻辑函数变为:
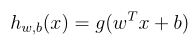
函数间隔和几何间隔
函数间隔的形式定义如下:
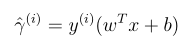
我们可以看到如果y = 1的话,w T x + b越大于0越好,这样我们更确信,此时整个式子也就越大。如果y = -1,w T x + b越小越好,即负的越大越好,这样我们对负例更有确信,这个时候式子的值还是越大越好,所以无论是针对正例还是负例,整个式子越大越好,也就是函数间隔代表着特征的输出是正例还是负例的确信度。但是如果光是直接增大w,b,函数间隔可以无穷大,这样并没有达到效果。所以必须对w,b进行约束限制,比如用||w|| = 1。注意这里||w|| 代表着w向量的长度,有时候会看到||w||2也是表示向量的模,更一般的表示:
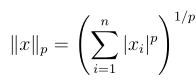
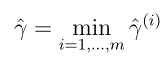

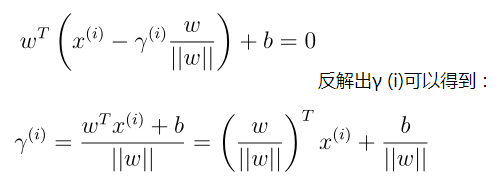
注意上面只是针对正样本来推导的,如果是负样本,最开始推导的法向量应该朝另一边,我们用如下统一:
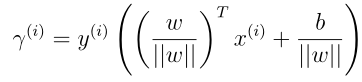
可以看到如果||w|| = 1, 则和函数间隔是一样的它们的关系是几何间隔 = 函数间隔/||w||,并且几何间隔是不会随w,b加倍而变化,可以这样理解,使w,b变换任意相同倍数,并不会使超平面wTx + b = 0有任何变换。另外这是针对某一个样本而言的几何间隔,针对整个训练集,如下定义几何间隔:
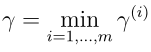















 1043
1043

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









