







本学习笔记参考自Andrew的机器学习课程(点此打开), 内容来自视频以及其讲义, 部分内容引用网友的学习笔记,会特别注明
本集内容
1. 核函数(kernels)
2. 软间隔(Soft Margin)
3. SMO算法
核函数
特征映射
首先在前面第三节内容中,有一个面积—房价关系的例子,如果只考虑面积一个特征,那么我们用线性规划得到的结果是一条直线,但事实上这条直线的表现是欠拟合的。更符合实际情况的或许是一个二次曲线,那么要从一个特征通过线性规划得到一个回归结果为二次曲线的话,我们需要对这一个特征x(x表示面积)映射到更高维的(x, x^2),这样去拟合就能得到二次曲线。这说明一个学习问题有时候为了得到更好的拟合效果,我们需要将原始特征映射到更高纬度上,原始特征称作问题的属性,映射后的向量才叫做特征。这举一个简单例子,x表示一个问题的属性,是一维的,用φ表示特征映射,映射得到三维特征向量:
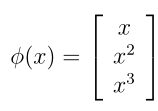
所以在上一节推导出来的对偶优化的结果需要把所有的x替换为φ(x),所有内积 <x,z>变成<φ(x),φ(z)>。事实上需要特征映射不只是为了更好的拟合模型,后面会介绍到很多原始问题是线性不可分的,但往往经过高纬映射后就线性可分了(即存在一个超平面能够把正负样本分开)。
核函数定义以及举例
为什么有核函数,是因为映射后的向量往往维度过高,甚至是无限维,计算效率非常低,引入核函数可以能够漂亮的解决高纬度向量内积计算效率问题。核函数定义如下:

也就是x和z的内积<x,z>可以替换为K(x, z)。核函数为什么能够高效率的解决高纬度向量内积?我们先看一个核函数的例子,假设:

把里面给展开得到:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 3014
3014











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









