







 该博客介绍了如何使用SVM对手写数字进行二分类,特别是将数字5与其他数字区分开来。首先,作者展示了在不进行数据预处理的情况下,直接使用朴素特征进行SVM分类的实验结果。接着,通过对数据的分析,特别是发现数字5的轮廓特征,作者进行了轮廓特征提取,并再次应用SVM分类。最后,探讨了使用GaussianRBF核函数时sigma参数的选择及其影响,得出相应的分类结论。
该博客介绍了如何使用SVM对手写数字进行二分类,特别是将数字5与其他数字区分开来。首先,作者展示了在不进行数据预处理的情况下,直接使用朴素特征进行SVM分类的实验结果。接着,通过对数据的分析,特别是发现数字5的轮廓特征,作者进行了轮廓特征提取,并再次应用SVM分类。最后,探讨了使用GaussianRBF核函数时sigma参数的选择及其影响,得出相应的分类结论。
SVM用于手写数字识别
要求:指定只用SVM二分类: 数字5 against all
数据来源:http://archive.ics.uci.edu/ml/
SVM 我就不描述了。可以去问一个叫百度的人。
首先,对于所给的数据先不进行任何数据处理:
直接使用朴素特征进行SVM分类。
使用python语言实现。调用sklearn中的SVM
核函数选择:“RBF”
参数gamma 为核函数RBF参数Sigma的倒数。
sklearn库文档说明gamma默认情况下函数自动选为维度的倒数
所以在实验中gamma选择从1到维度的2倍即512。
步长选为8.使得在能够得到64个数据点。
将数据集随机分成2部分,一部分作为测试集合,另一部分作为训练集。
训练集与测试集完全无交集。
为了防止随机误差。对每一步都测试10遍。最后结果取均值。
实验结果:
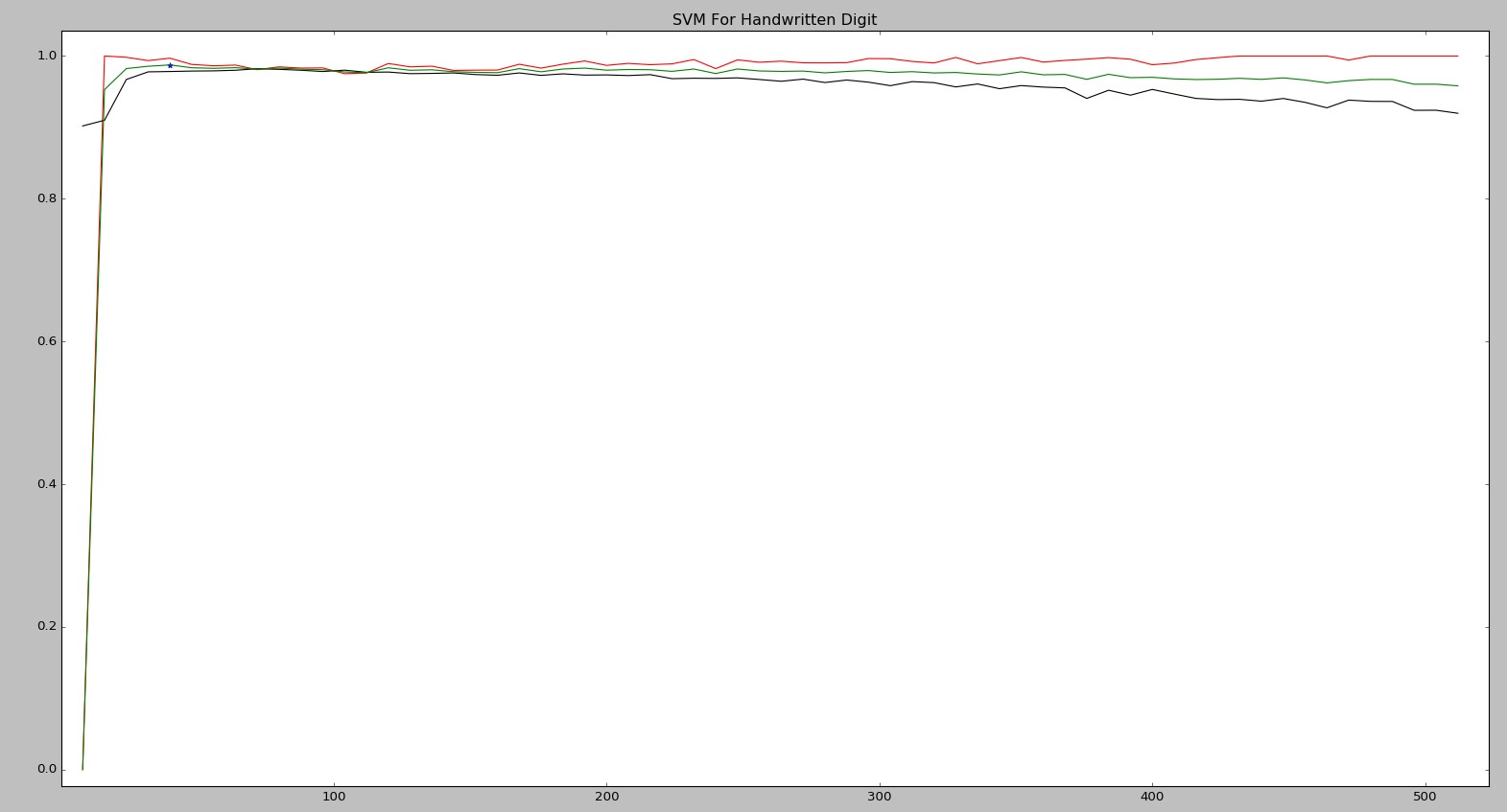
其中,
横坐标为sigma值,
纵坐标为比率,
红线为召回率,
黑线为准确率,
绿线为F值。
* 为F最大值:(40,0.987483)
结论:
可以看出。在对所给特征不做任何处理的情况下,对于SVM 核函数选用RBF ,参数sigma设为40.可得到极高的F1-Measure。 高达98.7483%。多次测试结果相对稳定。
现在考虑对其进行特征选取:
先对数据进行分析:
获取所有代表5的数据
取均值u = mean(img(tmp,:));
输出u:
各个像素点的深浅代表由均值决定。
在中间部分较浅。

对于其他数据:

可以看出,对于类5的数据,其存在大致的轮廓。所以现在考虑使用轮廓特征提取。
轮廓特征提取:
对于256维数据数据。。转成16*16矩阵。对矩阵每一行列,存储其第一个非零字符出现位置。这样对于每一个样本。可以将256维数据转成 64 维数据。
进行SVM分类。
同之前的操作
为了在2倍维度内得到64个点。设置步长为2.
得到结果:
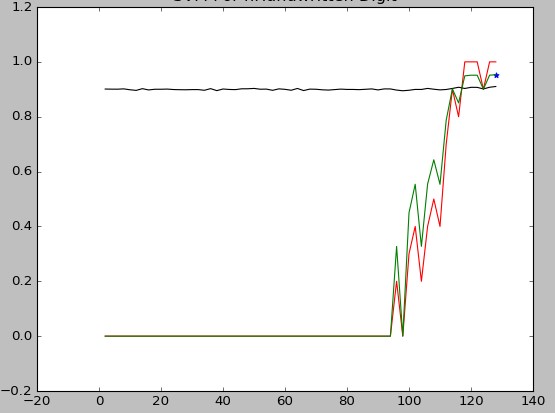
其中,
横坐标为sigma值,
纵坐标为比率,
红线为召回率,
黑线为准确率,
绿线为F值。
* 为F最大值:(128,0.952976)
结论:
可以看出sigma取点过于靠后。所以猜测在sigma取更大值时.可得到更高的F1-Measure。对于前面召回率持续为0,考虑可能是预测中将所有检测样本全部判错 = =。
重新进行SVM分类:
这次sigma参数选取范围为[0,4096] ,取64个点。4096为维度的平方。
4096这个值的选择是根据RBF核函数公式:
GaussianRBF
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 363
363

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









