








大家看到 hadoop-2.6.0-cdh5.15.1.tar.gz 压缩包 是400M有余
我们直接用hadoop fs -put 命令,把包存进HDFS文件系统。
我这边的版本 block size的默认大小 是128M
所以,就是这个文件会分为4个block.

用视图工具看了下,确实是分了4个Block.
然后我们 在 自定义的HDFS存放数据的根目录/dfs/data/current/BP-504131312-192.168.1.201-1587715632917/current/finalized/subdir0/subdir0 找到datanode 存放数据的地方
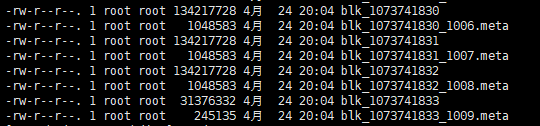
可以看到 4个 block 。 也就是说 HDFS把文件切割成 4个block,前三个block的大小都是一样的。
我们这里按顺序把4个文件拼接起来 用 cat blk_1073741830 >> demo.tar.zip 。 拼接完后,是可以解压的。如果不按顺序拼接,出来的接口是不能解压。
所以我们可以知道:HDFS文件系统存储的机制是将文件按顺序切割。















 355
355











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









