







一、前言
由于面试时被问到过这个问题,那么今天就从源码角度分析下是如何存储的?
二、数据在DataNode上是以什么样的形式存储的?
首先,我们可以通过在hdfs-site.xml中配置dfs.datanode.data.dir,来规定在哪些datanode服务器的哪些目录下存储数据
在我的服务器上,数据存储在/opt/module/hadoop-3.1.3/data目录下
Datanode保存的是文件划分的block块,以及这些block块的元数据
Datanode也可以定义多个目录保存数据块
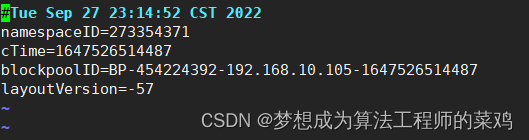
数据保存在/opt/module/hadoop-3.1.3/data/dfs/data/current/BP-454224392-192.168.10.105-1647526514487/current/目录下

- BP-454224392-192.168.10.105-1647526514487:这个目录是一个块池目录,块池目录保存了一个块池在当前存储目录下存储的所有数据块, 在Federation部署方式中, Datanode的一个存储目录会包含多个以“BP”开头的块池目录。 BP后面会紧跟一个唯一的随机块池ID, 在这个示例中就是451827885。 接下来的IP地址192.168.8.156是当前块池对应的Namenode的IP地址。 最后一个部分是这个块池的
创建时间。
- VERSION文件:和Namenode以及JournalNode的VERSION文件类似, 块池目录的VERSION文件同样包含了文件系统布局版本(layoutVersion) 、 HDFS集群ID(namespaceld) 以及创建时间(cTime),blockpoolID——块池ID, 这个字段的值与块池目录下保存的块池ID是一样的,等集群信息。
- finalized/rbw:finalized和rbw目录都是用于存储数据块的, 包括数据块文件以及对应的校验和文件。 rbw(replica being written, 正在写入副本) 目录保存了正在由HDFS客户端写入当前Datanode的数据块。 finalized目录包含了已经完成写入操作的数据块, 由于这样的数据块可能非常多, 所以finalized目录会以特定的目录结构存储这些数据块。每个数据块对应 2 个文件,blk 文件存放数据,另外一个以 meta 结尾的存放校验和等元数据。
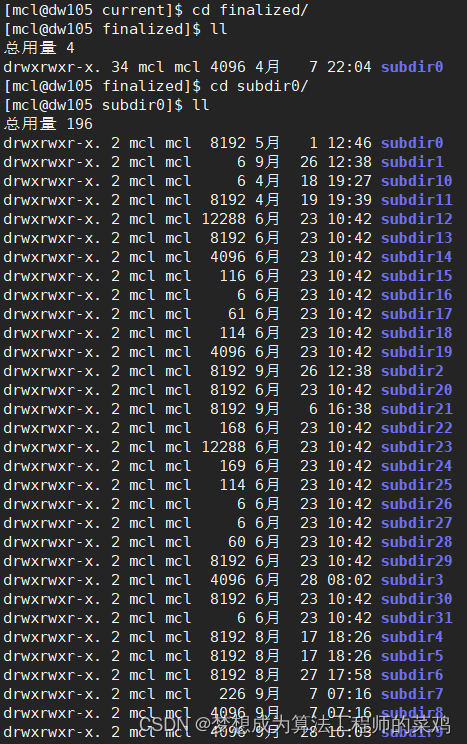

- finalized目录下的subdir0保存真正要存储的数据, 以多个文件夹区分.比如 subdir0 , subdir1 , subdir2 …
每个subdir[xxx]文件夹下默认有512个 , 两种类型的文件 blk_xxxxxxx 和 blk_xxxxxxx_xxxxx.meta两种格式的文件.
三、DataStorage实现
Datanode最重要的功能就是管理磁盘上存储的HDFS数据块
Datanode将这个管理功能切分成两个部分:
- ① 管理与组织磁盘存储目录(由hdfs-site.xml中的dfs.data.dir指定),如current、previous、detach、tmp等,这个功能由DataStorage类实现;
- ② 管理与组织数据块及其元数据文件,这个功能主要有FsDatasetImpl相关类实现















 512
512











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











