






 本文介绍了如何在异步环境中使用SQLAlchemyORM框架,包括定义数据表基类、创建异步数据库连接、使用Alembic进行数据库迁移以及异步配置示例。
本文介绍了如何在异步环境中使用SQLAlchemyORM框架,包括定义数据表基类、创建异步数据库连接、使用Alembic进行数据库迁移以及异步配置示例。
sqlalchemy是一个用于解耦数据库和业务代码的ORM框架,具体使用及介绍可参考
官网: https://www.sqlalchemy.org/
alembic同样由sqlalchemy的作者开发,用于简便地完成数据结构变化时的数据库迁移;
中文文档:https://hellowac.github.io/alembic-doc-zh/zh/_front_matter.html
大多对此ORM框架用法介绍均以常规使用,如sqlite、mysql直接读写等作为示例,此处不再赘述,以下是异步(async)场景下使用示例:
sqlalchemy异步使用
首先是定义数据表基类(Base),此类需要继承DeclarativeBase方法,且所有数据表都需要继承此类;
在异步环境下,数据表基类还需要额外继承AsyncAttrs这个类,完整代码如下:
import sqlalchemy
from sqlalchemy.orm import DeclarativeBase, mapped_column, Mapped
from sqlalchemy.ext.asyncio import AsyncAttrs
class Base(AsyncAttrs, DeclarativeBase): # 继承异步属性
metadata: sqlalchemy.MetaData = sqlalchemy.MetaData()
class User(Base):
id: Mapped[int] = mapped_column(primary_key=True, autoincrement="auto")
username: Mapped[str] = mapped_column(
sqlalchemy.String(length=64), nullable=False, unique=True
)
随后,创建数据库引擎、连接等操作都需要使用异步IO,如下示例:
from sqlalchemy.ext.asyncio import create_async_engine, AsyncSession, async_sessionmaker
from sqlalchemy.pool import AsyncAdaptedQueuePool
from .base import Base
class Database:
def __init__(self, url: str, pool_size: int = 10) -> None:
self.async_engine = create_async_engine(
url,
echo=True,
poolclass=AsyncAdaptedQueuePool,
pool_size=pool_size,
max_overflow=10
)
self.pool = self.async_engine.pool
self.async_session_maker = async_sessionmaker(self.async_engine, expire_on_commit=False, class_=AsyncSession)
def create_session(self):
return self.async_session_maker()
async def init(self):
async with self.async_engine.begin() as conn:
await conn.run_sync(Base.metadata.drop_all) # 清空数据库,勿在生产环境使用
await conn.run_sync(Base.metadata.create_all) # 创建所有数据表
创建数据库引擎连接时,需要注意使用异步引擎,以sqlite举例,不使用异步引擎时,数据库链接为sqlite:///test.db,使用异步数据库时,应当使用sqlite+aiosqlite:///test.db,对于mysql,可以使用aiomysql引擎,上述两种异步引擎均需通过pip命令进行安装后才能使用:
pip install aiosqlite
pip install aiomysql
安装完成后,运行方法如下所示:
import asyncio
from src.db.database import Database
db = Database('sqlite+aiosqlite:///test.db')
asyncio.run(db.init())
运行成功后,查看test.db数据库中已经按照User模型生成了数据表,则说明可以正常执行异步操作;
创建连接使用示例:
async def test():
session = db.create_session()
await session.execute(
sqlalchemy.insert(User).values(id="222222222222222",username="111111111")
) # 插入数据
await session.commit()
asyncio.run(test())
alembic异步配置
首先创建alembic环境,此处需要指定使用异步模板创建环境,如下命令:
alembic init --template async ./migrations
migration是存放alembic相关文件及版本控制脚本目录,可以自行定义;
–template参数可以指定的模板可以使用如下命令查看:
$ > alembic list_templates
Available templates:
async - Generic single-database configuration with an async dbapi.
generic - Generic single-database configuration.
multidb - Rudimentary multi-database configuration.
Templates are used via the 'init' command, e.g.:
alembic init --template generic ./scripts
运行成功后,会在当前目录下生成alembic.ini文件,需要在这个配置文件中设置好数据库链接,并指定使用异步引擎:
sqlalchemy.url = sqlite+aiosqlite:///test.db
随后,在指定存放alembic相关文件的migration目录下找到env.py文件,参考 文档说明 中对env.py文件说明进行修改;
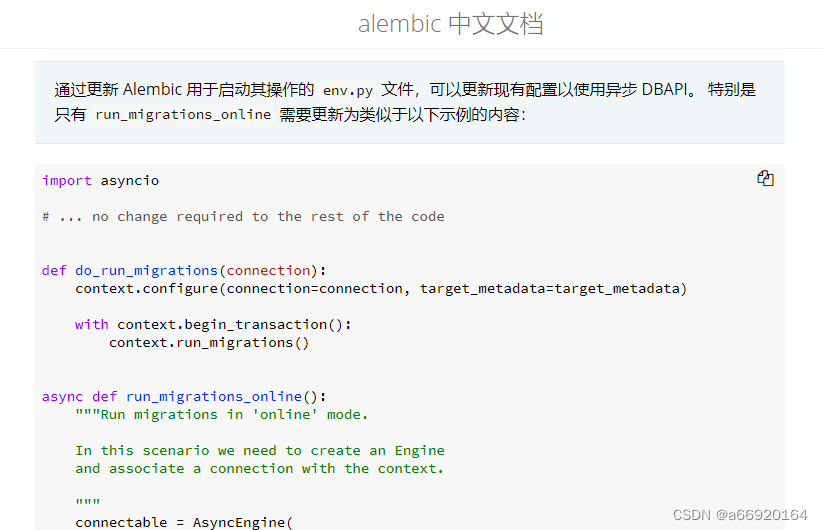
此处看代码可知,这个函数用于在数据表映射关系更新时执行更新相关操作,因此同样需要使用异步相关操作方法;
我的代码如下:
import asyncio
from alembic import context
from sqlalchemy.engine import Connection
from sqlalchemy.ext.asyncio import create_async_engine
config = context.config
target_metadata = Base.metadata
def do_run_migrations(connection):
context.configure(connection=connection, target_metadata=target_metadata)
with context.begin_transaction():
context.run_migrations()
def run_migrations_offline() -> None:
"""Run migrations in 'offline' mode.
This configures the context with just a URL
and not an Engine, though an Engine is acceptable
here as well. By skipping the Engine creation
we don't even need a DBAPI to be available.
Calls to context.execute() here emit the given string to the
script output.
"""
url = config.get_main_option("sqlalchemy.url")
context.configure(
url=url,
target_metadata=target_metadata,
literal_binds=True,
dialect_opts={"paramstyle": "named"},
)
with context.begin_transaction():
context.run_migrations()
async def run_migrations_online() -> None:
"""Run migrations in 'online' mode.
In this scenario we need to create an Engine
and associate a connection with the context.
"""
async_engine = create_async_engine(
config.get_main_option("sqlalchemy.url"),
echo=True,
)
async with async_engine.connect() as connection:
await connection.run_sync(do_run_migrations)
if context.is_offline_mode():
run_migrations_offline()
else:
asyncio.run(run_migrations_online())
修改好env.py后,执行如下命令更新数据表
alembic revision --autogenerate -m "create database"
alembic upgrade head
检查数据库中是否创建或更新对应数据表,若报错或未成功创建数据库,则应检查env.py中创建数据表函数是否存在异常;
若创建的数据库中只有一个alembic数据表,未创建定义的其他数据表,如下所示:
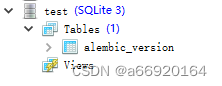
则应当检查env.py中是否导入了相关数据表,注意,sqlalchemy创建数据表是根据基表的元数据进行创建,但其他继承基表创建的数据表都需要在初始化过程中被import(各表模型分不同py文件存放的情况下),若未通过import导入相关数据表,则该表无法在global中找到,sqlalchemy创建数据表也就不会创建未导入的表模型;
简单来说,如果你的Base模型放在base.py文件,User模型放在user.py,env.py中定义:
from src.db.base import Base
target_metadata = Base.metadata # 虽然User模型继承Base,但此处未引入,不会创建User表
from src.db.base import Base
from src.db.user import User # 虽然未使用,但是必须引入
target_metadata = Base.metadata # 此时才会创建User表
此时,再执行更新数据表命令,应当能够看到数据库中创建了对应数据表;















 943
943

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









