







并发编程意义
移动互联网的发展导致用户访问量持续增加,由于受到制作工艺的限制,当今的微电子行业发展趋势已经不能再遵循摩尔定律,更快速的刷新CPU性能,作为一名程序猿,就会绞尽脑汁去榨干硬件计算资源,今天我们就来简单分析一下JDK的并发编程实现原理
JDK的并发包
jdk为方便开发者,引入了一套相对完善并发编程体系
java.util.concurrent ,其大致结构如下

这个图可以简单总结为以下结构模型

- Java并发包的最底层实现为内存可见变量voliate以及基于指针的Unsafe操作,相比于JVM级别的sychronized同步代码块,获取对象的monitor,并发包性能更强
- Java的CAS会使用现代处理器上提供的高效机器级别原子指令,这些原子指令以原子方式对内存执行读-改-写操作,这是在多处理器中实现同步的关键。
具体实现原理
自底向上分析,整个并发的体系借助于volatile与CAS操作
CAS原理:不同版本的JDK,其 UnSafe类的CAS实现方法略有不同,不同操作系统也有差异,这里不做讨论,只介绍对外的方法boolean CompareAndSet(val,expectVal):即对于一个内存地址,其原始值为A,要设置为B,设置成功返回true,设置失败返回false,当并发条件触发,另一个线程获取同一个资源时,原始值A可能已经被置为C,此时预期值B便不能设置成功
AtomicInteger实现:首先看一下原子变量的实现方式,在JDK1.8中
public final int getAndAddInt(Object o, long offset, int delta) {
int v;
do {
v = getIntVolatile(o, offset);
} while (!compareAndSwapInt(o, offset, v, v + delta));
return v;
}当我们执行increasementAdd的时候,该任务会不断自旋执行CAS操作,直到设置成功为止,即在不使用sychronized阻塞线程的情况下,高效的完成了原子操作;
- AbstractQueuedSynchronized(AQS)是并发包的第二个基础,有了这个同步队列,可以有效实现Lock,CountDownLatch等多线程任务,其结构如下
 对于资源的争抢,就要用上边的CAS操作,比如当添加一个元素进入队列,则
对于资源的争抢,就要用上边的CAS操作,比如当添加一个元素进入队列,则
private Node addWaiter(Node mode) {
//以给定模式构造结点。mode有两种:EXCLUSIVE(独占)和SHARED(共享)
Node node = new Node(Thread.currentThread(), mode);
//尝试快速方式直接放到队尾。
Node pred = tail;
if (pred != null) {
node.prev = pred;
if (compareAndSetTail(pred, node)) {
pred.next = node;
return node;
}
}
//上一步失败则通过enq入队。
enq(node);
return node;
}如此,按照CAS操作的方获取队列的位置,保证了队列线程安全性;
- ReentrantLock:当给我们CAS以及AQS这两柄利器之后,实现Lock就变得轻而易举了,先定一个锁的资源state,然后利用CAS的方式争抢,没有获取到的就放到AQS的队列末端,这就是现实了公平锁;
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}- CyclicBarrier是一个同步辅助类,它允许一组线程互相等待,直到所有线程都到达某个公共屏障点(也可以叫同步点),即相互等待的线程都完成调用await方法,所有被屏障拦截的线程才会继续运行await方法后面的程序。CyclicBarrier中定义的成员属性:
private final ReentrantLock lock = new ReentrantLock();
private final Condition trip = lock.newCondition();
private final int parties;
private final Runnable barrierCommand;
private Generation generation = new Generation();
private int count;其核心代码是 ReentrantLock 以及 Condition 的共享唤醒线程
多个线程竞争锁,保证计数器parties为原子操作,然后当parties执行为0时候,执行方法
//唤醒所有处于休眠状态的线程,恢复执行
//重置count值为parties
//重置中断状态为true
private void breakBarrier() {
generation.broken = true;
count = parties;
trip.signalAll();
}此时所有阻塞的线程继续执行
- 并发队列ConcurrentLinkedQueue
同样是利用CAS操作来进行入队操作,关键代码:
public boolean offer(E e) {
checkNotNull(e);
//创建入队节点
final Node<E> newNode = new Node<E>(e);
//t为tail节点,p为尾节点,默认相等,采用失败即重试的方式,直到入队成功
for (Node<E> t = tail, p = t;;) {
//获得p的下一个节点
Node<E> q = p.next;
// 如果下一个节点是null,也就是p节点就是尾节点
if (q == null) {
//将入队节点newNode设置为当前队列尾节点p的next节点
if (p.casNext(null, newNode)) {
//判断tail节点是不是尾节点,也可以理解为如果插入结点后tail节点和p节点距离达到两个结点
if (p != t)
//如果tail不是尾节点则将入队节点设置为tail。
// 如果失败了,那么说明有其他线程已经把tail移动过
casTail(t, newNode);
return true;
}
}
// 如果p节点等于p的next节点,则说明p节点和q节点都为空,表示队列刚初始化,所以返回 head节点
else if (p == q)
p = (t != (t = tail)) ? t : head;
else
//p有next节点,表示p的next节点是尾节点,则需要重新更新p后将它指向next节点
p = (p != t && t != (t = tail)) ? t : q;
}
}在如队列的时候利用无所操作控制插入队列操作的原子性
插入过程如图
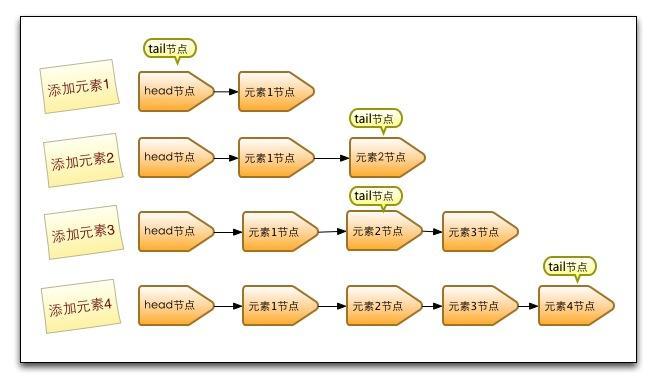
- CopyOnWriteArrayList是高效的可读可写容器,利用不变性设计模式,将array定义为final类型,只能被替换,不能被更改
关键属性
private volatile transient Object[] array;//底层数据结构
/**
* 获取array
*/
final Object[] getArray() {
return array;
}
/**
* 设置Object[]
*/
final void setArray(Object[] a) {
array = a;
}
/**
* 创建一个CopyOnWriteArrayList
* 注意:创建了一个0个元素的数组
*/
public CopyOnWriteArrayList() {
setArray(new Object[0]);
}list.add()操作利用锁控制原子性
/**
* 在数组末尾添加元素
* 1)获取锁
* 2)上锁
* 3)获取旧数组及其长度
* 4)创建新数组,容量为旧数组长度+1,将旧数组拷贝到新数组
* 5)将要增加的元素加入到新数组的末尾,设置全局array为新数组
*/
public boolean add(E e) {
final ReentrantLock lock = this.lock;//这里为什么不直接用this.lock(即类中已经初始化好的锁)去上锁
lock.lock();//上锁
try {
Object[] elements = getArray();//获取当前的数组
int len = elements.length;//获取当前数组元素
/*
* Arrays.copyOf(elements, len + 1)的大致执行流程:
* 1)创建新数组,容量为len+1,
* 2)将旧数组elements拷贝到新数组,
* 3)返回新数组
*/
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;//新数组的末尾元素设成e
setArray(newElements);//设置全局array为新数组
return true;
} finally {
lock.unlock();//解锁
}
}- 研究过HashMap原理的同学一定都知道在多线程同时对一个map做put与get操作,当hashmap恰好发生hashrefresh,会导致循环链表的产生,从而是CPU使用率飙升到100%;使用ConcurrentHashMap可以更好的解决多线程下的map读写
首先是currentHashMap的初始化,一段非常优雅的让出多线程资源的代码
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
//如果一个线程发现sizeCtl<0,意味着另外的线程执行CAS操作成功,当前线程只需要让出cpu时间片
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
break;
}
}
return tab;
}多线程初始化map,如果CAS成功则开始初始化,否则线程让出时间片
对于实现线程安全性,JDK1.7的做法是针对多个hash slot 分为一个Segment,每次为某个Segment加锁,其实此时锁住了多个hash slot,在JDK1.8中,其实现方式改为CAS+sychronized的方案,此时的sychronized只是单纯锁定一个hash slot,由于hash的负载率通常为0.75,故在并发性能上,JDK1.8有了很大的提升;
put操作代码
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
...省略部分代码
}
addCount(1L, binCount);
return null;
}以上是对JDK并发类实现原理的一些简要分析,对于更多的实现方案感兴趣的同学还可以深入研究















 265
265

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









