






spark内存分析模型(<=1.5版本)-无原文版本
背景
分析spark的内存模型,文章来源于
https://0x0fff.com/spark-architecture/
这里为了阅读流畅,把原文英文去除了,大家有疑问可以对照查看。
正文
分布式系统架构
由Alexey Grishchenko编写
spark架构
在此文章中讲述的内存模型在spark1.6++后的版本中不再使用,新模型使用UnifiedMemoryManager类实现,在https://0x0fff.com/spark-memory-management/文中中我进行了相应的描述。
最近我在StackOverflow上回复了关于spark架构的一系列问题,这些促使我在网上写一篇介绍spark架构的文章。这些内容官方文档、相关的书籍或者网站都没有,或许他们恰好缺乏一些好的图片描述spark架构。
在这篇文章中,我将好好去解决这些问题,提供一个非官方的spark架构指南并解答这方面的普遍的一些问题及疑惑。这篇文章不针对于新手,看这篇文章需要一些RDD DAG方面的知识。
本篇文章是spark系列的第一篇文章,本系列第二篇文章是关于的spark shuffle的,第三篇文章是关于spark新的内存模型的。
好啦,让我们从下面的图片开始吧(http://spark.apache.org/docs/1.3.0/cluster-overview.html)

如图所见,这图中同时展示了”executor”, “task”, “cache”, “Worker Node” …,我之前学习spark的时候,这是关于spark架构唯一的图片,当然现在也差不多。我个人不喜欢这图,因为它并没有用更好的方式来展示这些重要的概念。
让我们从头开始,任何运行在集群或者本地机器上的spark进程都是JVM进程。作为JVM进程,你就可以用”-Xmx and -Xms flags of the JVM”配置堆内存大小。但是进程如何使用配置的堆内存及为什么需要那么大小的内存?下面有个spark内存结构图:

Spark默认为512M的堆内存大小.为了安全考虑和防止出现 法力耗尽(OOM),错了,是内存溢出的错误,所以spark允许只利用整个堆内存的90%的内存大小,这部分这里称为”安全堆内存”(safe heap),这个可以通过配置置”spark.storage.safetyFraction”参数修改。
因为效率高的spark是基于内存的,spark在内存中会存储数据。但是如果你读过 h-t-t-p-s://0x0fff.com/spark-misconceptions/ 这篇文章,你应该了解到spark不仅仅是是基于内存的,它只是利用了它的LRU缓存(http://en.wikipedia.org/wiki/Cache_algorithms)的内存。所以有一些内存被用来缓存运行过程的数据,这部分一般占到”安全堆内存”的60%,可以通过配置”spark.storage.memoryFraction”参数来控制该比例。
所以如果你想知道你可以在spark中存储多少数据,你应该把所有的executors的堆内存总量*safetyFraction参数配置*memoryFraction参数配置,默认的话就是:所有的executors的堆内存总量*0.9*0.6=所有的executors的堆内存总量*54%.
上面讲的是存储storage的内存占用,shuffle的内存占用类似,他是”Heap Size”* spark.shuffle.safetyFraction(默认0.8) * spark.shuffle.memoryFraction(默认0.2)=”Heap Size”*16%
,所以shuffle占用16%左右堆内存资源。
你可以在(https://github.com/apache/spark/blob/branch-1.3/core/src/main/scala/org/apache/spark/shuffle/ShuffleMemoryManager.scala) 了解到spark是如何使用这些内存的,不过他们通常来说用于shuffle操作。
当shuffle运行的时候,你通常需要排序数据,所以你需要一个缓存区来存储排序过的数据(记住,你不能在LRU缓存中修改原来的数据,因为他们后面还会再使用)。所以你需要一定量的内存来存储这些大块的排序后的数据。
如果没有足够的内存来排序数据会发生什么?会有一个很大的计算范围指向”额外排序区”,这能够使你一块接一块进行排序,最后才会合并结果。
最后一部分内存,我们称为”展开内存”。这一部分的内存可以使用”整个内存 * spark.storage.unrollFraction(默认0.2) * spark.storage.memoryFraction(默认0.6) * spark.storage.safetyFraction(默认0.9) ” = 即”堆内存总量的10.8%”。这一部分内存是用于展开数据使用的。为什么你总需要这一部分内存配置呢?因为spark允许你以序列化和反序列号的方式来存储数据,序列化的数据不能直接使用,所以你需要这部分内存来进行反序列化数据。因为这部分内存是共享的,所以如果被占用了,在你展开数据的时候,内存不够的时候,它可能会扔掉一些在Spark LRU缓存中的partitions来空出一些内存。
好了,现在你应该知道spark的进程了,并且知道她们是如何利用内存了。现在我们看看集群模式,当你开启一个spark集群,内存占用是什么样子的呢?我喜欢Yarn这个资源管理器,我将会讲述一些在Yarn中,她们是如何工作,一般情况下,其他集群上也是类似的,这里以Yarn为例:
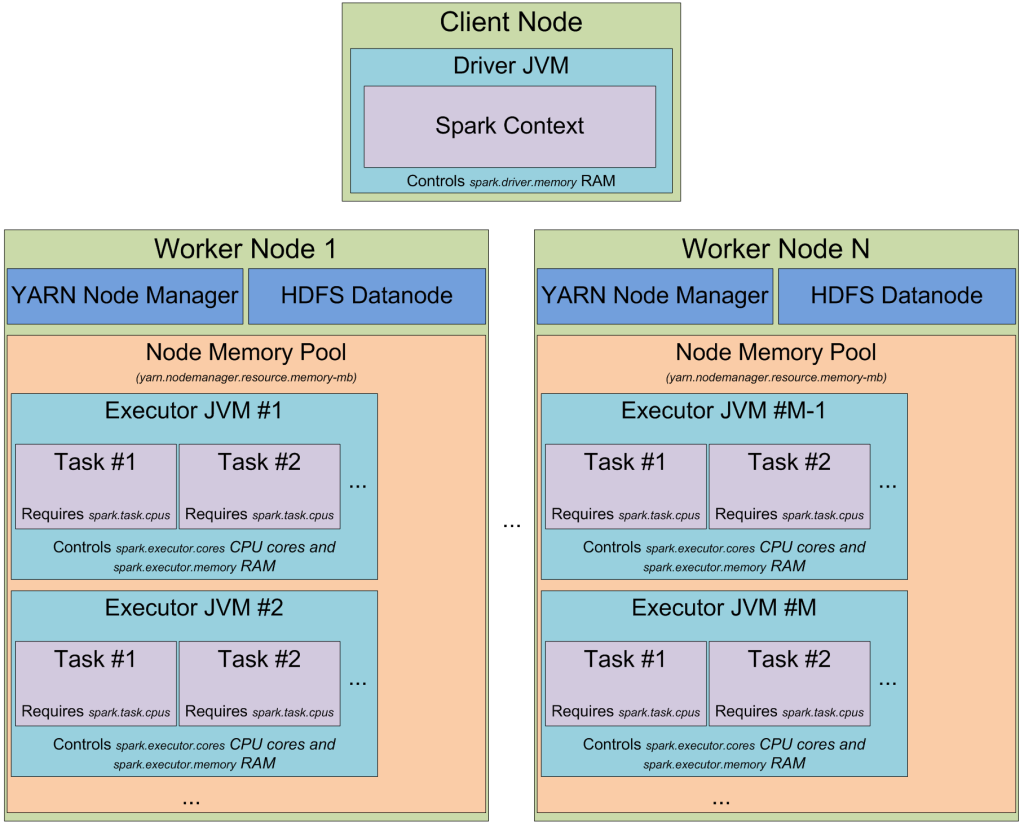
在yarn集群上,有一个yarn资源管理的守护进程来控制集群资源(基本上是内存),还有一些运行在集群节点上的yarn节点管理器,它们控制节点资源利用。从yarn角度来看,每一个节点控制着一个内存池。当你向yarn资源管理器申请资源的时候,它经过分析会提供你可以运行executor容器的节点管理器的相关信息。每一个executor容器就是一个含堆内存大小的JVM。JVM的选择由yarn资源管理器控制,你无法控制它选择哪一个。例如:如果一个节点有64G内存(在 yarn-site.xml配置yarn.nodemanager.resource.memory-mb参数),这时候你需要10个4G的executors,那样的话,即使你有一个大集群,但是你需要的这些也可以在单节点的yarn节点轻松启动运行起来。
当你基于yarn启动spark集群,你指定了你
需要的executors个数(–num-executors flag or spark.executor.instances 参数),
每一个executor需要的内存(–executor-memory flag or spark.executor.memory 参数),
每一个executor需要的cpu core(–executor-cores flag of spark.executor.cores parameter),
每一个task任务执行所需的cpu core (spark.task.cpus 参数)。
你也指定了driver application的所需内存(–driver-memory flag or spark.driver.memory 参数)。
当你在集群上执行Job的时候,你的任务将会被切分成很多stages,每一个stage会切分成很多的tasks,每一个task被分开有计划地执行。
(上述是任务切分,下面是偏重spark组件(译者添加))
你可以认为每一个executors上的JVMs,是一些”task执行槽”组成的池。每一个executor将会为你的tasks提供一定数量的”执行槽” with a total of spark.executor.instances executors.,这数量是: “参数 spark.executor.cores / 参数 spark.task.cpus” 得到的。
举个例子:
spark在yarn资源管理器上有12个节点,每个节点64G的内存,32个cpu core(16个物理cpu core线程虚拟出),这样,在供给系统、yarn、hdfs运行所需内存外,每个节点上可以运行两个executor,每个可以用26G的内存和12个cpu core。
总体上,你的集群将有12台机器,每台2个executor,集群一共12*2的executors,每个executor有12个cpu cores,1个task一个1 core,那么一共有任务槽数量:12*2*12=288个。
这意味着你的spark集群,将能够平行运行288个任务,这样就充分利用了你的集群资源。
你可以用于存储数据的内存数量:0.9 spark.storage.safetyFraction * 0.6 spark.storage.memoryFraction * 12 机器 * 每台机器 2 executors * 每个executor 可以用 26 GB = 336.96 GB.它并不多,但在大多数情况下是足够的。
到此,你知道了spark是怎么使用JVM内存的,并且知道了在你的集群中有多少”执行槽”。你可能注意到了,”task”到底是什么东东,我没有很深入的讲解,我将在下一篇文章中作为主题来讲,他一般作为一个独立的spark工作单元,并且是作为executor JVM中的一个线程来运行的。这是spark启动任务时间短的一个秘密,在JVM中,使用额外的线程分支比启动整个JVM要快的多,当你在启动hadoop中的mapreduce的时候就是启动整个JVM,所以在spark中启动job要比在mapreduce中启动要快。
现在让我们看看在spark中的另一个抽象的概念”partition”,你在spark中的工作数据全部会分成partitions。一个单独的partition到底是什么,它是怎么被分配出来的?
partition的大小完全取决于你使用的数据源。对于大部分的spark读取数据的方法,你都可以确定出RDD有的partitions数量。当你从HDFS中读取文件的时候,你这时候使用Hadoop的InputFormat。(通过查看spark源码可以知道—译者添)InputFormat返回的每一个input split形成了RDD的独立的partition。
在HDFS中的每一个input split都是在HDFS中生成的单独的数据block,一般大小约为64M(hadoop1.x默认配置)或者128M(hadoop2.x默认配置)。为什么说是”大约”,因为虽然在HDFS是以字节大小区分block大小的,但是在运行中,它是以数据记录来分割block边界的。对于文本文件,分割字符在新的一行的开始,对于sequence文件,分割点为block…
对于压缩文件,规则比较特殊,如果你压缩了整个文本,它就不能分割为记录,整个文件将变成一个单独的input split,后面将会在spark中形成单独的一个partition,所以你必须手工来repartition。
现在我们所知的很简单(作者说的),产生一个单独的partition作为spark的数据,然后形成一个task,然后这个task会在一个task槽上被执行,这个task槽挨着你的数据很近(hadoop的block位置,spark缓存的partition位置)。
其实其中的相关的东西远远比本篇文章中要多,在下篇文章中,我将讲述spark是怎么切分stages,把stage切分成task的,spark在集群中是怎么shuffle数据的,还有其他一些有用的东东…
这是本系列的第一篇文章,第二篇是关于shuffle,第三篇是关于spark在版本1.6+的新的内存管理模型…
讨论区有用的翻译:
Raja:
好的研究,我感觉尽管使用LRU缓存,足够的内存和节点将会保存(不懂—译者)。我认为整合Tachyon将会更好,消除重复内存数据,还有很多其他特性,比如速度提升、分享、安全,这是我的看法。
作者:
当然,如果你整合tacyon,会更快一些:因为更多的数据在linux cache中缓存了,更多的数据加载到spark的内存中了。但是一般来说,tacyon可以提升持久化数据方面的IO,但是spark的瓶颈不在这里,在写shuffle数据到本地文件系统中
关于你说的去除重复数据,我不太明白,你可以在spark或者持久化到HDFS、HBase、Cassandra, Tachyon…,取决于你和持久化级别,不能帮助你去重。
firemonk9:
spark.shuffle.memoryfraction 在堆内存的老生代中存储空间吗 (像 spark.storage.memoryfraction) ?
作者:
它取决于你JVM设置,spark不能控制内存位于新生代或者老生代中。在整个shuffle阶段,内存像一个连续的Longs数组(128M的大块,请查看see https://github.com/apache/spark/blob/branch-1.4/core/src/main/scala/org/apache/spark/shuffle/ShuffleMemoryManager.scala through https://github.com/apache/spark/blob/branch-1.4/core/src/main/java/org/apache/spark/shuffle/unsafe/UnsafeShuffleExternalSorter.java and https://github.com/apache/spark/blob/branch-1.4/unsafe/src/main/java/org/apache/spark/unsafe/memory/HeapMemoryAllocator.java),它取决于JVM来决定将它放到新生代或者直接定位到老生代。
Aniruddh Sharma:
我有一些疑问。Executor JVM运行这些task需要运行多少线程?谁来运行怎么来运行?这个”executor-cores”参数在决定多少线程的时候也会产生作用吗?线程的个数被core的数量决定吗?怎么决定的?
(文章中提过一个executor只运行了一个task,有读者提出这个数量怎么来确定—-译者添)
对于线程的数量,它是看情况的。例如:一个集群运行30个线程,一个executor运行一个task(spark.executor.cores=1)。当然只有一个task线程,其他的都是附加的。task线程是由executor sheduler在executor中启动的,这是被driver的scheduler允许的。
在每个executor JVM中执行的task线程数量是可以被”spark.executor.cores”参数设定的,这个名字有点歧义,实际上它跟cores数量没关系,仅仅设置用户任务进程的线程数量。它取这样的名字,因为它设置的数量和executor分配的cpu cores数量相等的话,这是一种最佳实践。task executor的线程数量和机器的cpu cores无关,你可以设置spark.executor.cores为10,这样你就在1个cpu core的executor中运行了10个线程
因为executor core一般虚拟为一个线程不是一个真实的core,我想我怎么让一个task分配一个1个core?
作者:
当yarn来控制执行的情况,在最新版本中的yarn(Apache Hadoop 2.7.2)中,它使用CGroups来控制executors的CPU,来确保excutors不会过多提交CPU资源,多于他们自身所需要的。
(https://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/NodeManagerCgroups.html)没有办法做到task定制–它完全取决于task做什么,怎么做。你可以在你的方法中产生一定数量的线程,它将作为单独的一个task,这样执行将会影响到其他
同一个executor中的其他task.
这是一系列spark的好文章,还有很多作者好的回复,后续的文章我会继续翻译,共同学习共同进步,这里感谢前辈yasaka老师的推荐。转载本篇翻译,请带本文链接—-Boyka1988。















 835
835

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}