







 教你实现一个堆
教你实现一个堆
堆的概念
堆总是一个完全二叉树。
大堆:树中一个树及子树中,任何一个父亲都大于等于孩子。
小堆:树中一个树及子树中,任何一个父亲都小于等于孩子。
大堆
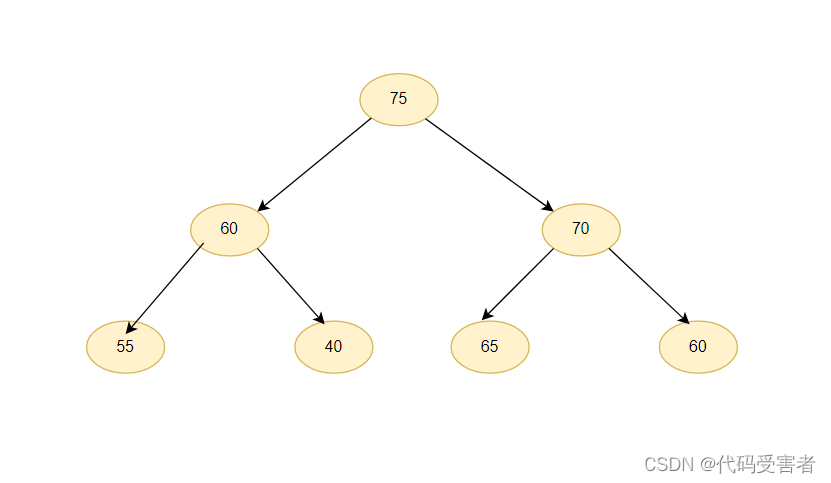
我们可以看到 75比 60 和 70 大, 60 比 55 和 40 大,也就是树中任何一个父亲都大于或等于孩子,所以这是一个大堆。
小堆
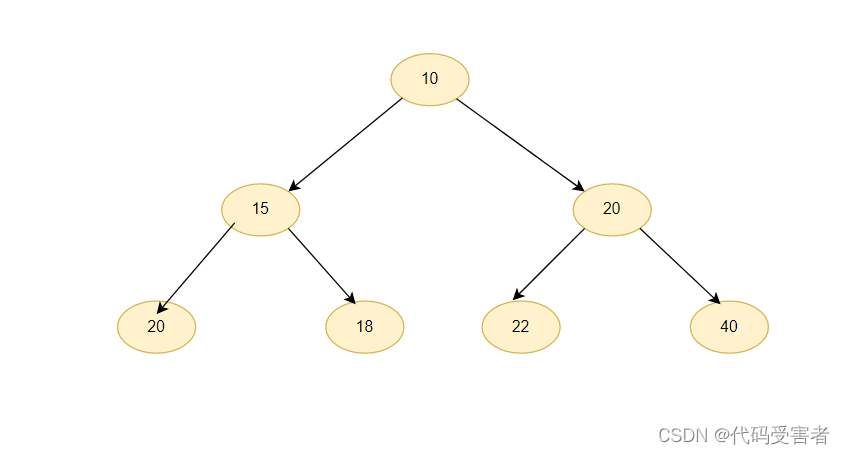
而任何一个父亲都小于或等于孩子,这就是小堆。那么接下来我们来实现一个大堆。
堆的结构声明
那么我们用什么结构来实现堆呢?用链表和数组都可以,但是数组比较方便查找,所以我们这里用数组来实现一个堆。

所以堆的结构类似于我们的顺序表。
typedef int HeapDataType;
typedef struct Heap
{
HeapDataType* data;
size_t sz;
size_t Cacpcity;
}HP;
堆的初始化
让data指向空,数组长度和容量置为0
void HeapInit(HP* hp)
{
hp->data = NULL;
hp->sz = hp->Cacpcity = 0;
}
插入数据
因为有大堆和小堆的区分,所以数据的插入也会有所差异。因此我们这里实现大堆,那么就要保证树中父亲必须大于等于孩子。
那么再插入的时候,我们必须让孩子和它的父亲比较。
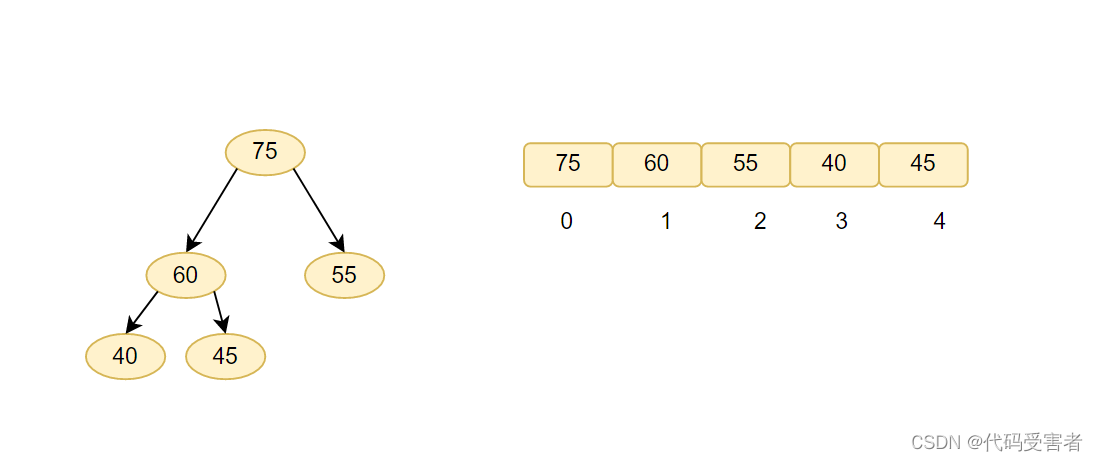
如图我们可以发现, 40 和 45的下标为 3 , 4 ,它们父亲 60的下标为1。
那我们可以总结出一个公式,父亲的下标 = (孩子的下标-1) / 2。
比如 60的下标是 1 , 40的下标是 3 , 那么 (3-1)/2 = 1, 比如 55的下标是2, 75的下标是 0 , ( 2 - 1 ) / 2 = 0。
而我们插入的时候,必须要和父亲比较,在大堆的情况下,孩子是不可能比父亲大的。
比如我要在 55的下面插入一个 80

我们称这个过程为向上调整。
//检查容量
void CheckCacpcity(HP* hp)
{
if (hp->Cacpcity == hp->sz)
{
//扩容
size_t newCacpcity = hp->Cacpcity == 0 ? 4 : 2 * hp->Cacpcity;
//扩容
HP* newhp = realloc(hp->data, sizeof(HeapDataType) * 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1965
1965











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









