







暂且把文章类型设为“原创”了,如果Mikolov看到的话,还望勿怪。毕竟代码都是别人写的,自己只是往上面加了一些注释,所以,如有什么问题,还请及时通知我改为更合适的选项!
好了,话入正题!
其实,distance的主要功能是计算两个词(组)之间的距离(相似度)。程序将该功能表现为用户输入一条字符串,里面可以包含以空格分割的多个词,然后程序从训练出的模型(demo-word.sh训练出的模型文件名为vectors.bin,二进制文件)中与之最为相似的40个词并输出。以下是添加了注释的源代码,为了与原有代码保持对齐,所有注释均放在代码行后,未另起新行:
// Copyright 2013 Google Inc. All Rights Reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
#include <stdio.h>
#include <string.h>
#include <math.h>
#include <malloc.h>
const long long max_size = 2000; // max length of strings
const long long N = 40; // number of closest words that will be shown
const long long max_w = 50; // max length of vocabulary entries
int main(int argc, char **argv) {
FILE *f;
char st1[max_size];
char *bestw[N];
char file_name[max_size], st[100][max_size];
float dist, len, bestd[N], vec[max_size]; //dist: distance; len: norm of vector; bestd: best distance
long long words, size, a, b, c, d, cn, bi[100];
char ch;
float *M;
char *vocab;
if (argc < 2) {
printf("Usage: ./distance <FILE>\nwhere FILE contains word projections in the BINARY FORMAT\n");
return 0;
}
strcpy(file_name, argv[1]); //copy filename to the variable
f = fopen(file_name, "rb"); //open the file in BINARY mode
if (f == NULL) {
printf("Input file not found\n");
return -1;
}
fscanf(f, "%lld", &words); //word count
fscanf(f, "%lld", &size); //dimension count
vocab = (char *)malloc((long long)words * max_w * sizeof(char)); //memory alloc, store words, max_w chars per word
for (a = 0; a < N; a++) bestw[a] = (char *)malloc(max_size * sizeof(char)); //memory alloc, store closest vocabs
M = (float *)malloc((long long)words * (long long)size * sizeof(float)); //memory alloc, store vectors
if (M == NULL) {
printf("Cannot allocate memory: %lld MB %lld %lld\n", (long long)words * size * sizeof(float) / 1048576, words, size); //1048576 = 1024 * 1024
return -1;
}
for (b = 0; b < words; b++) {
fscanf(f, "%s%c", &vocab[b * max_w], &ch);
for (a = 0; a < size; a++) fread(&M[a + b * size], sizeof(float), 1, f);
len = 0;
for (a = 0; a < size; a++) len += M[a + b * size] * M[a + b * size];
len = sqrt(len); //denominator, [ZH_CN]FenMu
for (a = 0; a < size; a++) M[a + b * size] /= len; //unit vector, [ZH_CN]DanWei XiangLiang
}
fclose(f);
while (1) {
for (a = 0; a < N; a++) bestd[a] = 0;
for (a = 0; a < N; a++) bestw[a][0] = 0;
printf("Enter word or sentence (EXIT to break): ");
a = 0;
while (1) {
st1[a] = fgetc(stdin);
if ((st1[a] == '\n') || (a >= max_size - 1)) {
st1[a] = 0;
break;
}
a++;
}
if (!strcmp(st1, "EXIT")) break;
cn = 0;
b = 0;
c = 0;
while (1) { //multiple words separated by BLANK symbol
st[cn][b] = st1[c];
b++;
c++;
st[cn][b] = 0; //assign '\0' after the words, if new charactor found, this value can be replaced.
if (st1[c] == 0) break;
if (st1[c] == ' ') {
cn++;
b = 0;
c++;
}
}
cn++;
for (a = 0; a < cn; a++) { //check word position in vocab array.
for (b = 0; b < words; b++) if (!strcmp(&vocab[b * max_w], st[a])) break; //found it, b store the position
if (b == words) b = -1; //not found, b = -1
bi[a] = b; //position array, store all words input this time
printf("\nWord: %s Position in vocabulary: %lld\n", st[a], bi[a]);
if (b == -1) {
printf("Out of dictionary word!\n");
break;
}
}
if (b == -1) continue; //if not found, continue; otherwise, search for closest words
printf("\n Word Cosine distance\n------------------------------------------------------------------------\n");
for (a = 0; a < size; a++) vec[a] = 0;
for (b = 0; b < cn; b++) {
if (bi[b] == -1) continue; //if not found, pass it
for (a = 0; a < size; a++) vec[a] += M[a + bi[b] * size]; //add all vectors of words found this time
}
len = 0;
for (a = 0; a < size; a++) len += vec[a] * vec[a];
len = sqrt(len); //is it needful? Yes, different vector makes different len value
for (a = 0; a < size; a++) vec[a] /= len; //unit vector
for (a = 0; a < N; a++) bestd[a] = -1; //best distances, init with -1
for (a = 0; a < N; a++) bestw[a][0] = 0; //best words, init with '\0'
for (c = 0; c < words; c++) { //traverse all words
a = 0;
for (b = 0; b < cn; b++) if (bi[b] == c) a = 1;
if (a == 1) continue; //pass words in vocab
dist = 0;
for (a = 0; a < size; a++) dist += vec[a] * M[a + c * size];
for (a = 0; a < N; a++) { //sort dist, Insertion Sort, DESC
if (dist > bestd[a]) {
for (d = N - 1; d > a; d--) {
bestd[d] = bestd[d - 1];
strcpy(bestw[d], bestw[d - 1]);
}
bestd[a] = dist;
strcpy(bestw[a], &vocab[c * max_w]);
break;
}
}
}
for (a = 0; a < N; a++) printf("%50s\t\t%f\n", bestw[a], bestd[a]); //display results
}
return 0;
}
从代码中可以看出,Mikolov使用的方法原理上还是很简单的。将输入的所有(在模型中存在的)词的向量进行加和(行107),然后进行向量的单位化(行112),最后与vocab中所有在输入序列中出现的word对应的(单位)向量取cosine值。此过程中需要注意的是,Mikolov默认跳过了所有在输入序列中出现的word(行118)。尽管在计算过程中曾经得到过所有词与输入串的dist,但是由于N = 40(行21),因此只有前40条记录会被保存并进行最后的输出,有需要的话可以自行设定该值。
另外,由于max_w = 50(行22),因此对于训练出的结果中存在长词(≥50字节)的情况,还需修改该常量的值。
附上测试截图:
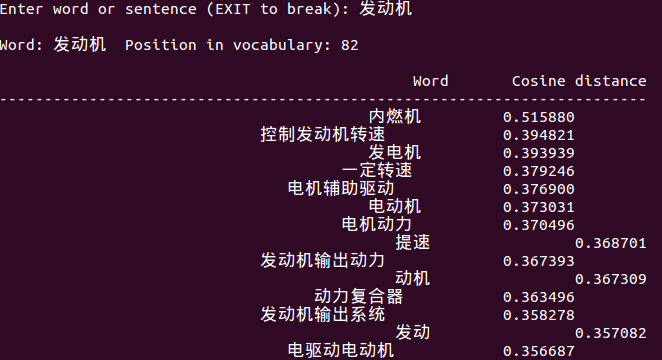
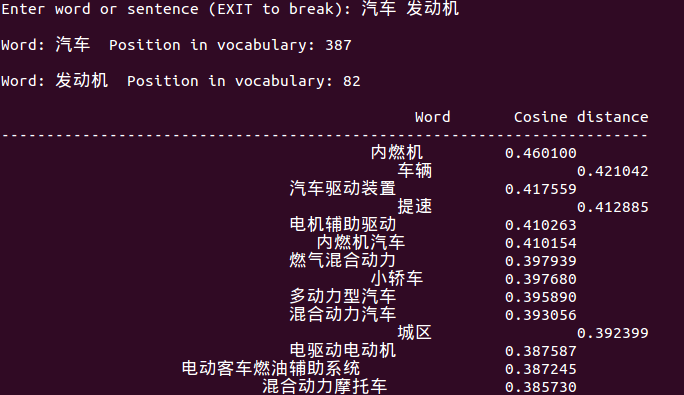















 2968
2968

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









