







序
深度学习现在大火,虽然自己上过深度学习课程、用过keras做过一些实验,始终觉得理解不透彻。最近仔细学习前辈和学者的著作,感谢他们的无私奉献,整理得到本文,共勉。
1.前言
(1)神经网络的缺陷
在神经网络一文中简单介绍了其原理,可以发现不同层之间是全连接的,当神经网络的深度、节点数变大,会导致过拟合、参数过多等问题。
(2)计算机视觉(图像)背景
- 通过抽取只依赖图像里小的子区域的局部特征,然后利用这些特征的信息就可以融合到后续处理阶段中,从而检测更高级的特征,最后产生图像整体的信息。
- 距离较近的像素的相关性要远大于距离较远像素的相关性。
- 对于图像的一个区域有用的局部特征可能对于图像的其他区域也有用,例如感兴趣的物体发生平移的情形。
2.卷积神经网络(CNN)特性
根据前言中的两方面,这里介绍卷积神经网络的两个特性。
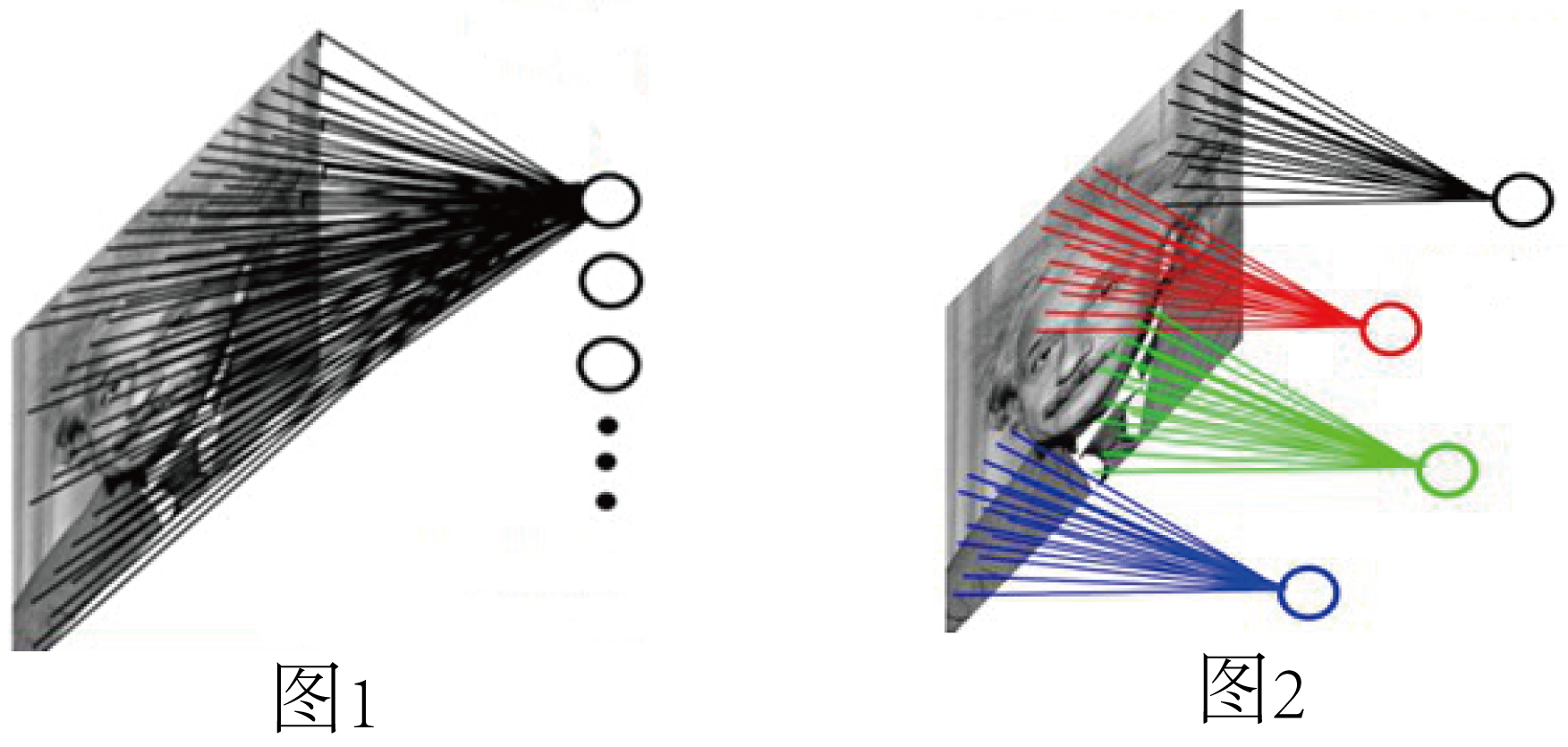
(1)局部感知
图1:全连接网络。如果L1层有1000×1000像素的图像,L2层有1000,000个隐层神经元,每个隐层神经元都连接L1层图像的每一个像素点,就有1000x1000x1000,000=10^12个连接,也就是10^12个权值参数。
图2:局部连接网络。L2层每一个节点与L1层节点同位置附近10×10的窗口相连接,则1百万个隐层神经元就只有100w乘以100,即10^8个参数。其权值连接个数比原来减少了四个数量级。
(2)权值共享
就图2来说,权值共享,不是说,所有的红色线标注的连接权值相同。而是说,每一个颜色的线都有一个红色线的权值与之相等,所以第二层的每个节点,其从上一层进行卷积的参数都是相同的。
图2中隐层的每一个神经元都连接10×10个图像区域,也就是说每一个神经元存在10×10=100个连接权值参数。如果我们每个神经元这100个参数是相同的?也就是说每个神经元用的是同一个卷积核去卷积图像。这样L1层我们就只有100个参数。但是这样,只提取了图像一种特征?如果需要提取不同的特征,就加多几种卷积核。所以假设我们加到100种卷积核,也就是1万个参数。
每种卷积核的参数不一样,表示它提出输入图像的不同特征(不同的边缘)。这样每种卷积核去卷积图像就得到对图像的不同特征的放映,我们称之为Feature Map,也就是特征图。
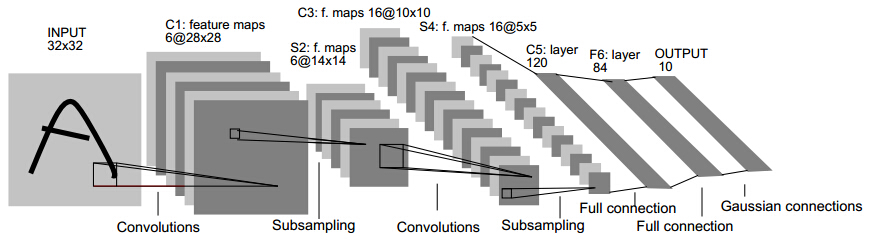
3.网络结构
以LeCun的LeNet-5为例,不包含输入,LeNet-5共有7层,每层都包含连接权值(可训练参数)。输入图像为32*32大小。我们先要明确一点:每个层有多个特征图,每个特征图通过一种卷积滤波器提取输入的一种特征,然后每个特征图有多个神经元。
C1、C3、C5是卷积层,S2、S4、S6是下采样层。利用图像局部相关性的原理,对图像进行下抽样,可以减少数据处理量同时保留有用信息。
4.前向传播
在神经网络一文中已经详细介绍过全连接和激励层的前向传播过程,这里主要介绍卷积层、下采样(池化)层。
(1)卷积层
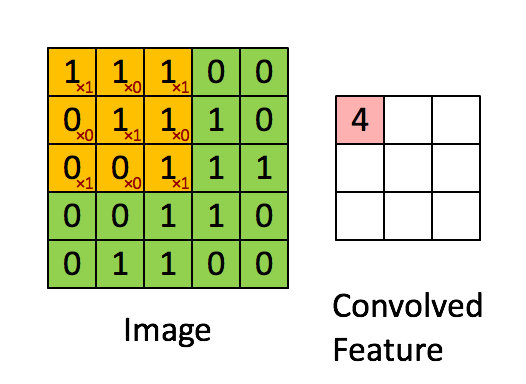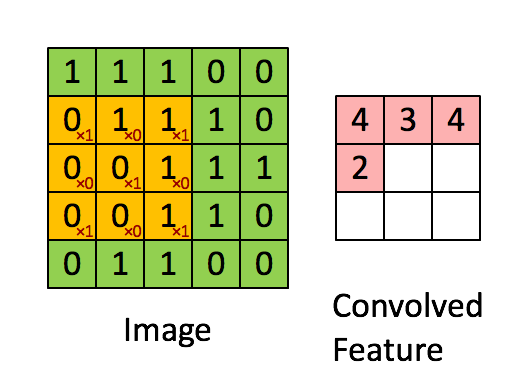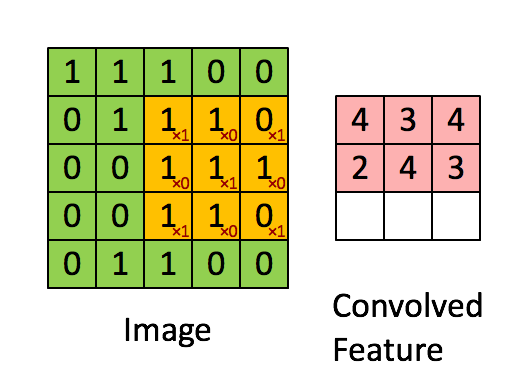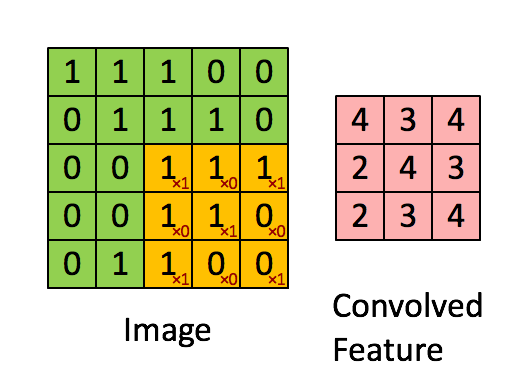
如图4所示,输入图片是一个5×5的图片,用一个3×3的卷积核对该图片进行卷积操作。本质上是一个点积操作。举例:1×1+0×1+1×1+0×0+1×1+0×1+1×0+0×0+1×1=4
def conv2(X, k):
x_row, x_col = X.shape
k_row, k_col = k.shape
ret_row, ret_col = x_row - k_row + 1, x_col - k_col + 1
ret = np.empty((ret_row, ret_col))
for y in range(ret_row):
for x in range(ret_col):
sub = X[y : y + k_row, x : x + k_col]
ret[y,x] = np.sum(sub * k)
return ret
class ConvLayer:
def __init__(self, in_channel, out_channel, kernel_size):
self.w = np.random.randn(in_channel, out_channel, kernel_size, kernel_size)
self.b = np.zeros((out_channel))
def _relu(self, x):
x[x < 0] = 0
def forward(self, in_data):
# assume the first index is channel index
in_channel, in_row, in_col = in_data.shape
out_channel, kernel_row, kernel_col = self.w.shape[1], self.w.shape[2], self.w.shape[3]
self.top_val = np.zeros((out_channel, in_row - kernel_row + 1, in_col - kernel_col + 1))
for j in range(out_channel):
for i in range(in_channel):
self.top_val[j] += conv2(in_data[i], self.w[i, j])
self.top_val[j] += self.b[j]
self.top_val[j] = self._relu(self.topval[j])
return self.top_val(2)下采样(池化)层
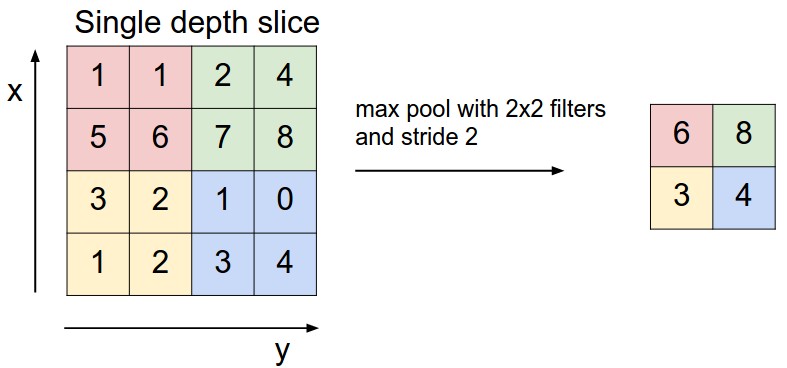
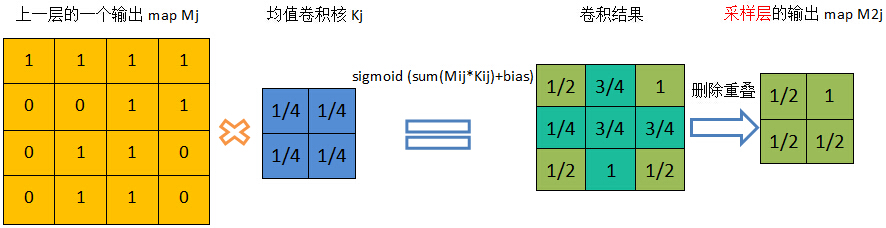
下采样,即池化,目的是减小特征图,池化规模一般为2×2。常用的池化方法有:
- 最大池化(Max Pooling)。如图5所示。
- 均值池化(Mean Pooling)。如图6所示。
- 高斯池化。借鉴高斯模糊的方法。
- 可训练池化。训练函数 ff ,接受4个点为输入,输出1个点。
class MaxPoolingLayer:
def __init__(self, kernel_size, name='MaxPool'):
self.kernel_size = kernel_size
def forward(self, in_data):
in_batch, in_channel, in_row, in_col = in_data.shape
k = self.kernel_size
out_row = in_row / k + (1 if in_row % k != 0 else 0)
out_col = in_col / k + (1 if in_col % k != 0  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









