







 本文介绍了Google的PageRank算法以及MapReduce的思想。PageRank通过矩阵计算确定网页权重,但在大规模数据下面临计算难题。为此,Google提出了MapReduce模型,它将大任务拆分为并行的小任务,通过Map阶段的映射和Reduce阶段的聚合,解决大规模数据处理问题。MapReduce程序由Map、Shuffle和Reduce三部分组成,所有输入输出都是本文介绍了Google的PageRank算法以及MapReduce的思想。PageRank通过矩阵计算确定网页权重,但在大规模数据下面临计算难题。为此,Google提出了MapReduce模型,它将大任务拆分为并行的小任务,通过Map阶段的映射和Reduce阶段的聚合,解决大规模数据处理问题。MapReduce程序由Map、Shuffle和Reduce三部分组成,所有输入输出都是
本文介绍了Google的PageRank算法以及MapReduce的思想。PageRank通过矩阵计算确定网页权重,但在大规模数据下面临计算难题。为此,Google提出了MapReduce模型,它将大任务拆分为并行的小任务,通过Map阶段的映射和Reduce阶段的聚合,解决大规模数据处理问题。MapReduce程序由Map、Shuffle和Reduce三部分组成,所有输入输出都是本文介绍了Google的PageRank算法以及MapReduce的思想。PageRank通过矩阵计算确定网页权重,但在大规模数据下面临计算难题。为此,Google提出了MapReduce模型,它将大任务拆分为并行的小任务,通过Map阶段的映射和Reduce阶段的聚合,解决大规模数据处理问题。MapReduce程序由Map、Shuffle和Reduce三部分组成,所有输入输出都是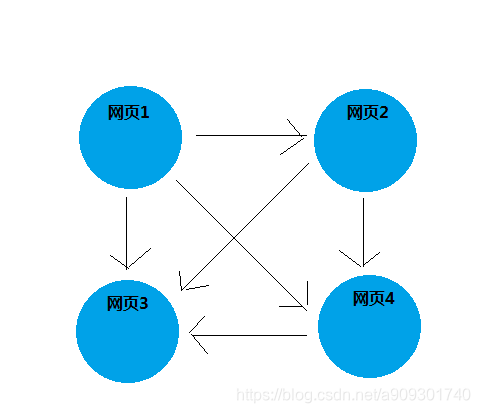
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















05-24
 580
580
580
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









