







一、InnoDB记录存储结构
1.InnoDB
InnoDB将数据划分为若干个页,以页作为磁盘和内存之间交互的基本单位,InnoDB中页的大小一般为 16 KB。
我们以记录为单位来向表中插入数据的,这些记录在磁盘上的存放方式也被称为行格式或者记录格式。InnoDB存储引擎到现在为止设计了4种不同类型的行格式,分别是Compact、Redundant、Dynamic和Compressed行格式。
2.COMPACT行格式
一条完整的记录其实可以被分为记录的额外信息和记录的真实数据两大部分,其中记录的额外信息又包括变长字段长度列表、null值列表、记录头信息,如下图:
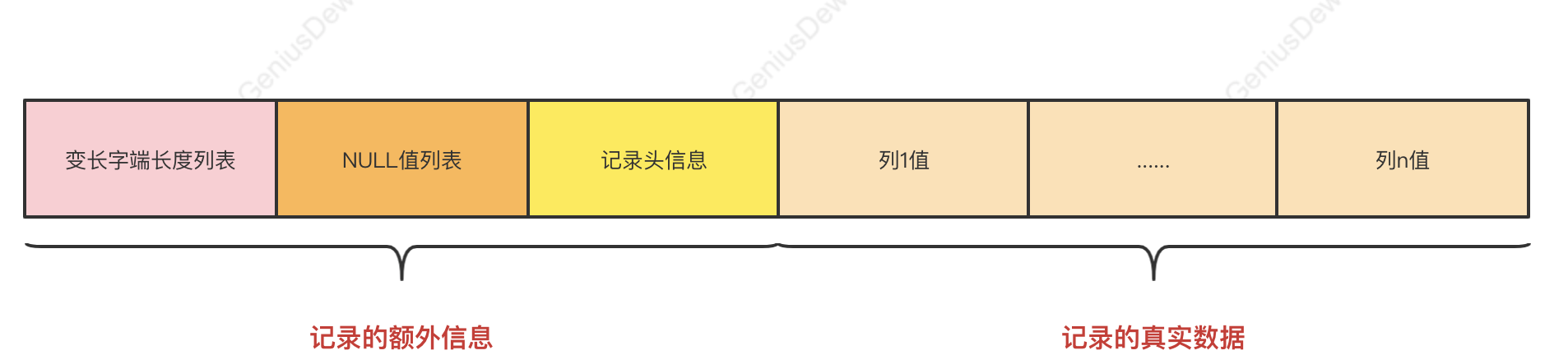
2.1 记录的额外信息
2.1.1 变长字段长度列表
MySQL中的有一些变长的数据类型,比如VARCHAR(M)、各种TEXT类型、BLOB类型,这种变长字段中存储多少字节的数据不固定,所以在存储真实数据的时候需要把这些数据占用的字节数也存起来。也就是说对于变长字端来说,数据的存储分为两个部分:真实数据、占用的字节数。
- 在Compact行格式中,把所有变长字段的真实数据占用的字节长度都存放在记录的开头部位,从而形成一个变长字段长度列表,各变长字段数据占用的字节数按照列的顺序逆序存放
- 变长字段长度列表中只存储值为非NULL的列内容占用的长度,值为 NULL的列长度是不存的
- 对于 CHAR(M)类型的列来说,当列采用的是定长字符集时,该列占用的字节数不会被加到变长字段长度列表,而如果采用变长字符集时,该列占用的字节数也会被加到变长字段长度列表
- 如果表中所有的列都不是变长字端,则变长字段长度列表也不存在
2.1.2 NULL值列表
表中的某些列可能存储NULL值,但是像主键列、被NOT NULL修饰的列不可以存储NULL值,每个允许存储NULL的列在NULL值列表中对应一个二进制位。
- 二进制位按照列的顺序逆序排列,二进制位的值为1时,代表该列的值为NULL;二进制位的值为0时,代表该列的值不为NULL
- NULL值列表必须用整数个字节的位表示,如果使用的二进制位个数不是整数个字节,则在字节的高位补0。例如一个表中只有3个字端允许NULL值,那么就对应3个二进制位,就在前5个二进制位补0
- 如果表中没有允许存储 NULL 的列,则 NULL值列表也不存在
2.1.3 记录头信息
-
用于描述记录,由固定的5个字节组成,40个二进制位,不同的位代表不同的意思
-
名称 大小 (单位:bit) 描述 预留位1 1 没有使用 预留位2 1 没有使用 delete_mask 1 标记该记录是否被删除。值为0的时候代表记录并没有被删除,为1的时候代表记录被删除掉了 min_rec_mask 1 B+树的每层非叶子节点中的最小记录都会添加该标记 n_owned 4 表示当前记录拥有的记录数 heap_no 13 表示当前记录在本页的位置信息。最小记录和最大记录的heap_no值分别是 0和1,这两条记录被单独放在一个称为Infimum + Supremum的部分。构造都是由5字节大小的记录头信息和8字节大小的一个固定的部分组成record_type 3 表示当前记录的类型,0表示普通记录,1表示B+树非叶子节点记录,2表示最小记录,3表示最大记录 next_record 16 表示从当前记录的真实数据到下一条记录的真实数据的地址偏移量。下一条记录指得是按照主键值由小到大的顺序的下一条记录
2.2 记录的真实数据
MySQL会为每个记录默认的添加一些隐藏列
| 列名 | 是否必须 | 占用空间 | 描述 |
|---|---|---|---|
DB_ROW_ID | 否 | 6字节 | 行ID,唯一标识一条记录 |
DB_TRX_ID | 是 | 6字节 | 事务ID |
DB_ROLL_PTR | 是 | 7字节 | 回滚指针 |
InnoDB存储引擎会为每条记录都添加 DB_TRX_ID 和 DB_ROLL_PTR 这两个列,但是 DB_ROW_ID 是可选的(在没有自定义主键以及Unique键的情况下才会添加该列)

3.行溢出数据
一个页一般是16KB,当记录中的数据太多,当前页放不下的时候,会把多余的数据存储到其他页中,这种现象称为行溢出。
3.1 VARCHAR(M)最多能存储的数据
VARCHAR(M)类型的列最多可以占用65535个字节,包括3部分存储空间:
- 真实数据
- 真实数据占用字节的长度
- NULL值标识,如果该列有NOT NULL属性则可以没有这部分存储空间
根据字符集的不同,M的最大取值也会不同。如果使用ascii字符集,如果该VARCHAR类型的列没有NOT NULL属性,那最多只能存储65532个字节的数据,因为真实数据的长度可能占用2个字节,NULL值标识需要占用1个字节;有NOT NULL属性,那最多只能存储65533个字节的数据,因为真实数据的长度可能占用2个字节,不需要NULL值标识。
在列的值允许为NULL的情况下,gbk字符集下M的最大取值就是32766,utf8字符集下M的最大取值就是21844,这都是在表中只有一个字段的情况下说的,一个行中的所有列(不包括隐藏列和记录头信息)占用的字节长度加起来不能超过65535个字节
3.2 记录中的数据太多产生的溢出
MySQL是以页为基本单位来管理存储空间的,一个页的大小一般是16KB,也就是16384字节,而一个VARCHAR(M)类型的列就最多可以存储65532个字节(不只是 VARCHAR(M) 类型的列,其他的 TEXT、BLOB 类型的列在存储数据非常多的时候也会发生行溢出),这样就可能造成一个页存放不了一条记录的情况。
在Compact和Redundant行格式中,对于占用存储空间非常大的列,在记录的真实数据处只会存储该列的前768个字节的数据和一个指向其他页的地址,把剩余的数据分散存储在几个其他的页中。
4.Dynamic和Compressed行格式
这俩行格式和Compact行格式只不过在处理行溢出数据时有点儿分歧,它们不会在记录的真实数据处存储字段真实数据的前768个字节,而是把所有的字节都存储到其他页面中,只在记录的真实数据处存储其他页面的地址。
Compressed行格式和Dynamic不同的一点是,Compressed行格式会采用压缩算法对页面进行压缩,以节省空间。
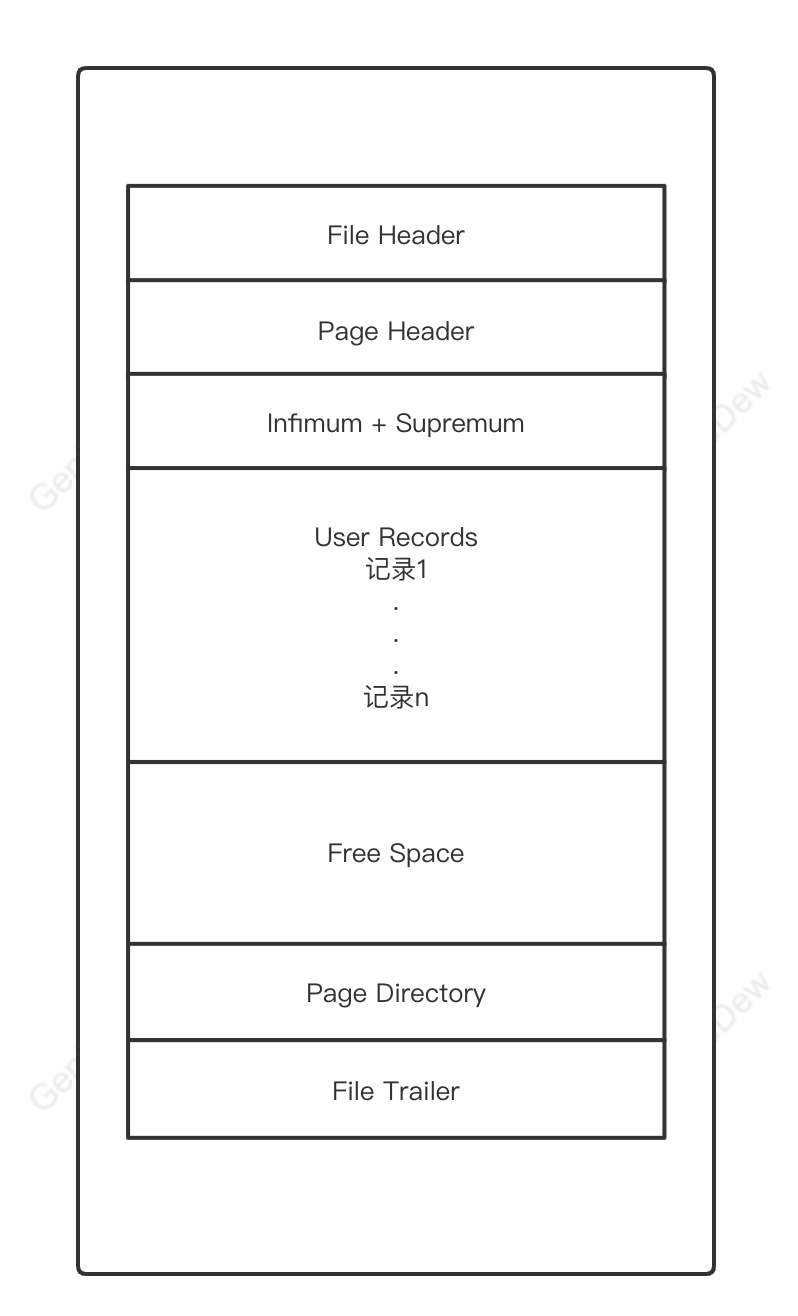
二、InnoDB索引页结构
是InnoDB管理存储空间的基本单位,一个页的大小一般是16KB。为了不同的目的而设计了许多种不同类型的页,存放表中记录的那种类型的页为索引(INDEX)页。
1.索引(INDEX)页结构
一个InnoDB索引页的16KB存储空间大致被划分成了7个部分:
| 名称 | 中文名 | 占用空间大小 | 简单描述 |
|---|---|---|---|
| File Header | 文件头部 | 38字节 | 页的一些通用信息 |
| Page Header | 页面头部 | 56字节 | 索引页专有的一些信息 |
| Infimum + Supremum | 最小记录和最大记录 | 26字节 | 两个虚拟的行记录 |
| User Records | 用户记录 | 不确定 | 实际存储的行记录内容 |
| Free Space | 空闲空间 | 不确定 | 页中尚未使用的空间 |
| Page Directory | 页面目录 | 不确定 | 页中的某些记录的相对位置 |
| File Trailer | 文件尾部 | 8字节 | 校验页是否完整 |
2.记录在页中的存储
存储的记录会按照指定的行格式存储到User Records部分。
一开始生成页的时候,并没有User Records,每当插入一条记录,都会从Free Space部分申请一个记录大小的空间划分到User Records部分。当Free Space部分的空间全部被User Records部分替代掉之后,也就意味着这个页使用完了,如果还有新的记录插入的话,就需要去申请新的页了。
索引(INDEX)页结构:
单条记录在User Records中的格式:

记录头中的一些信息:
- delete_mask为0代表没有被删除;
- min_rec_mask为0代表不是B+树的非叶子节点中的最小记录;
- heap_no表示当前记录在本页中的位置,从2开始(因为0和1分别代表页中的最小记录和最大纪录,存放在页中的Infimum + Supremum);
- record_type代表记录类型为0,代表普通记录;
- n_owned表示当前记录拥有的记录数;
- next_record代表从当前记录的真实数据到下一条记录的真实数据的地址偏移量,按照主键值由小到大的顺序排列,0意味着该记录没有下一条记录。同时规定Infimum记录的下一条记录就是本页中主键值最小的用户记录,而本页中主键值最大的用户记录的下一条记录就是 Supremum记录,本质就是个单向链表。
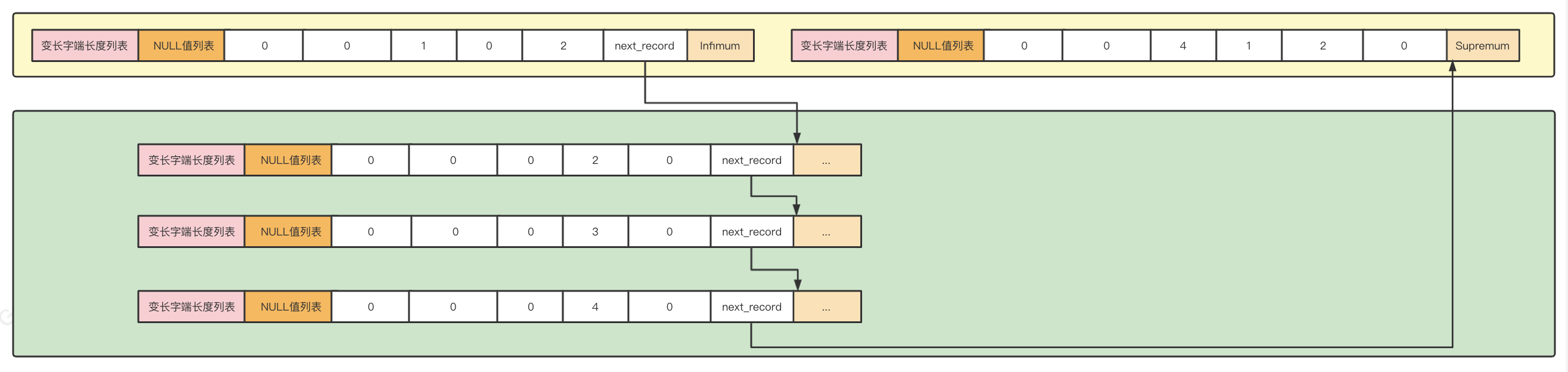
因此,记录在页中的存储,就是按照主键值由小到大顺序组成的一个单向链表。
3.Page Directory
InnoDB制作了一个目录,目的是为了方便通过主键查找页中的某条记录。
将所有正常的记录划分为几个组,每个组的最大记录n_owned属性表示该记录拥有多少条记录,也就是该组内共有几条记录,将每个组的最后一条记录的地址偏移量单独提取出来按顺序存储到Page Directory,也就是页目录,页目录中的地址偏移量被称为槽。
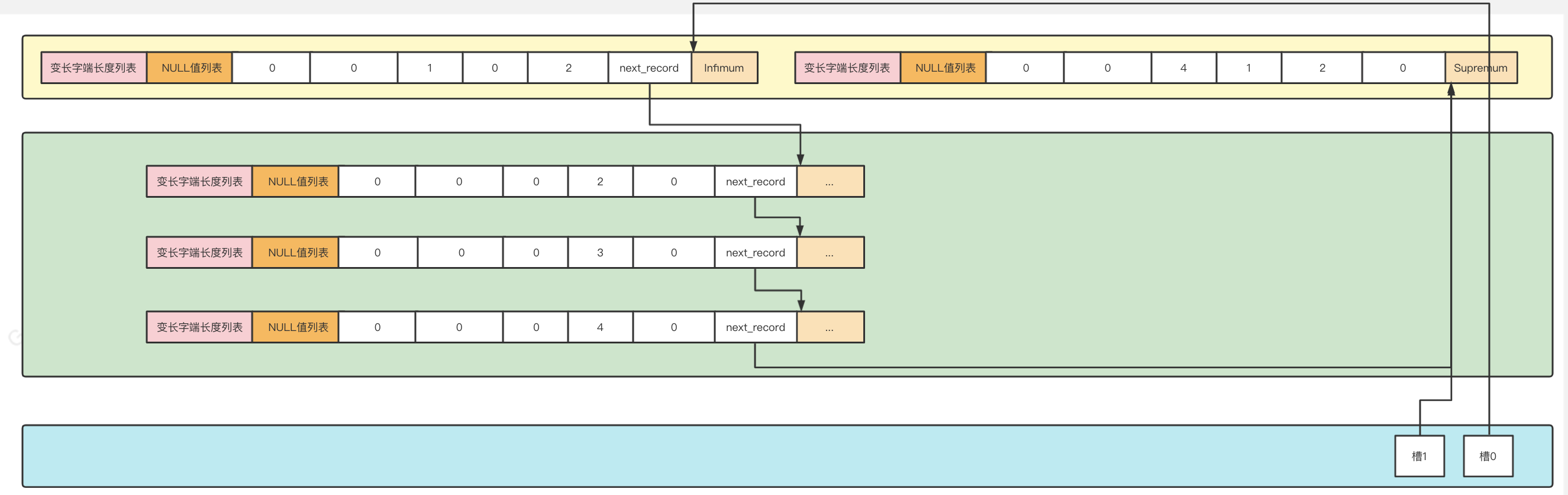
如图中的蓝色部分为Page Directory,里面有两个槽,说明该页面中的记录分为两个组。其中最小记录自己一个组,所以n_owned为1,其余4条为一个组,所以最大纪录的n_owned为4,那么两个槽则分别表示了最小记录和最大纪录的地址偏移量。
对每个分组中的记录条数的规定:对于最小记录所在的分组只能有 1 条记录,最大记录所在的分组拥有的记录条数只能在 1~8 条之间,剩下的分组中记录的条数范围只能在是 4~8 条之间。
因此通过主键查找某条记录,就可以在页目录中使用二分法快速定位到对应的槽,找到该槽所在分组中主键值最小的那条记录(上一个槽对应的记录的下一条记录就是该槽的主键最小的记录),然后再通过记录的next_record属性遍历该槽对应分组中的记录即可快速找到指定的记录。
4.Page Header
索引页中存储记录的状态信息,占用固定的56个字节。
| 名称 | 占用空间大小 | 描述 |
|---|---|---|
PAGE_N_DIR_SLOTS | 2字节 | 在页目录中的槽数量 |
PAGE_HEAP_TOP | 2字节 | 还未使用的空间最小地址,也就是说从该地址之后就是Free Space |
PAGE_N_HEAP | 2字节 | 本页中的记录的数量(包括最小和最大记录以及标记为删除的记录) |
PAGE_FREE | 2字节 | 第一个已经标记为删除的记录地址(各个已删除的记录通过next_record也会组成一个单链表,这个单链表中的记录可以被重新利用) |
PAGE_GARBAGE | 2字节 | 已删除记录占用的字节数 |
PAGE_LAST_INSERT | 2字节 | 最后插入记录的位置 |
PAGE_DIRECTION | 2字节 | 记录插入的方向 |
PAGE_N_DIRECTION | 2字节 | 一个方向连续插入的记录数量 |
PAGE_N_RECS | 2字节 | 该页中记录的数量(不包括最小和最大记录以及被标记为删除的记录) |
PAGE_MAX_TRX_ID | 8字节 | 修改当前页的最大事务ID,该值仅在二级索引中定义 |
PAGE_LEVEL | 2字节 | 当前页在B+树中所处的层级 |
PAGE_INDEX_ID | 8字节 | 索引ID,表示当前页属于哪个索引 |
PAGE_BTR_SEG_LEAF | 10字节 | B+树叶子段的头部信息,仅在B+树的Root页定义 |
PAGE_BTR_SEG_TOP | 10字节 | B+树非叶子段的头部信息,仅在B+树的Root页定义 |
5.File Header
针对各种类型的页都通用,不同类型的页都会以File Header作为第一个组成部分,它描述了一些针对各种页都通用的一些信息,占用固定的38个字节,是由下边这些内容组成的:
| 名称 | 占用空间大小 | 描述 |
|---|---|---|
FIL_PAGE_SPACE_OR_CHKSUM | 4字节 | 页的校验和(checksum值) |
FIL_PAGE_OFFSET | 4字节 | 页号 |
FIL_PAGE_PREV | 4字节 | 上一个页的页号 |
FIL_PAGE_NEXT | 4字节 | 下一个页的页号 |
FIL_PAGE_LSN | 8字节 | 页面被最后修改时对应的日志序列位置(Log Sequence Number) |
FIL_PAGE_TYPE | 2字节 | 该页的类型 |
FIL_PAGE_FILE_FLUSH_LSN | 8字节 | 仅在系统表空间的一个页中定义,代表文件至少被刷新到了对应的LSN值 |
FIL_PAGE_ARCH_LOG_NO_OR_SPACE_ID | 4字节 | 页属于哪个表空间 |
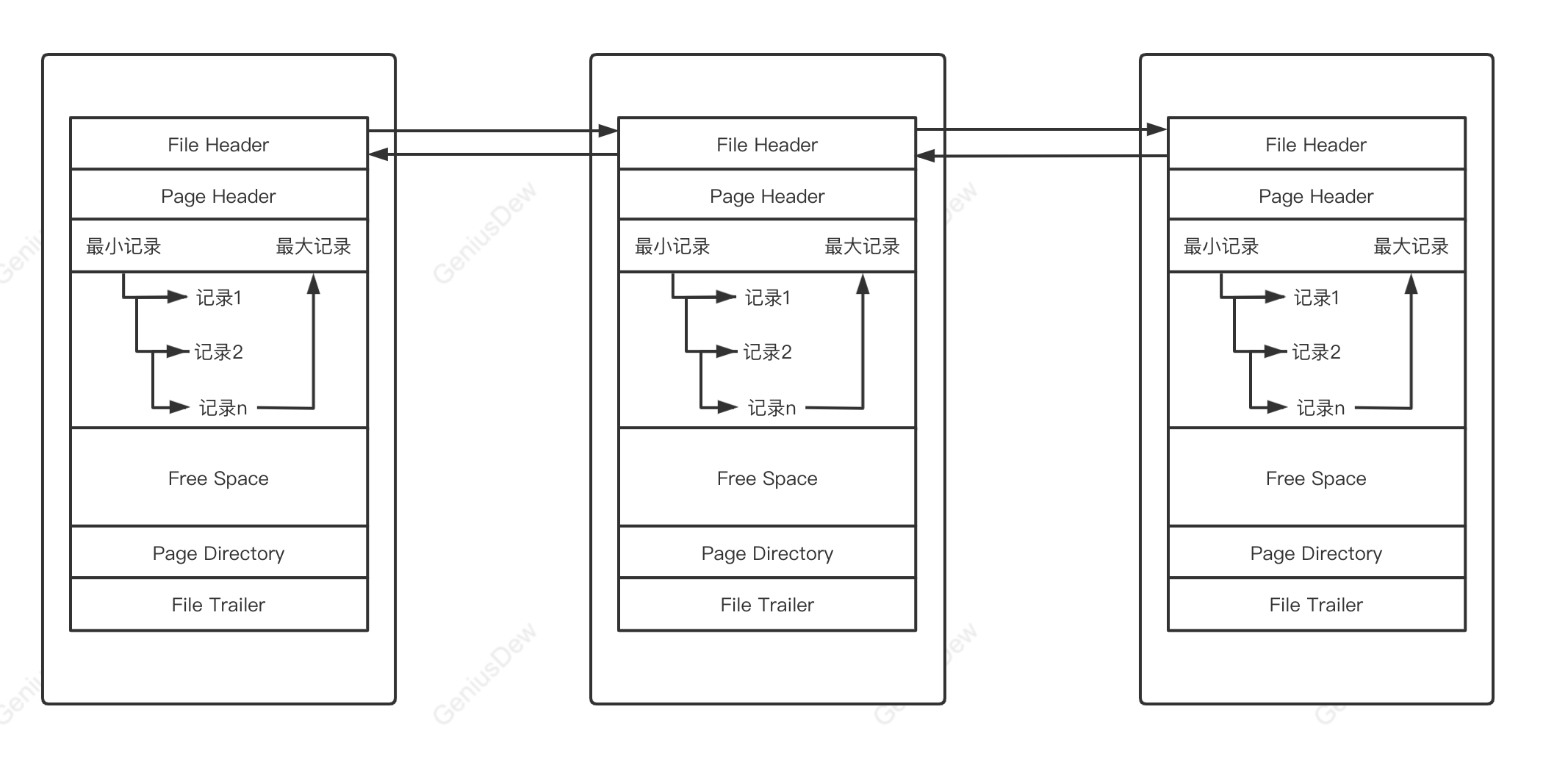
InnoDB中的各个页通过FIL_PAGE_PREV和FIL_PAGE_NEXT两个属性组成一个双向链表,不是所有类型的页都有这两个属性,但是索引页都有这两个属性,所以索引页本质是一个双向链表。
6.File Trailer
为了检测一个页是否完整,在每个页的尾部都加了一个File Trailer部分,各种类型的页都通用。这个部分由8个字节组成,可以分成2个小部分:
- 前4个字节代表页的校验和
- 后4个字节代表页面被最后修改时对应的日志序列位置(LSN)
所以InnoDB中:
- 各个索引页通过FIL_PAGE_PREV和FIL_PAGE_NEXT可以组成一个双向链表;
- 每个索引页中的记录通过next_record属性会按照主键值从小到大的顺序组成一个单向链表;
- 每个索引页都会为记录生成一个页目录;
- 在通过主键查找某条记录的时候可以在页目录中使用二分法快速定位到对应的槽,然后再遍历该槽对应分组中的记录即可快速找到指定的记录。















 1560
1560











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









