







准备工作:JDK、Hbase、Ant、Nutch
- 安装JDK(JDK8) 如果你已经安装JDK跳过此步骤
$:cd /usr/local
$:wget http://download.oracle.com/otn-pub/java/jdk/8u65-b17/jdk-8u65-linux-x64.tar.gz
$:tar zxvf jdk-8u65-linux-x64.tar.gz
$:mv jdk-8u65-linux-x64 jdk8配置JAVA环境变量
$:vim ~/.bashrc在bashrc中添加以下变量
export JAVA_HOME=/usr/local/jdk8
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
$:source ~/.bashrc输入命令测试是否安装成功
$:java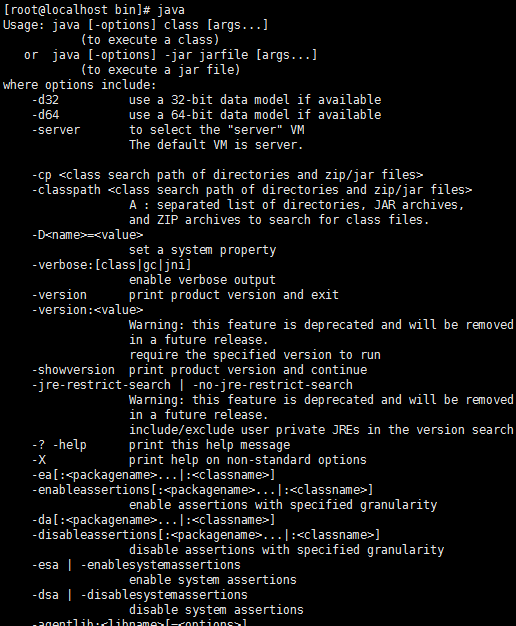
$:javac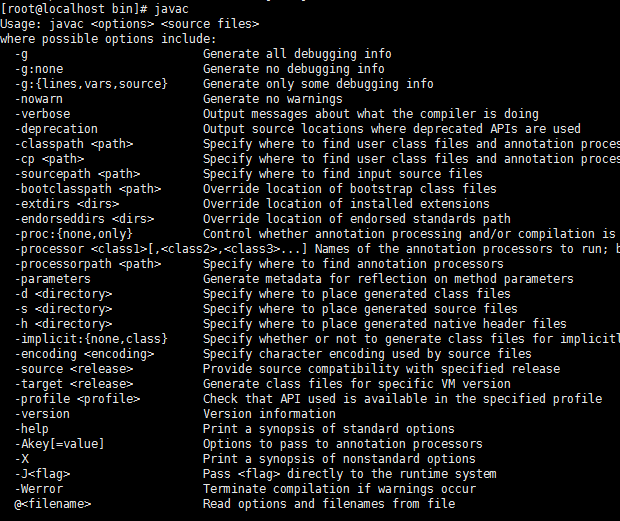
如果你看到类似以上两张图,表示OK了
2 安装Hbase(Hbase0.94) 如果你已经安装Hbase跳过此步骤
$:cd /usr/local
$:wget http://archive.apache.org/dist/hbase/hbase-0.94.14/hbase-0.94.14.tar.gz
$:tar zxvf hbase-0.94.14.tar.gz
$:mv hbase-0.94.14.tar.gz hbase配置Hbase环境变量
$:vim ~/.bashrc修改bashrc的PATH变量
export $JAVA_HOME/bin:/usr/local/hbase/bin:$PATH
$:source ~/.bashrc输入命令测试是否安装成功
$:hbase -version
如果你看到类似上图,表示OK了
3 安装Ant 如果你已经安装Ant跳过此步骤
$:cd /usr/local
$:wget http://mirrors.hust.edu.cn/apache//ant/binaries/apache-ant-1.9.6-bin.tar.gz
$:tar zxvf apache-ant-1.9.6-bin.tar.gz
$:mv apache-ant-1.9.6-bin.tar.gz ant配置Ant环境变量
$:vim ~/.bashrc修改bashrc的PATH变量
export $JAVA_HOME/bin:/usr/local/hbase/bin:/usr/local/ant/bin:$PATH
$:source ~/.bashrc输入命令测试是否安装成功
$:ant -version
如果你看到类似上图,表示OK了
4 配置Nutch
$:cd /usr/local
$:wget http://124.202.164.16/files/4214000005F0F9BA/mirror.bit.edu.cn/apache/nutch/2.3/apache-nutch-2.3-src.tar.gz
$:tar zxvf apache-nutch-2.3-src.tar.gz
$:mv apache-nutch-2.3-src.tar.gz nutch
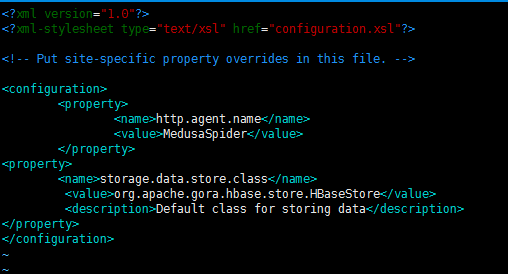
$:vim /usr/local/nutch/conf/nutch-site.xml在nutch-site.xml的configuration标签里加入以下配置
<property>
<name>http.agent.name</name>
<value>*这里写你的爬虫名字*</value>
</property>
<property>
<name>storage.data.store.class</name>
<value>org.apache.gora.hbase.store.HBaseStore</value>
<description>Default class for storing data</description>
</property>如图所示
继续,修改regex-urlfilter.txt文件
$:vim /usr/local/nutch/conf/regex-urlfilter.txt
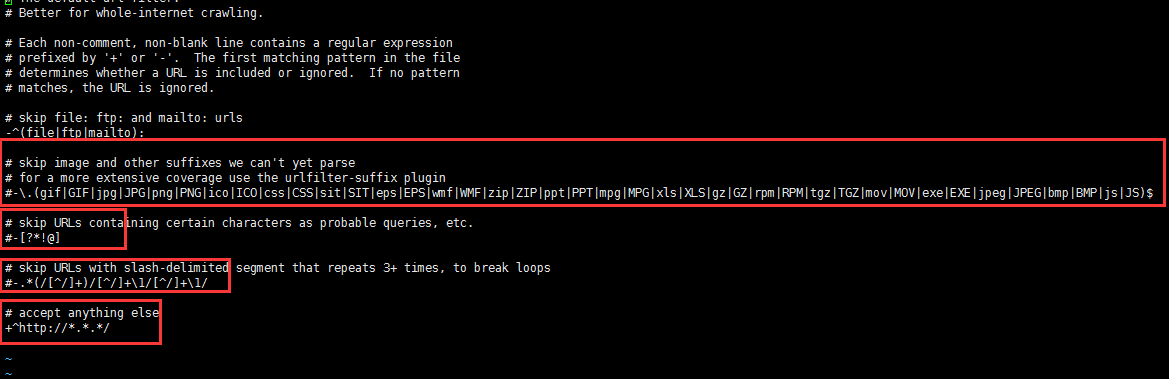
如图所示,注释掉里面的一些正则,为了之后抓取数据看到的效果更好,regex-urlfilter.txt用来过滤抓取网站的URL规则,关于regex-urlfilter.txt的正则语法就不作详细说明,网上一堆,这里就按照这样配置就行了.
$:vim /usr/local/nutch/ivy/ivy.xml找到下面这行,把注释打开
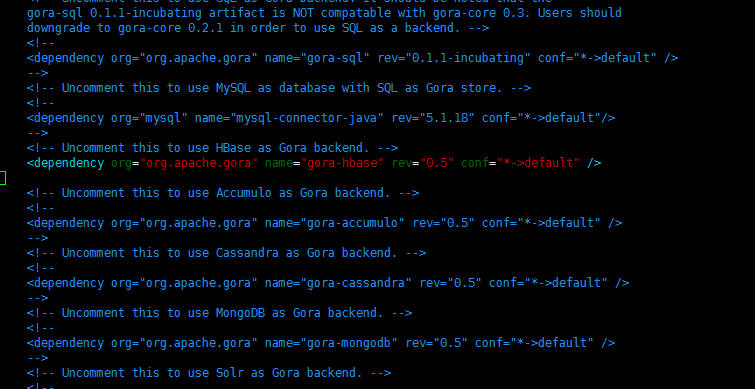
org="org.apache.gora" name="gora-hbase" rev="0.4" conf="*->default"/>如图所示
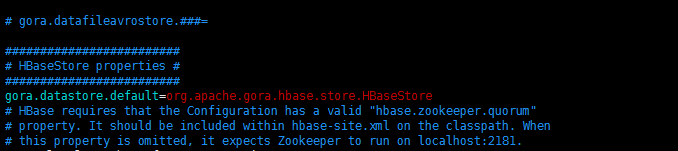
$:vim /usr/local/nutch/conf/gora.properties打开gora.properties文件添加以下配置
gora.datastore.default=org.apache.gora.hbase.store.HBaseStore如图所示
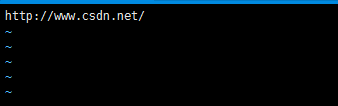
在seed.txt中添加要抓取的链接 这里以csdn为例
$:cd /usr/local/nutch/conf/
$:mkdir -p urls
$:cd urls
$:touch seed.txt
$:vim seed.txt
最后开始编译
$:cd /usr/local/nutch/编译runtime
$:ant runtime编译完成后
$:cd /usr/local/nutch/runtime/local/bin抓取
$:./crawl /usr/local/nutch/conf/urls/ numberOfRounds 10抓取完成后进入hbase shell查看数据
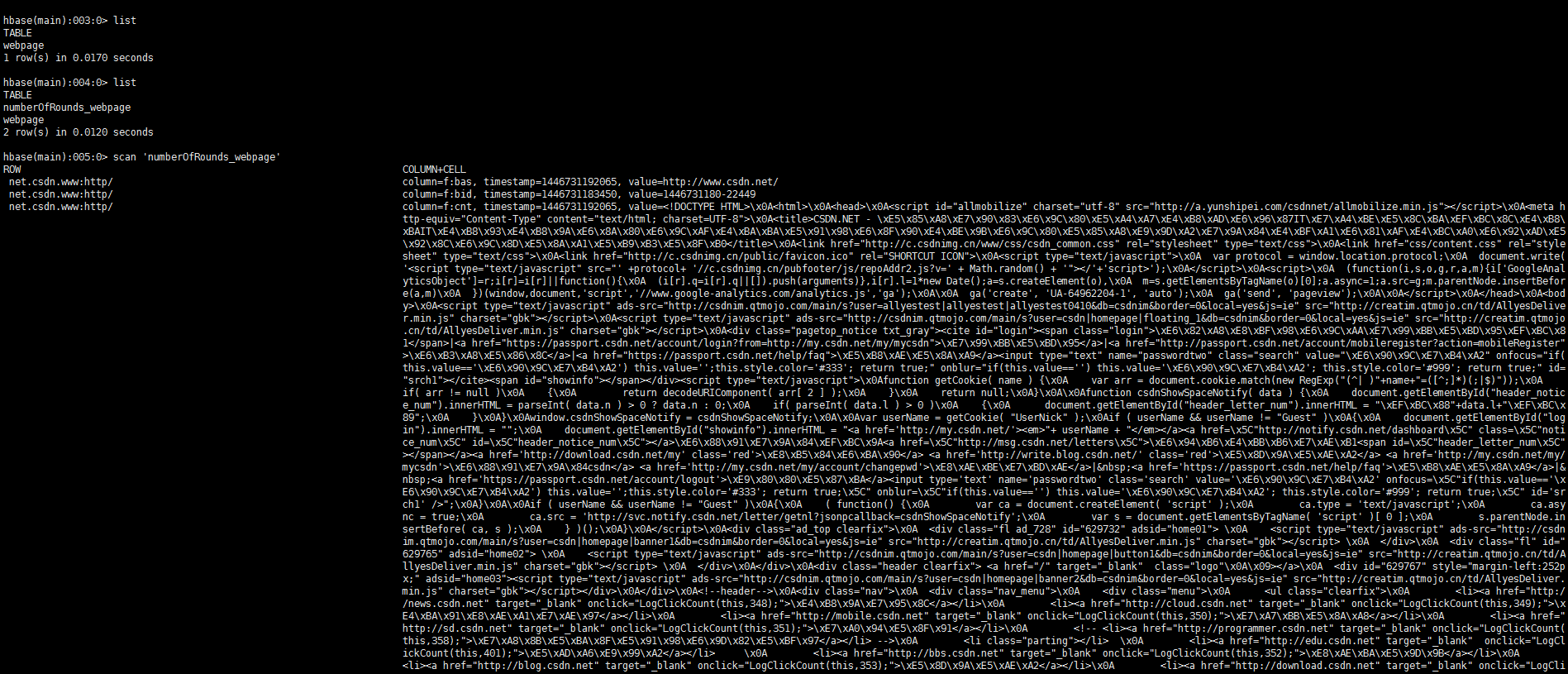
$:hbase shell查看列表
$:list查看数据(numberOfRounds_webpage)为表名,以list命令查出的表名为准,这里就以此表名做例子
$:scan 'numberOfRounds_webpage'
OK,Hbase里已经能查到抓取的数据了















 784
784

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









