






。,。前一篇文章我们编写好了爬取的类,现在我们开始编写爬去内容的部分
crawler = CrawlBSF()
maxthread = 20threads = []CRAWL_DELAY = 0.5
dum = open('stocklist.csv','r')
stocklist = dum.readlines()
dum.close()先定义一些需要用到的全局变量,将CrawlBSF类实例化为crawler对象,设置多线程最大线程数为20,等待时间为0.6秒,接着打开存放股票代码的stocklist.csv文件,读取文件中的股票代码存储到序列stocklist中
for stock in stocklist:
for i in range(20):
stockurl = "http://data.eastmoney.com/notices/getdata.ashx?StockCode=%s&CodeType=1&PageIndex=%s&PageSize=50&rt=50239182"%(stock[2:-1],i)两个for循环构造出了所有股票的接口url,打开连接后

构造出的URL打开后如图,我们不难发现,网页中的ENDDATA对应的是公告的时间,后面的“URL”则对应着该公告的网址。
比如

ENDDATA对应的是公告的时间,为2017-07-11,打开后面对应的url连接
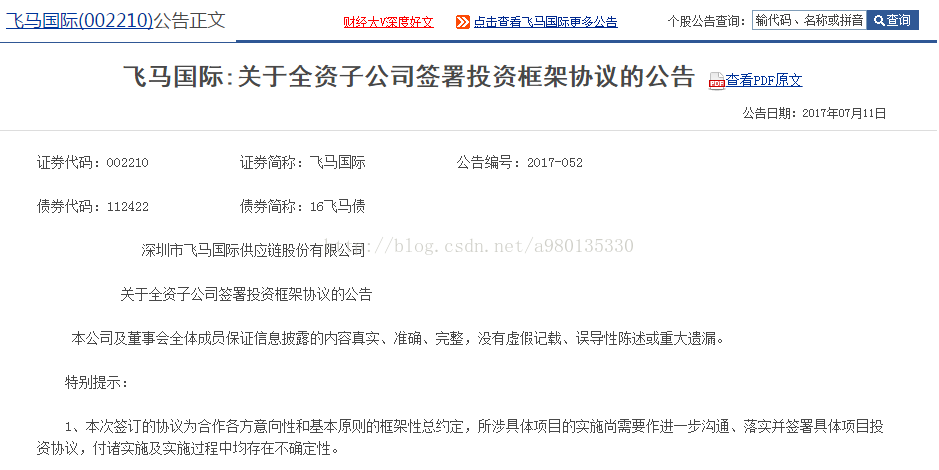
公告时间确为2017年7月11日,证实了我们的猜想。
我们使用正则表达式抓取公告的时间与它对应的url,以元组的形式返回方便我们储存和调用。
html_page = get_text(stockurl)
talk_url = re.findall(r'"ENDDATA":"(201[5678].*?))T.*?"URL":"(.*?)"}',html_page)talk_url为储存日期和公告内容url元组的序列,因为我们只抓取2015年至今的数据,所以在后面添加如下语句
if talk_url = []:
break
else:
for num in talk_url:
crawler.enqueueUrl(num)
如果页面没有2015后的公告数据了,则跳出循环,否则将对应的元组传入到爬取的队列中
由于传入的是公告内容链接和其对应的日期,属于元组信息,我们需要对CrawlBSF类中的enqueueUrl函数做一些修改
def enqueueUrl(self,url):
if hashlib.md5(url[1]).hexdigest() not in crawler.bloom_download_urls:
cur_queue.append(url) 。,。这样一个最内层的循环基本就完成了。















 2613
2613

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









