







课程标准为C++11
03 到 11变化特大, 14 - 17变化小,20版本刚推行使用特别有限
C++是C的超集
C++继承了C的绝大部分语法特性(摒弃了糟粕)
C++继承了C语言的29个标准头文件(在做工程开发:标准头文件 +非标准头文件混合编程)
C++头文件130个 (总共的头文件数量)
异常处理(C++11)
类和对象 STL 模板
Lambda(C++11)
STL由惠普实验室中的大佬们开发的工具,后来C++标准委员会纳入了C++的标准中,形成C++工具集STL
类和对象, 模板 , Lambda表达式,形成了C++的语言联邦
在C语言中使用的面相过程的函数编程
类和对象: 面向对象
模板: 泛型编程
Lambda表达式: 函数式编程
学习其他编程范式:提高编程效率
异常处理:挽回程序退出的一种方式
重点学习:
面相过程编程
面相对象编程
泛型编程
-
条款01: 视C++为一个语言联邦(学习C++方法)
今天的C++已经是个多重范式编程语言,一个同时支持过程形式,面向对象形式,函数形式,泛型形 式,元编程形式的语言。(范式编程,元编程都是模板编程)C++高效编程守则视情况而变化,取决于你使用C++的哪一部分
-
条款02:尽量以const/enum/inline替换#define(方便后续调试)
“宁肯以编译器替换预处理器”
#define 在预处理的时候会完成替换过程,所有宏对编译器不可见对于单纯常量,最好以const对象或者enums替换#define
对于形似函数的宏,最好改用inline函数替换#define -
条款03:尽可能使用const
将某些东西声明为const可以帮助编译器检测出错误用法。const可被加于任何作用域内的对象、函数参数、函数返回类型,成员函数本体。
编译器强制实施 bitwise constness(数据意义的 const), 但你编写程序时应该使用概念上的常量性 conceptual constness(逻辑上的const)
当const和no-const成员函数有着实质等价的实现时,令non-const版本调用const版本可以避免代码重复
代码演示:
#include<iostream>
using namespace std;
class A {
public :
A() { x = 123; y = 0; }
void say() const {//当前函数的内部,不修改任何成员属性的:逻辑上的const
cout << y << endl;
y += 1;
}
void say2() {
x += 5;
cout << x << endl;
}
int x;
mutable int y;//可变量,const中他可以改变,其他不可以
};
int main() {
const int a = 1;//a是数据意义上的const,但是真正数据意义上的const很难实现
//我们可以通过指针指向该存储区的内容改掉
//a = 3;
const A aa;
aa.say();
aa.say2();//报错const类型的对象,只能调用const类型的方法,因为会可能修改对象里面的内容,本行代码无法执行
return 0;
}
-
条款04:确定对象被使用前已经先被初始化
为内置型对象进行手工初始化,因为C++并不保证会初始化他们。构造函数最好使用成员初值列,而不要在构造函数本体内使用赋值操作。
初值列列出的成员变量,其排列次序应该和他们在class中的声明次序相同
为免除“跨编译单元之初始化次序”问题,请以local static对象替换non-local static
课后作业
- nth_element()自学笔记
/*
nth-element, 位于algorithmit头文件库下面的函数
函数定义:
template< class RandomIt, class Compare >
void nth_element( RandomIt first, RandomIt nth, RandomIt last,
Compare comp );
nth_element 对[first, last)这个左闭右开的区间进行一个局部排序的函数,排序结果为在RandomIt中,在first 与 last之间 nth的位置,是他应该出现的数字
排序之后,左面都不大于,右面都不小于
comp为比较函数,如果不选择为从小到大
first 与 nth 与 last均为迭代器
局部排序之后第n位为first 到 last之间从小到大排在第n位的数字
时间复杂度位O(n)
*/
#include<iostream>
#include <algorithm>
#include <time.h>
#include <vector>
using namespace std;
vector<int> a;
void init_arr() {
for (int i = 0; i < 10; i++) {
a.push_back(rand() % 100);
}
return ;
}
void print() {
for (int i = 0; i < 10; i++) {
cout << a[i] << " ";
}
cout << endl;
return ;
}
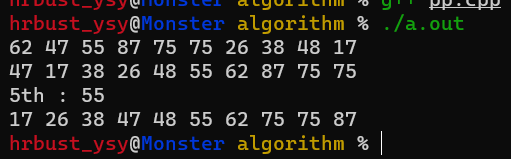
int main() {
srand(time(0));
init_arr();
print();
nth_element(a.begin(), a.begin() + 5, a.end());
print();
cout << "5th : " << *(a.begin() + 5) << endl;
sort(a.begin(), a.begin() + a.size());
print();
return 0;
}
- string类的学习
-
basic_string substr( size_type pos = 0, size_type count = npos ) const;该函数返回一个新的字符串,新字符串从原字符串的pos 位置开始截取,直到截取到初始位置的后n个字符(下一个参数),如果
pos + n > str.length()那么截取从pos 到str字符串的结尾。
-
#include<iostream>
#include <algorithm>
#include <time.h>
#include <vector>
#include <string>
using namespace std;
string str("I see your Monster, I see your pain!");
int main() {
string new_str = str.substr(str.find("Monster"), 7);
cout << new_str << endl;
return 0;
}
-
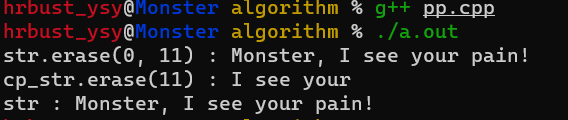
basic_string& erase( size_type index = 0, size_type count = npos );该函数删除,从该字符串中的pos位置开始,向后count区间的子符,如果 p o s + c o u n t > s t r . s i z e ( ) pos + count > str.size() pos+count>str.size() ,那么删除从pos 到结尾
如果只传了index参数,也就是只传一个参数,而未传count参数,则函数删除index后面所有的内容
#include<iostream>
#include <algorithm>
#include <time.h>
#include <vector>
#include <string>
using namespace std;
string str("I see your Monster, I see your pain!");
int main() {
string cp_str = str;
cout << "str.erase(0, 11) : " << str.erase(0,11) << endl;
cout << "cp_str.erase(11) : " << cp_str.erase(11) << endl;
cout << "str : " << str << endl;
return 0;
}
3.
basic_string& replace( const_iterator first, const_iterator last,
const basic_string& str );
basic_string& replace( size_type pos, size_type count,
const basic_string& str );
replace函数,将从pos 开始往后 count个字符,替换成str字符,如果count 越过npos 那么count自动为npos,函数重载,适用于迭代器.
#include<iostream>
#include <algorithm>
#include <time.h>
#include <vector>
#include <string>
using namespace std;
string str("I see your Monster, I see your pain!");
int main() {
cout << str.replace(str.rfind("see"), 3, "warm") << endl;;
return 0;
}

4. rfind
void reserve( size_type new_cap = 0 );
寻找等于给定字符序列的最后子串。搜索始于 pos ,即找到的子串必须不始于 pos 后的位置。若将 npos 或任何不小于 size()-1 的值作为 pos 传递,则在整个字符串中搜索。
- 寻找等于 str 的最后子串。
- 寻找等于范围 [s, s+count) 的最后子串。此范围能包含空字符。
- 寻找等于 s 所指向的字符串的最后子串。由首个空字符,用 Traits::length(s) 确定字符串长度。
- 寻找等于 ch 的最后字符。
#include<iostream>
#include <algorithm>
#include <time.h>
#include <vector>
#include <string>
using namespace std;
string str("I see your Monster, I see your pain!");
int main() {
int n = str.rfind("see");
cout << n << endl;
cout << str.substr(n) << endl;
return 0;
}

- oj287.讨论合并果子和哈夫曼编码之间的关系
在合并果子题目中,为了让体力最少,我们可以让每次选择最轻的两堆,然后将最轻的两堆合并,然后每次都选择最轻的,这样合并到最后一堆的时候,就可以让所消耗体力为最少的
每次取最少
看哈夫曼树的建立:
- 每一次从集合中选出两个概率最低的节点,将他们合并成一棵子树
- 将新生成的节点,放回到原集合中
所以可以得出,哈夫曼树的建立与合并果子中最少体力方案相同
哈夫曼编码即为合并果子题目背后的隐身
两者不能说完全相似,间直是一模一样。
#include <iostream>
#include <queue>
using namespace std;
priority_queue<int, vector<int>, greater<int> > q;
int main() {
int n;
cin >> n;
for (int i = 0, a; i < n; i++) {
cin >> a;
q.push(a);
}
int sum = 0;
while (q.size() != 1) {
int q1 = q.top();
q.pop();
int q2 = q.top();
q.pop();
q.push(q1 + q2);//选体力最少的两个堆
sum += q1 + q2;
}
cout << sum << endl;
return 0;
}















 1547
1547











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









