






文章目录
1、前言
**简介:**ES全称:Elasticsearch,是一个基于Lucene库的搜索引擎。它提供了一个分布式、支持多租户的全文搜索引擎,具有HTTP Web接口和无模式JSON文档。Elasticsearch是用Java开发的,并在Apache许可证下作为开源软件发布。
Elasticsearch官网:https://www.elastic.co/cn/products/elasticsearch
2、Linux下安装Elasticsearch(生产环境使用)
2.1、下载和解压安装包
- 官网下载地址: https://www.elastic.co/cn/downloads/elasticsearch
选择合适的版本下载,然后上传到Linux中
- 也可以在Linux命令行,直接执行以下命令进行下载(下载比较慢):
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.17.5-linux-x86_64.tar.gz
- 执行解压缩命令:
tar -zxvf elasticsearch-7.17.5-linux-x86_64.tar.gz -C /Data
2.2、解决es强依赖jdk问题
由于es和jdk是一个强依赖的关系,所以当我们在新版本的ElasticSearch压缩包中包含有自带的jdk,但是当我们的Linux中已经安装了jdk之后,就会发现启动es的时候优先去找的是Linux中已经装好的jdk,此时如果jdk的版本不一致,就会造成jdk不能正常运行,报错如下:
warning: usage of JAVA_HOME is deprecated, use ES_JAVA_HOME
Future versions of Elasticsearch will require Java 11; your Java version from [/usr/local/jdk1.8.0_291/jre] does not meet this requirement. Consider switching to a distribution of Elasticsearch with a bundled JDK. If you are already using a distribution with a bundled JDK, ensure the JAVA_HOME environment variable is not set.
解决办法:
- 进入bin目录
cd /Data/elasticsearch-7.17.5
- 修改elasticsearch配置
vim ./elasticsearch
############## 添加配置解决jdk版本问题 ##############
# 将jdk修改为es中自带jdk的配置目录
export JAVA_HOME=/usr/local/elasticsearch-7.17.5/jdk
export PATH=$JAVA_HOME/bin:$PATH
if [ -x "$JAVA_HOME/bin/java" ]; then
JAVA="/usr/local/elasticsearch-7.17.5/jdk/bin/java"
else
JAVA=`which java`
fi
2.3、解决内存不足问题
由于 elasticsearch 默认分配 jvm空间大小为2g,修改 jvm空间,如果Linux服务器本来配置就很高,可以不用修改。
error:
OpenJDK 64-Bit Server VM warning: INFO: os::commit_memory(0x00000000c6a00000, 962592768, 0) failed; error='Not enough space' (errno=12)
at org.elasticsearch.tools.launchers.JvmOption.flagsFinal(JvmOption.java:119)
at org.elasticsearch.tools.launchers.JvmOption.findFinalOptions(JvmOption.java:81)
at org.elasticsearch.tools.launchers.JvmErgonomics.choose(JvmErgonomics.java:38)
at org.elasticsearch.tools.launchers.JvmOptionsParser.jvmOptions(JvmOptionsParser.java:13
进入config文件夹开始配置,编辑jvm.options:
vim /Data/elasticsearch-7.17.5/config/jvm.options
默认配置如下:
-Xms2g
-Xmx2g
默认的配置占用内存太多了,调小一些:
-Xms256m
-Xmx256m
2.4、创建专用用户启动ES
root用户不能直接启动Elasticsearch,所以需要创建一个专用用户,来启动ES
报错如下:
java.lang.RuntimeException: can not run elasticsearch as root
at org.elasticsearch.bootstrap.Bootstrap.initializeNatives(Bootstrap.java:101)
at org.elasticsearch.bootstrap.Bootstrap.setup(Bootstrap.java:168)
at org.elasticsearch.bootstrap.Bootstrap.init(Bootstrap.java:397)
at org.elasticsearch.bootstrap.Elasticsearch.init(Elasticsearch.java:159)
at org.elasticsearch.bootstrap.Elasticsearch.execute(Elasticsearch.java:150)
at org.elasticsearch.cli.EnvironmentAwareCommand.execute(EnvironmentAwareCommand.java:75)
at org.elasticsearch.cli.Command.mainWithoutErrorHandling(Command.java:116)
at org.elasticsearch.cli.Command.main(Command.java:79)
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:115)
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:81)
- 创建用户
useradd user-es
- 创建所属组:
chown user-es:user-es -R /Data/elasticsearch-7.17.5
2.5 修改ES核心配置信息
- 执行命令修改elasticsearch.yml文件内容
vim /Data/elasticsearch-7.17.5/config/elasticsearch.yml
- 修改数据和日志目录
这里可以不用修改,如果不修改,默认放在elasticsearch根目录下
# 数据目录位置
path.data: /自定义路径/data
# 日志目录位置
path.logs: /自定义路径/logs
- 修改绑定的ip允许远程访问
#默认只允许本机访问,修改为0.0.0.0后则可以远程访问
# 绑定到0.0.0.0,允许任何ip来访问
network.host: 0.0.0.0
- 初始化节点名称
cluster.name: elasticsearch
node.name: es-node0
cluster.initial_master_nodes: ["es-node0"]
- 禁用 HTTPS 并启用 HTTP
xpack.security.enabled: false
- 修改端口号(非必须)
http.port: 19200
2.6、vm.max_map_count [65530] is too low问题
上面几个步骤依然没启动成功,继续解决问题:
若报错如下:
ERROR: [1] bootstrap checks failed. You must address the points described in the following [1] lines before starting Elasticsearch.
bootstrap check failure [1] of [1]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
elasticsearch用户拥有的内存权限太小,至少需要262144,解决办法:
在 /etc/sysctl.conf 文件最后添加如下内容,即可永久修改
-
切换到root用户,执行命令:
su root -
执行命令
vim /etc/sysctl.conf -
添加如下内容
vm.max_map_count=262144 -
保存退出,刷新配置文件
sysctl -p -
切换user-es用户,继续启动
su user-es -
启动es服务
/Data/elasticsearch-7.17.5/bin/elasticsearch
启动成功后,可以通过http://127.0.0.1:19200/ 访问,如果出现以下内容,说明ES安装成功:
{
"name" : "node-1",
"cluster_name" : "my-application",
"cluster_uuid" : "3Pa3RhK_Q6qoZQxlPYg4zw",
"version" : {
"number" : "7.17.5",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "8d61b4f7ddf931f219e3745f295ed2bbc50c8e84",
"build_date" : "2022-06-23T21:57:28.736740635Z",
"build_snapshot" : false,
"lucene_version" : "8.11.1",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
2.7、可能遇到的max file descriptors [4096]问题
[1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65535]
- 切换到root用户,执行命令:
vi /etc/security/limits.conf
添加如下内容:
* soft nofile 65536
* hard nofile 65536
* soft nproc 65536
* hard nproc 65536
2.8、 ES服务的启动与停止
-
前台运行,Ctrl + C 则程序终止
/usr/local/elasticsearch-7.13.2/bin/elasticsearch -
后台运行
/usr/local/elasticsearch-7.13.2/bin/elasticsearch -d -
出现started时启动完成
-
关闭ES服务
kill pid -
说明:
Elasticsearch端口9300、9200,其中:
9300是tcp通讯端口,集群ES节点之间通讯使用,9200是http协议的RESTful接口
2.9、为Elasticsearch设置登录密码
ES7.x以后的版本将安全认证功能免费开放了,并将X-pack插件集成了到了开源的ElasticSearch版本中。下面将介绍如何利用X-pack给ElasticSearch相关组件设置用户名和密码。
-
编辑配置文件
vim /Data/elasticsearch-7.17.5/config/elasticsearch.yml -
在 elasticsearch.yml 末尾,加入以下内容:
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
-
编辑内容后重启Elasticsearch服务(必须操作)
-
设置用户名和密码
/Data/elasticsearch-7.17.5/bin/elasticsearch-setup-passwords interactive
这里依次设置elastic、kibana、logstash等的访问密码,test123
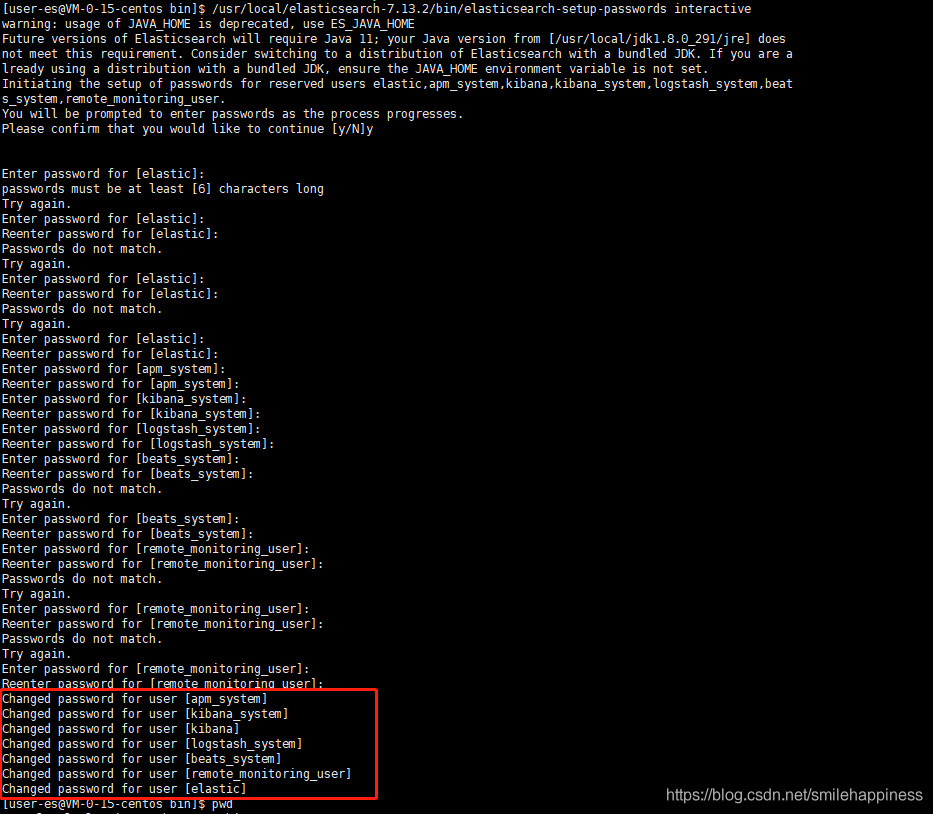
- 设置了访问密码,再次访问ES时,需要输入密码
3、Linux下安装Kibana(生产环境使用)
3.1、Kibana是什么?
Kibana 是为 Elasticsearch设计的开源分析和可视化平台。你可以使用 Kibana 来搜索,查看存储在 Elasticsearch 索引中的数据并与之交互。你可以很容易实现高级的数据分析和可视化,以图表的形式展现出来。
使用前我们肯定需要先有Elasticsearch啦,安装使用Elasticsearch可以参考Elasticsearch构建全文搜索系统
下面分别演示一下Kibana的安装、自定义索引,搜索,控制台调用es的api和可视化等操作,特别需要注意的是,控制台可以非常方便的来调用es的api,强烈推荐使用
kibaba下载地址:
https://www.elastic.co/guide/en/kibana/current/install.html
3.2、kibana环境搭建
- 建议下载和es相同版本号的kibana,下载2完成后进行解压:
tar -zxvf /Data/kibana-7.17.5-linux-x86_64.tar.gz
配置可以参考:https://www.elastic.co/guide/cn/kibana/current/settings.html
- 设置监听端口号、es地址、索引名
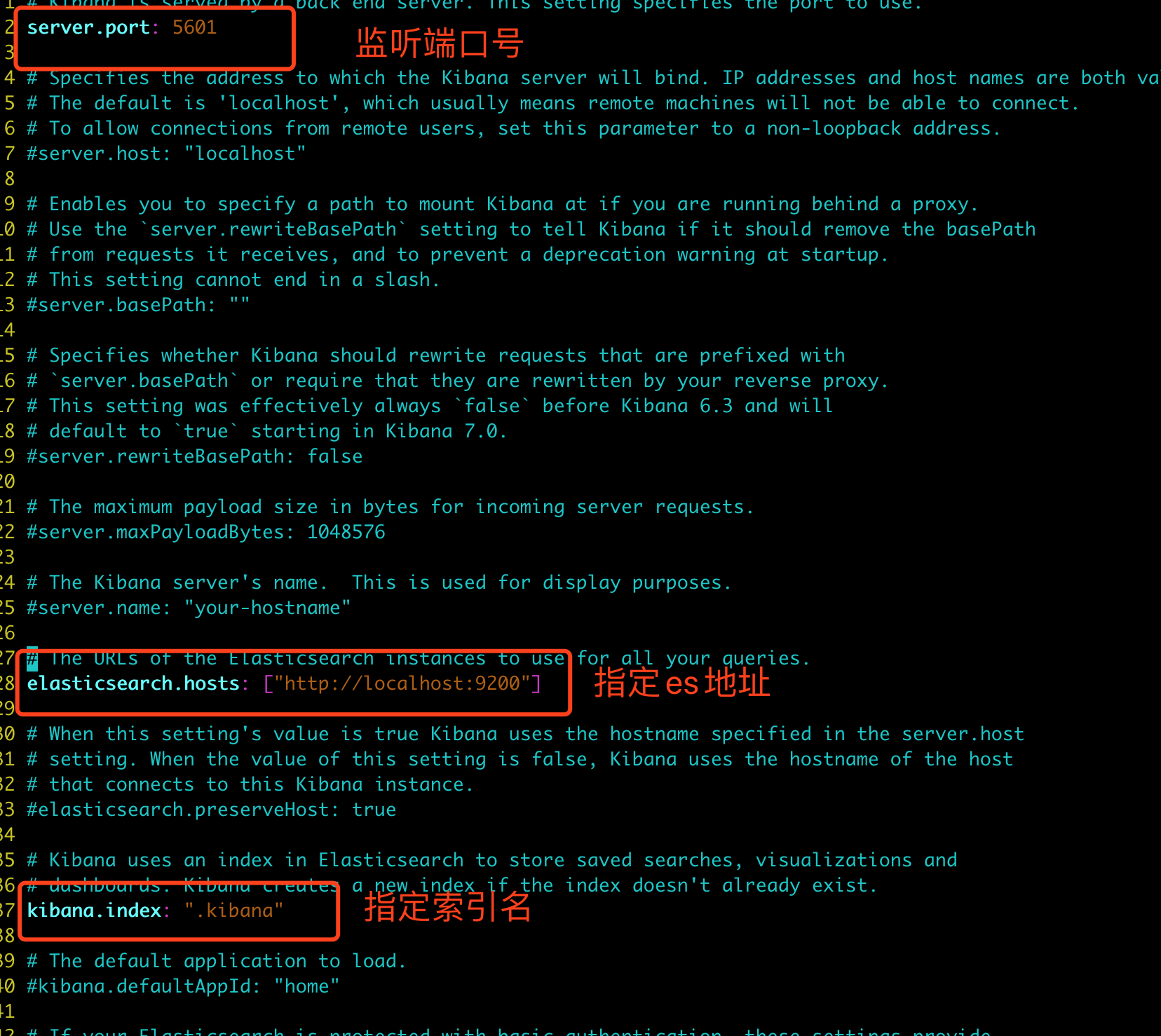
- 默认情况下,kibana启动时将生成随机密钥,这可能导致重新启动后失败,需要配置多个实例中有相同的密钥
- 设置
xpack.reporting.encryptionKey: "dxl"
xpack.security.encryptionKey: "122333444455555666666777777788888888"
xpack.encryptedSavedObjects.encryptionKey: "122333444455555666666777777788888888"
- 启动
./bin/kibana
打开http://localhost:5601 ,画风如下
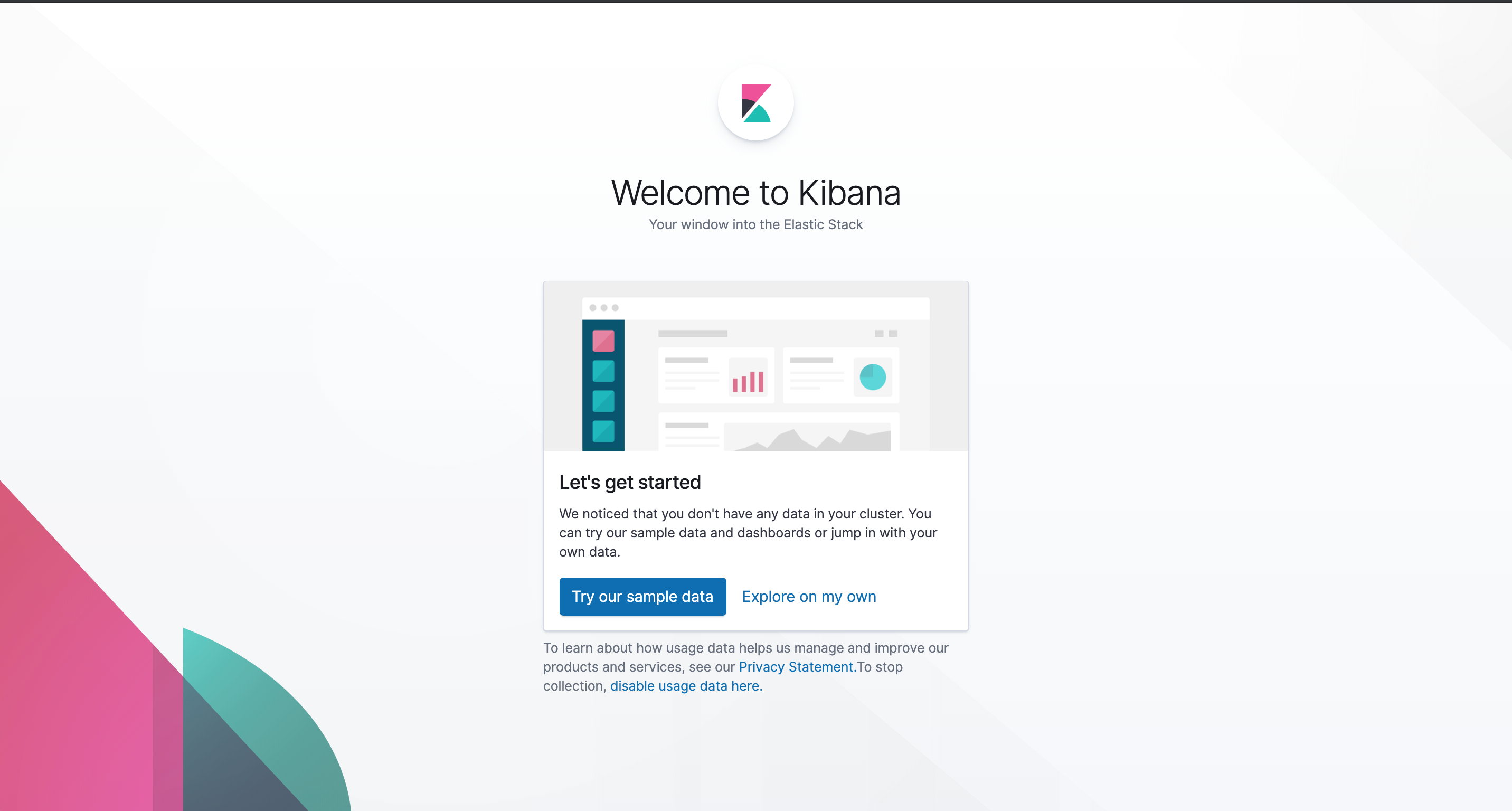
说明kibana已经安装成功
3、ES整合ik中文分词器
Lucene的IK分词器早在2012年已经没有维护了,现在我们要使用的是在其基础上维护升级的版本,并且开发为ElasticSearch的集成插件了,与Elasticsearch一起维护升级,版本也保持一致,最新版本:8.12.0
官方提供的 ik 和 ES的对应版本关系:
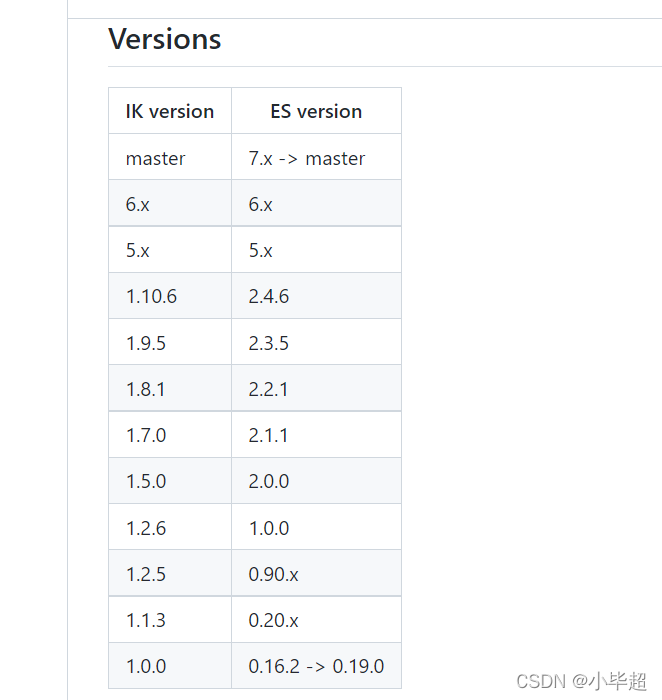
- ik 的分词粒度:
ik_max_word:会将文本做最细粒度(拆到不能再拆)的拆分,例如「中华人民共和国国歌」会被拆分为「中华人民共和国、中华人民、中华、华人、人民共和国、人民、人、民、共和国、共和、和、国国、国歌」,会穷尽各种可能的组合
ik_smart:会将文本做最粗粒度(能一次拆分就不两次拆分)的拆分,例如「中华人民共和国国歌」会被拆分为「中华人民共和国、国歌」
3.1、安装
ik是基于java开发的轻量级的中文分词工具包。它是以开源项目Luence为主体的,结合词典分词和文法分析算法的中文分词组件。
-
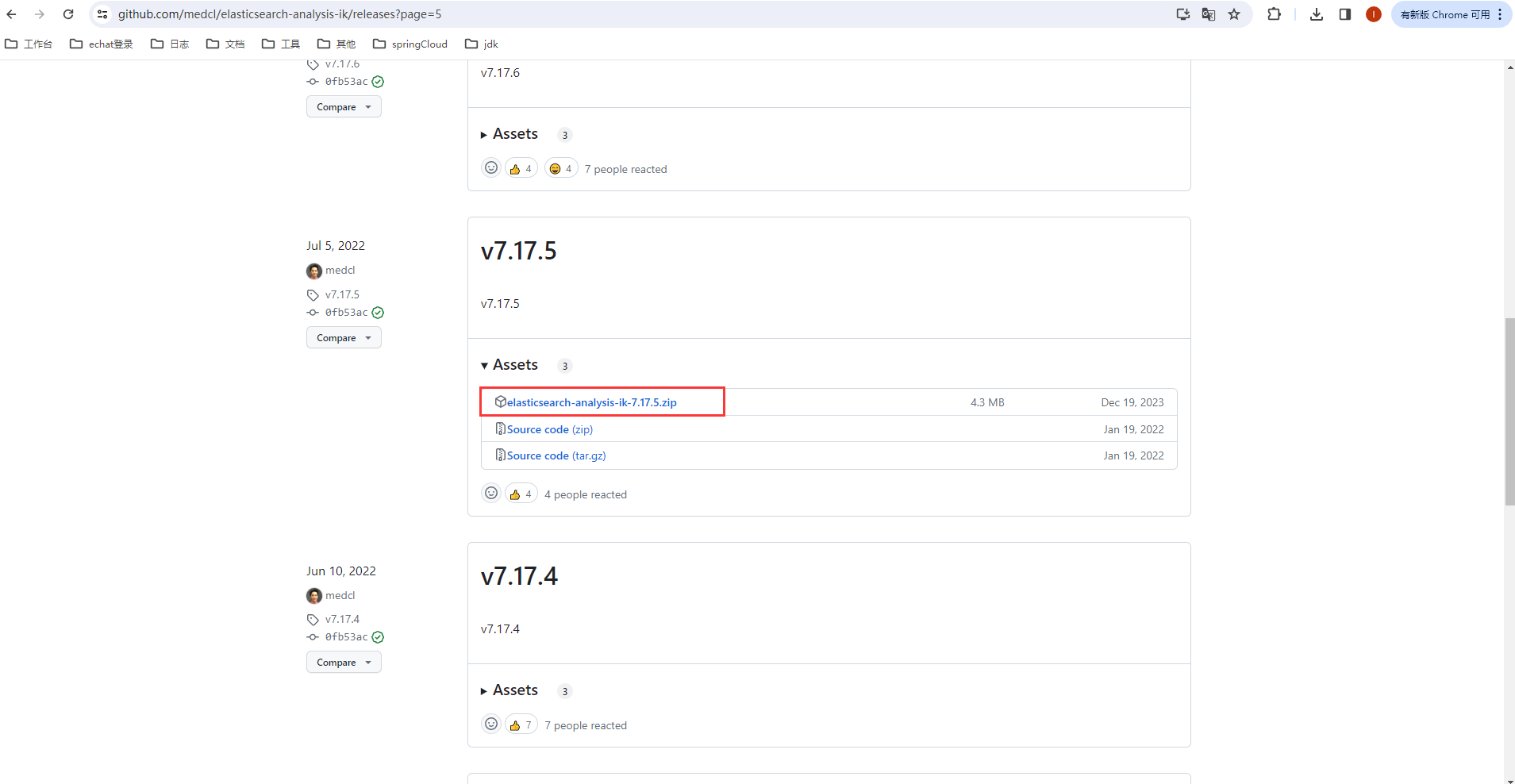
下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
-
我们选用的是ES 7.17.5 版本的,所以这里要下载 7.17.5 的 ik:
- 下载完成后,新建ik目录,并将解压后的文件放在ik目录下
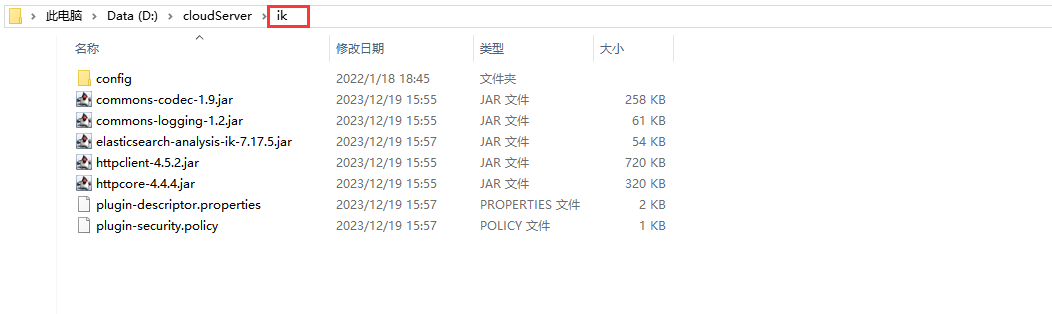
- 下面将
ik目录复制到es安装目录的plugins目录下:

重新启动 es:
下面在kibana上发送Get请求:
- ik_max_word 细粒度分词
GET _analyze
{
"text": "人民共和国",
"analyzer":"ik_max_word"
}
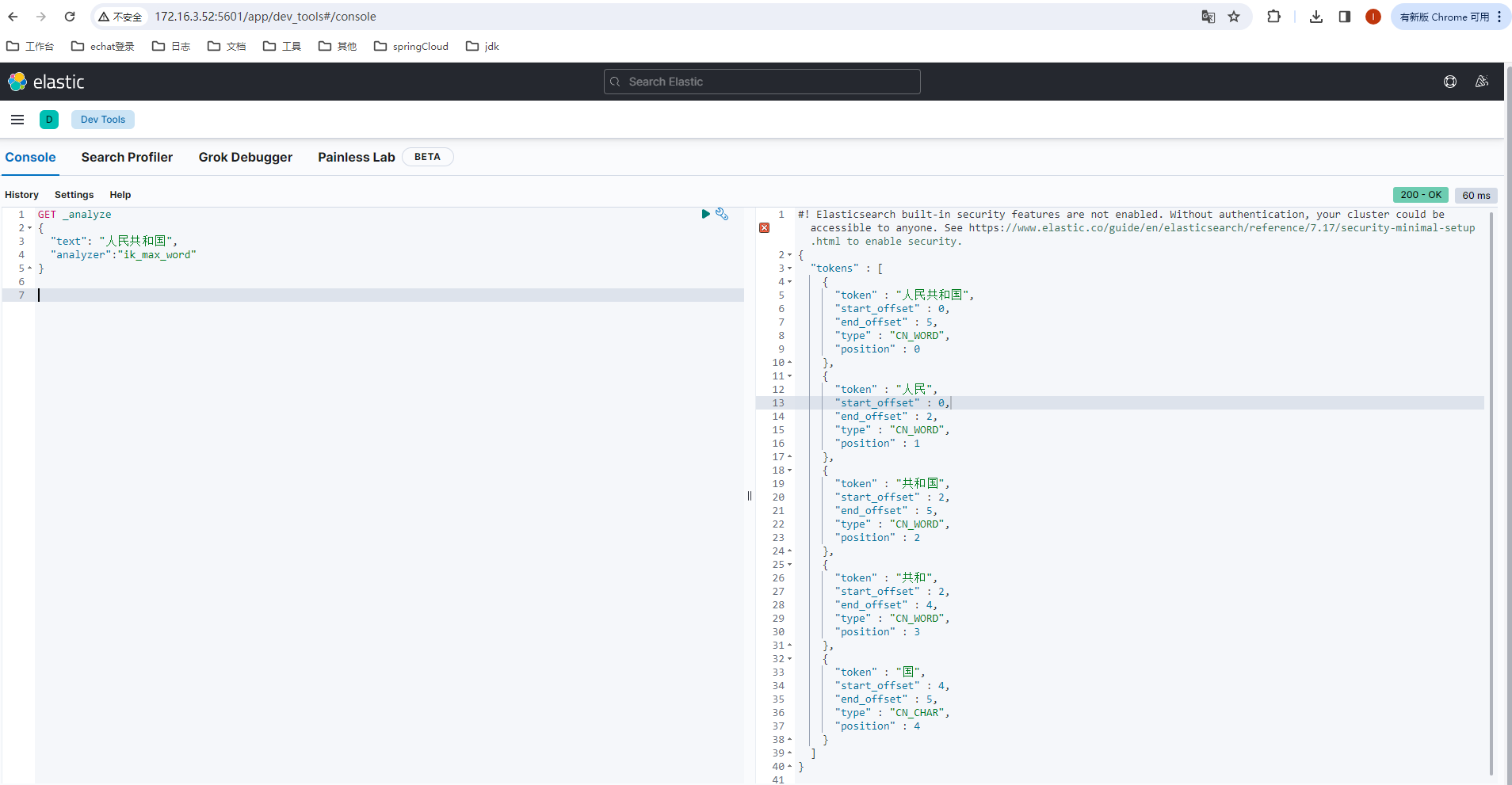
已经不是以前的一个中文就是一个词了,下面再测试下 ik_smart 的效果:
- ik_smart 粗粒度分词
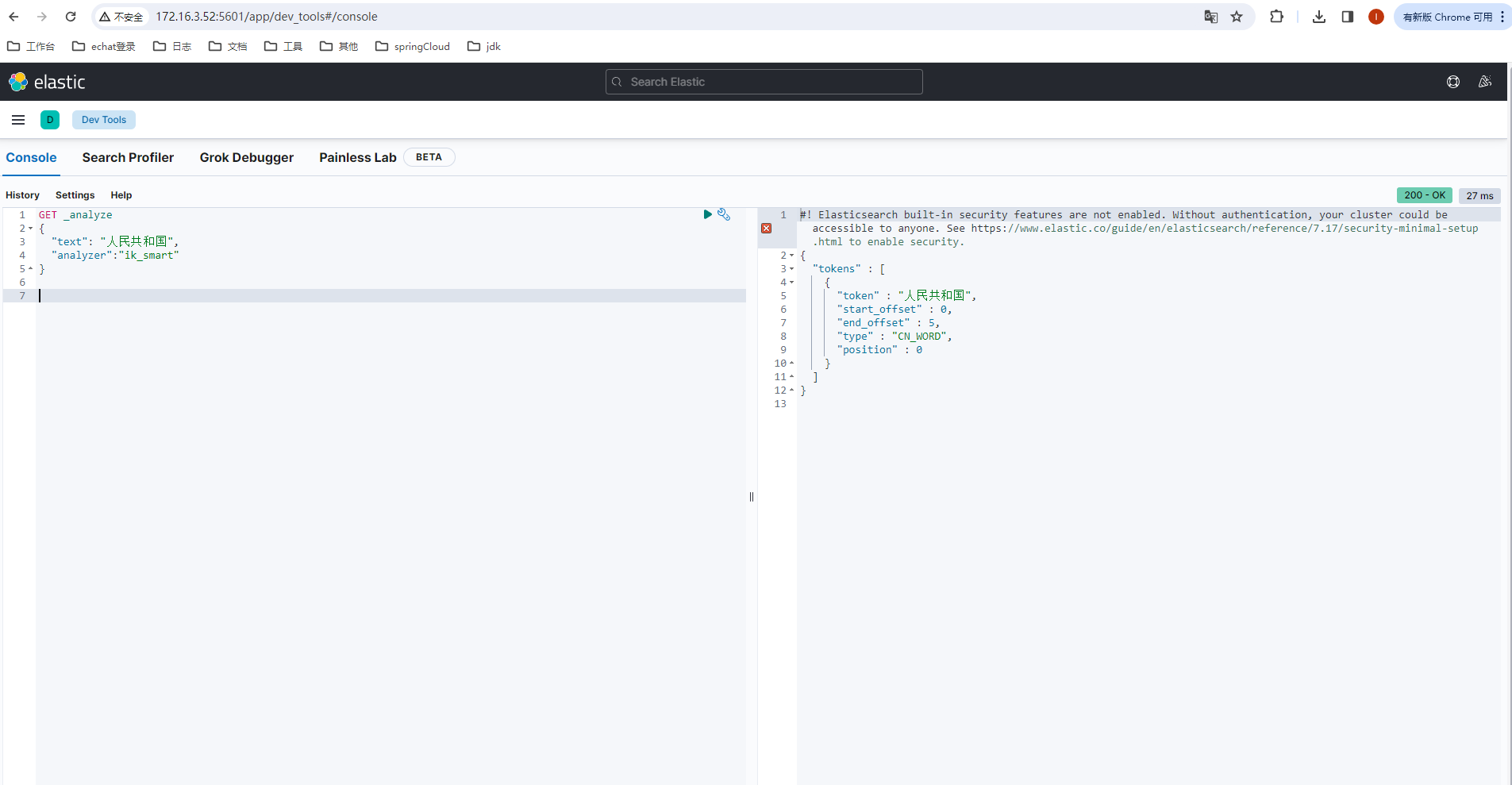
现在就已经成功使用了,ik中文分词器。
3.2、ik 扩展词汇
上面已经使用了ik分词器,已经有了分词效果,但是再对一些名词进行分词时,会怎么样的,如果测试下:德玛西亚 这个词,我们希望作为一个整体分词,下面看下结果:
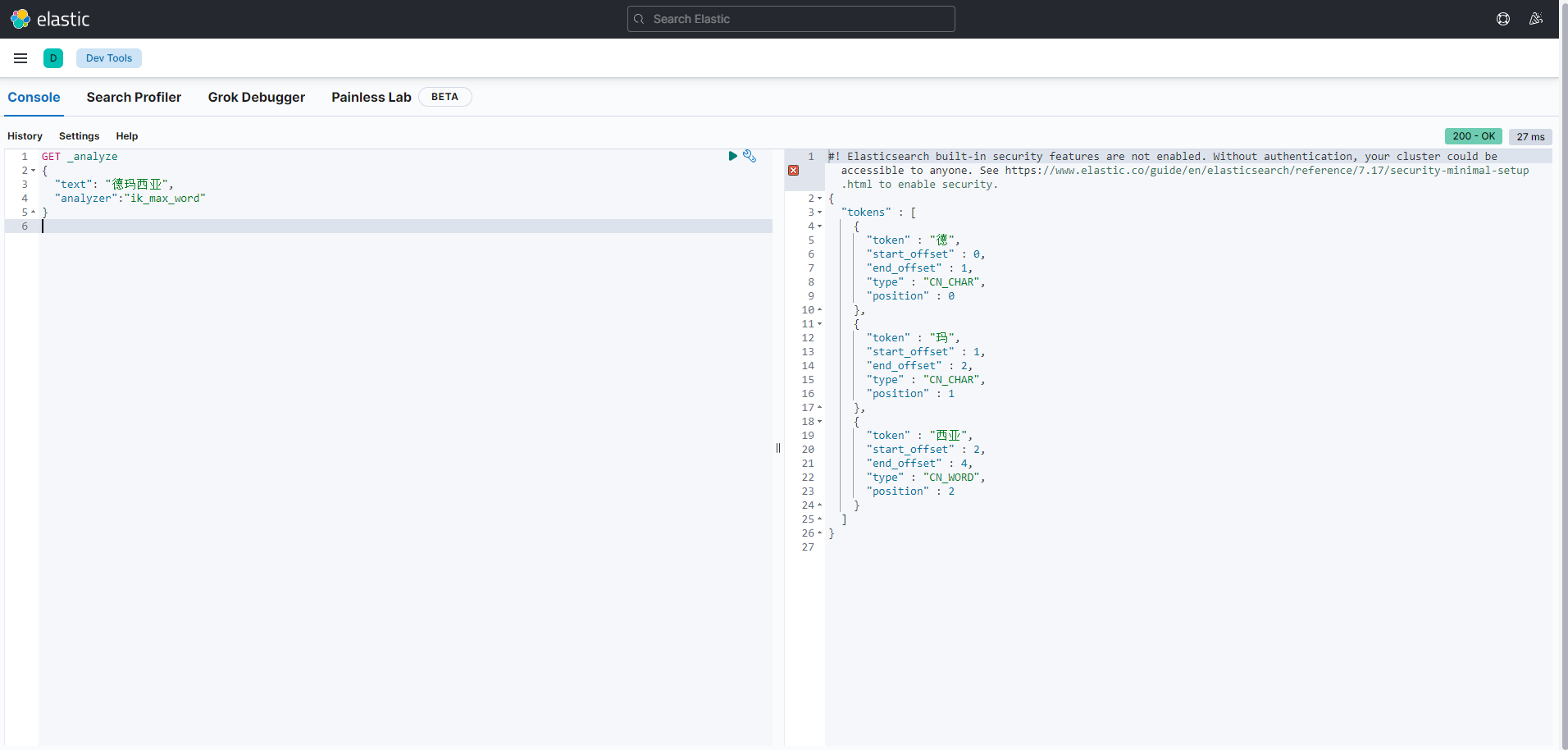
可以看到将德玛西亚 这个词给分开了,这是由于Ik自带的分词库中并没有这个名词,所以就不知道怎么分了,此时,我们就可以进行扩展词汇:
首先进入es安装目录,进入plugins\ik\config 目录下,创建 custom.dic 文件,内容我们写入:德玛西亚
下面修改plugins\ik\config\IKAnalyzer.cfg.xml文件:
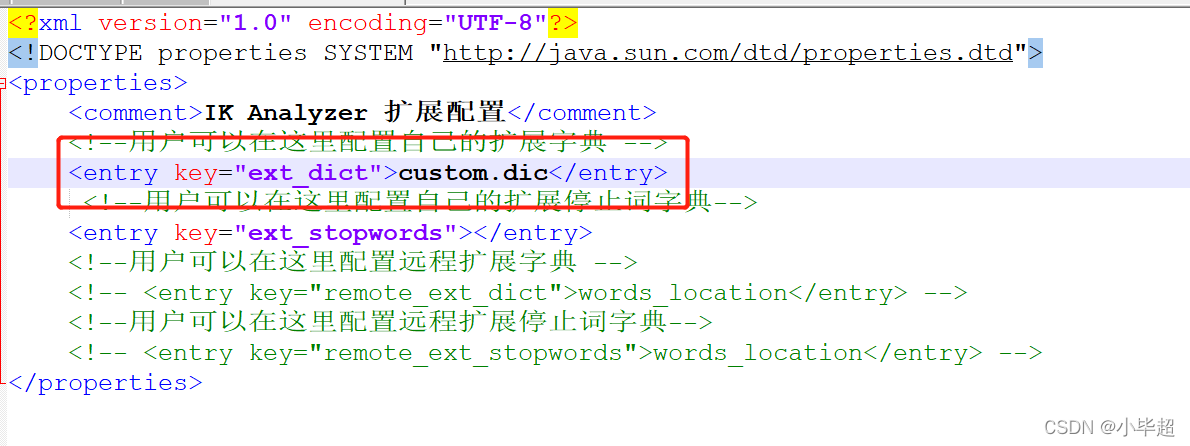
下面再来做上面的请求:
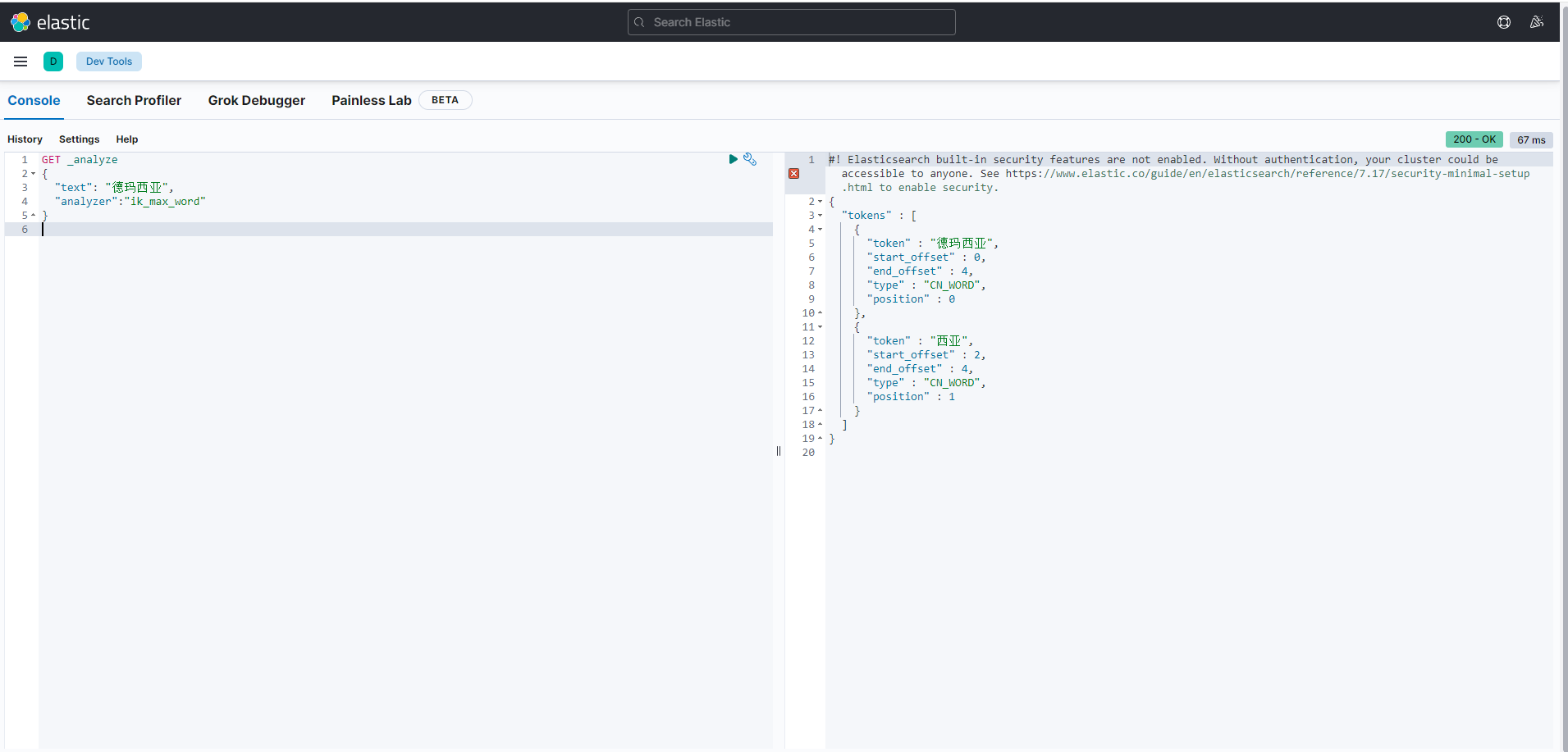
已经分词出了德玛西亚这个词语。
上面已经实现对词库的扩展,但是会发现一个弊端,就是一旦扩展后就需要重启es使扩展词汇生效,如果使生产环境怎么能随便对es进行重启呢,对此es提供了远程词汇的方式,我们对远程词汇文件进行修改,es每次都以http请求的方式获取分词,但要符合两个条件:
该 http 请求需要返回两个头部(header),一个是 Last-Modified,一个是 ETag,这两者都是字符串类型,只要有一个发生变化,该插件就会去抓取新的分词进而更新词库。
该 http 请求返回的内容格式是一行一个分词,换行符用 \n 即可。
满足上面两点要求就可以实现热更新分词了,不需要重启 ES 实例。
对此,官方也给出了方案,就是将分词文件放在nginx中,当文件被修改nginx自动返回相应的 Last-Modified 和 ETag:

下面我们根据官方的方案进行实现下,首先新建一个 ik_dict.txt ,写入以下内容:
德玛西亚
弗雷尔卓德
小毕超
-
然后将该文件放在nginx的静态资源目录下
-
然后启动nginx,访问http://192.168.0.114:8080/ik_dict.txt ,注意修改为自己的ip:
然后修改es安装目录下 /plugins/ik/config/IKAnalyzer.cfg.xml文件:
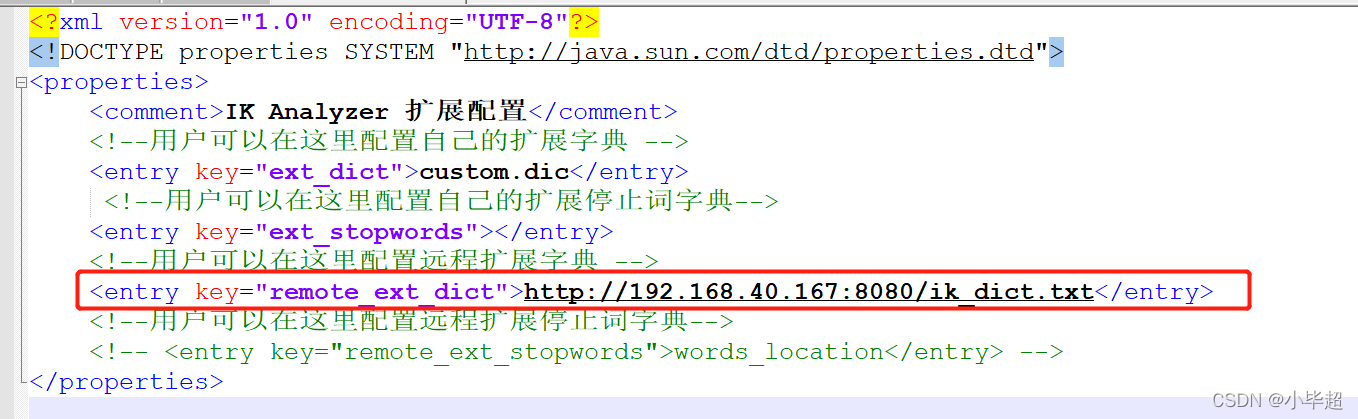
然后重启es,测试效果:
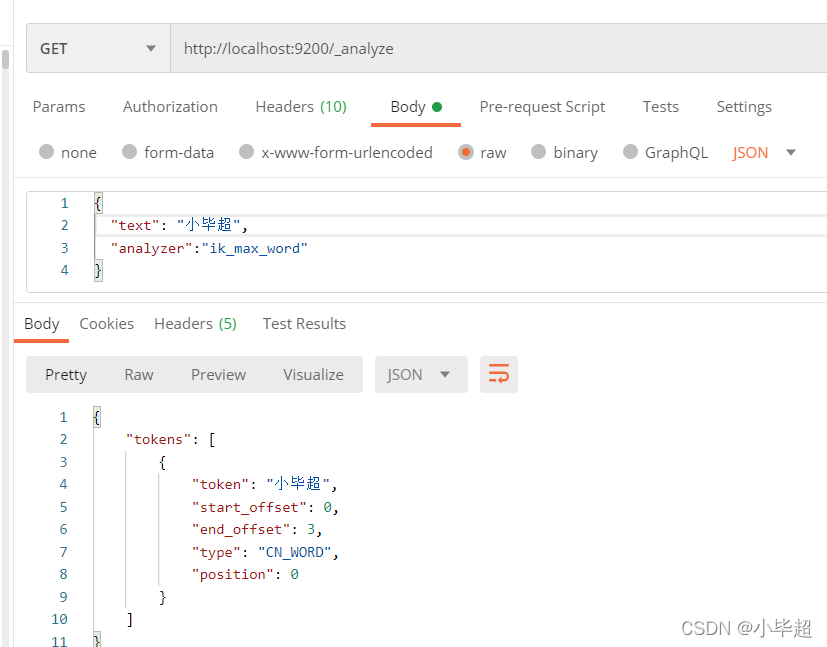
由于我们在远程库中配制了小毕超所以这里可以分析出来。
下面测试下没有配制的词语,比如果粒橙这个词语:
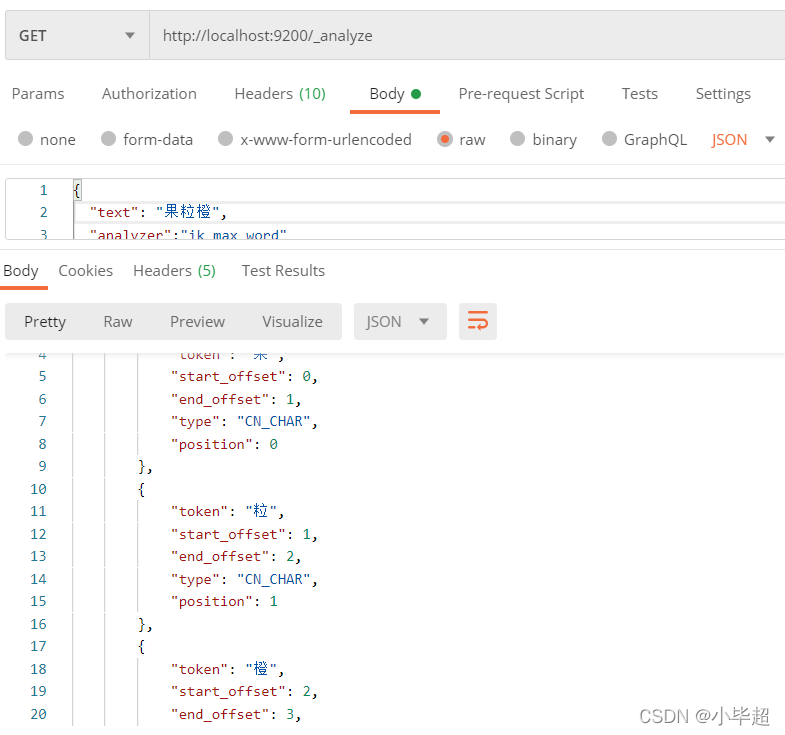
现在是一个字算了一个词语,下面我们修改ik_dict.txt文件:
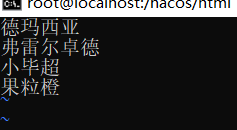
再来请求下:
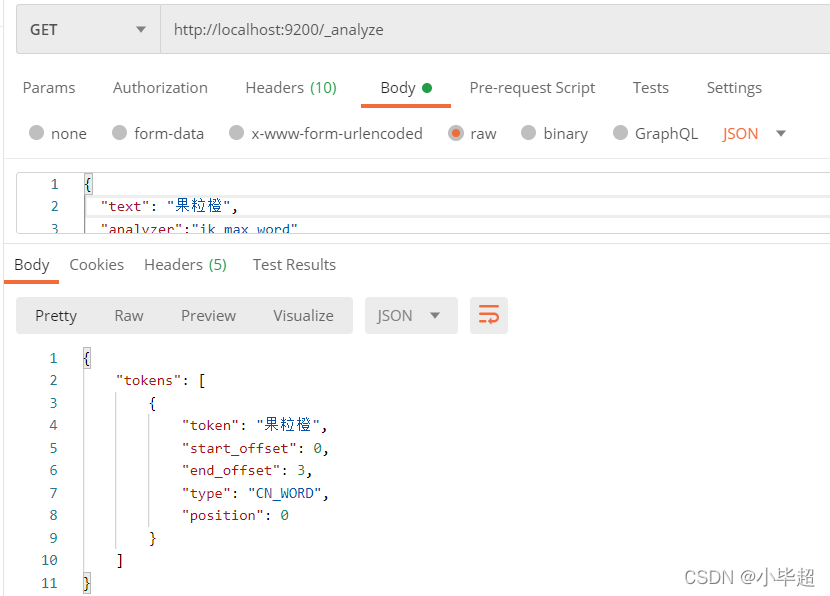
此时就实现了,无需重启es,热更新词库的效果了。
3.3、扩展 - 更新历史索引
上面已经实现了动态词库的效果,上面使用的都是直接使用分词器进行测试的,在实际使用中不可能这样做的,都是去查询数据的,所以这里就会出现一个问题。
在我们自定义拓展词库更改后,在原先的索引文档中,由于不是新插入的数据,所以其倒排索引列表还是原先的分词列表数据,导致就算拓展了词库,新增的分词也没有生效。在不重新导入数据的前提下,处理办法如下:
通过_update_by_query去更新匹配的文档,如果没有指定查询,那么就会在每个文档上执行更新:
向es服务器发送POST请求:
http://172.16.3.52:9200/user/_update_by_query?conflicts=proceed
其中user为索引名称,conflicts表示如果更新过程中发生异常冲突时如何处理,有两种方案:
abort:中止(默认)
proceed:继续执行
注意更新索引,会影响线上的es的 qps,尽量选择夜深人静的时候进行更新。
注意!!!
这里只介绍了IK中文分词器的使用,ES还可以与其他更多的分词器结合使用,如:拼音分词器,英文分词器等等,需要时可以进行自由扩展。
4、ES的原理及其使用:
4.1、ES概念
4.1.1、 ES
ElasticSearch又称ES,是一个开源的高扩展的分布式全文搜索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理 PB 级别的数据。Elasticsearch是面向文档型数据库,一 条数据在这里就是一个文档。
全文搜索引擎指的是目前广泛应用的主流搜索引擎。它的工作原理是计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。
下图是ES和MySQL中一些概念的对应,其中type的概念已经被弱化,在ES 7.X之后被删除。
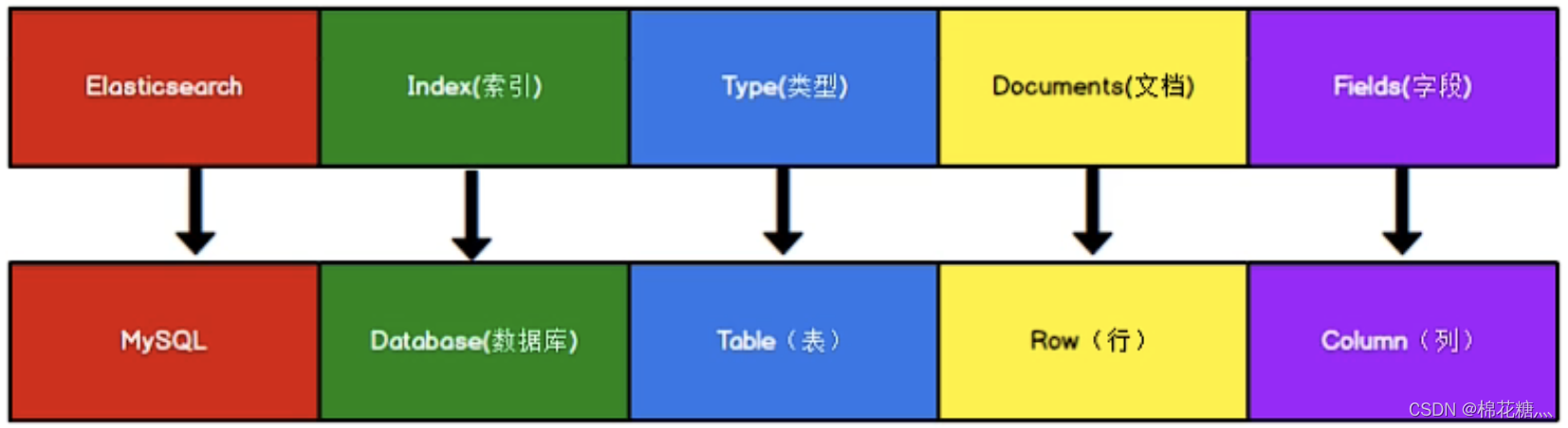
4.1.2、index(索引)
一个索引就是一个拥有几分相似特征的文档的集合。一个索引由一个名字来标识(必须全部是小写字母),并且当我们要对这个索引中的文档进行索引、搜索、更新和删除(CRUD)的时候,都要使用到这个名字。在一个集群中,可以定义任意多的索引。相当于MySQL中的数据库。
4.1.3、 type(类型)
一个索引中可以定义一种或多种类型。一个类型是索引的一个逻辑上的分类/分区,其语义完全由你来定。相当于MySQL中的表。
4.1.4、 document(文档)
一个文档是一个可被索引的基础信息单元,也就是一条数据。相当于MySQL中的一条记录。
4.1.5、 field(字段)
相当于是数据表的字段,对文档数据根据不同属性进行的分类标识。相当于MySQL中表的字段。
4.1.6、 mapping(映射)
mapping是处理数据的方式和规则方面做一些限制,如某个字段的数据类型、默认值、分析器、是否被索引等等。相当于MySQL中的建表过程中设置默认值、主外键、索引等。
4.1.7、 cluster(集群)
4.1.8、 node(节点)
一个节点是集群中的一个服务器,作为集群的一部分,它存储数据,参与集群的索引和搜索功能。
4.1.9、 shard(分片)
Elasticsearch提供了将索引划分成多份的能力,这些份就叫做分片。它允许水平分割/扩展你的内容容量,或者在多个节点上上进行分布式的、并行的操作,进而提高性能/吞吐量。
分片很重要,主要有两方面的原因:
- 允许你水平分割扩展你的内容容量
- 允许你在分片之上进行分布式的、并行的操作,进而提高性能/吞吐量
4.1.10、 replicas(副本)
Elasticsearch允许你创建分片的一份或多份备份,这些备份叫做复制分片,或者直接叫副本。
复制分片之所以重要,有两个主要原因:
-
在分片/节点失败的情况下,提供了高可用性
-
扩展你的搜索量/吞吐量,因为搜索可以在所有的副本上并行运行
4.1.11、 allocation(分配)
将分片分配给某个节点的过程,包括分配主分片或者副本。如果是副本,还包含从主分片复制数据的过程。这个过程是由master节点完成的。
4.2、ES原理
4.2.1、 倒排索引
(1) 正向索引
词条:索引中最小存储和查询单元
词典:字典,词条的集合,具体实现有B+树、HashMap等
Elasticsearch使用一种称为倒排索引的结构,它适用于快速的全文搜索。有倒排索引,肯定会对应有正向索引(forward index)。倒排索引也称反向索引(inverted index)。所谓的正向索引,就是搜索引擎会将待搜索的文件都对应一个文件ID,搜索时将这个ID和搜索关键字进行对应,形成K-V对,然后对关键字进行统计计数。
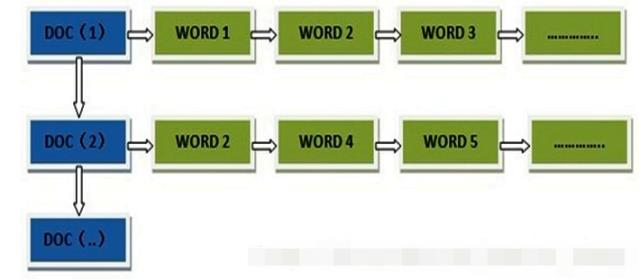
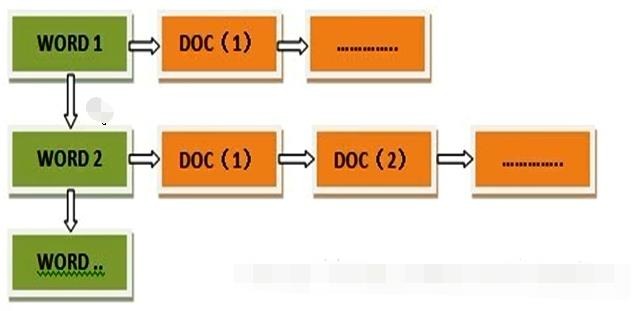
(2) 倒排索引
但是互联网上收录在搜索引擎中的文档的数目是个天文数字,这样的索引结构根本无法满足实时返回排名结果的要求。所以,搜索引擎会将正向索引重新构建为倒排索引,即把文件ID对应到关键词的映射转换为关键词到文件ID的映射,每个关键词都对应着一系列的文件,这些文件中都出现这个关键词。
(3) 倒排索引的不可改变性
早期的全文检索会为整个文档集合建立一个很大的倒排索引并将其写入到磁盘。 一旦新的索引就绪,旧的就会被其替换,这样最近的变化便可以被检索到。倒排索引被写入磁盘后是不可改变的,它永远不会修改。
优点:
-
不需要锁。如果你从来不更新索引,你就不需要担心多进程同时修改数据的问题。
-
一旦索引被读入内核的文件系统缓存,便会留在哪里,由于其不变性。只要文件系统缓存中还有足够的空间,那么大部分读请求会直接请求内存,而不会命中磁盘。这提供了很大的性能提升。
-
其它缓存(像filter缓存),在索引的生命周期内始终有效。它们不需要在每次数据改变时被重建,因为数据不会变化。
-
写入单个大的倒排索引允许数据被压缩,减少磁盘IO和需要被缓存到内存的索引的使用量。
缺点:
- 由于其不可改变,所以如果你需要让一个新的文档可被搜索,你需要重建整个索引。这要么对一个索引所能包含的数据量造成了很大的限制,要么对索引可被更新的频率造成了很大的限制。
(4) 动态更新索引
如何在保留不变性的前提下实现倒排索引的更新?答案是用更多的索引。通过增加新的补充索引来反映新近的修改,而不是直接重写整个倒排索引。每一个倒排索引都会被轮流查询到,从最早的开始查询完后再对结果进行合并。
Elasticsearch基于Lucene,这个java库引入了按段搜索的概念。每一段本身都是一个倒排索引,但索引在 Lucene 中除表示所有段的集合外,还增加了提交点的概念——一个列出了所有已知段的文件。
(5) 文档搜索/更新/删除
当一个查询被触发,所有已知的段按顺序被查询。词项统计会对所有段的结果进行聚合,以保证每个词和每个文档的关联都被准确计算。这种方式可以用相对较低的成本将新文档添加到索引。
段是不可改变的,所以既不能从把文档从旧的段中移除,也不能修改旧的段来进行反映文档的更新。取而代之的是,每个提交点会包含一个.del 文件,文件中会列出这些被删除文档的段信息。当一个**文档被“删除”**时,它实际上只是在 .del 文件中被标记删除。一个被标记删除的文档仍然可以被查询匹配到,但它会在最终结果被返回前从结果集中移除。
文档更新也是类似的操作方式:当一个文档被更新时,旧版本文档被标记删除,文档的新版本被索引到一个新的段中。可能两个版本的文档都会被一个查询匹配到,但被删除的那个旧版本文档在结果集返回前就已经被移除。
4.2.2、 文档分析
(1) 分析器
分析器实际上是将三个功能封装到了一个包里:
-
字符过滤器:首先,字符串按顺序通过每个 字符过滤器 。他们的任务是在分词前整理字符串。一个字符过滤器可以用来去掉 HTML,或者将 & 转化成 and。
-
分词器:其次,字符串被分词器分为单个的词条。一个简单的分词器遇到空格和标点的时候,可能会将文本拆分成词条。
-
Token 过滤器:最后,词条按顺序通过每个 token 过滤器 。这个过程可能会改变词条(例如,小写化Quick ),删除词条(例如, 像 a, and, the 等无用词),或者增加词条(例如,像jump和leap这种同义词)
(2) 分析器类型
-
标准分析器:标准分析器是Elasticsearch 默认使用的分析器。它是分析各种语言文本最常用的选择。它根据Unicode 联盟定义的单词边界划分文本。删除绝大部分标点。最后,将词条小写。
-
简单分析器:简单分析器在任何不是字母的地方分隔文本,将词条小写。
-
空格分析器:空格分析器在空格的地方划分文本。
-
语言分析器:特定语言分析器可用于很多语言。它们可以考虑指定语言的特点。例如,英语分析器附带了一组英语无用词(常用单词,例如and或者the ,它们对相关性没有多少影响),它们会被删除。由于理解英语语法的规则,这个分词器可以提取英语单词的词干。
-
自定义分析器:虽然Elasticsearch带有一些现成的分析器,然而在分析器上Elasticsearch真正的强大之处在于,你可以通过在一个适合你的特定数据的设置之中组合字符过滤器、分词器、词汇单元过滤器来创建自定义的分析器。一个分析器就是在一个包里面组合了三种函数的一个包装器,三种函数按照顺序被执行:
-
字符过滤器:字符过滤器用来整理一个尚未被分词的字符串。
-
分词器:一个分析器必须有一个唯一的分词器。分词器把字符串分解成单个词条或者词汇单元。
-
词单元过滤器:经过分词,作为结果的词单元流会按照指定的顺序通过指定的词单元过滤器。词单元过滤器可以修改、添加或者移除词单元。
-
4.3 、操作类型和操作对象
4.3.1、 GET/PUT/POST/DELETE
ES中主要有GET/PUT/POST/DELETE这四种操作,分别表示查询、更新或创建、创建、删除操作。其中PUT和POST的区别是:PUT在插入新数据的时候需要指定_id,而POST则不需要,这个_id是ES中文档的唯一标识。换种说法,PUT是幂等的,即多次执行的结果相同,而POST不是幂等的,多次执行会插入多条数据。
4.3.2、 _mapping / _settings/ _search/ _count/ _doc
_mapping/_settings/_search/_count/_doc分别是对映射、索引设置、查询记录值、查询记录数、查询文档信息的操作,具体看下文中的列子。
4.4、 索引/字段/文档等操作语句
4.4.1、 索引操作
(1) 创建索引
# 创建索引的设置信息,也可以直接创建索引字段,此时设置信息取默认值
PUT index_name
{
"settings" : {
"index" : {
"refresh_interval" : "60s",
"number_of_shards" : "3",
"translog" : {
"durability" : "async"
},
"max_result_window" : "10000000",
"unassigned" : {
"node_left" : {
"delayed_timeout" : "30m"
}
},
"number_of_replicas" : "1"
}
}
}
其中number_of_shards为分片数
(2) 查询索引设置信息
# 查询索引设置信息
GET trade_bill_detail/_settings
(3) 删除索引
# 删除索引
DELETE trade_bill_detail
4.4.2 2. 字段操作
(1) 为索引添加字段
# 为索引添加新字段
PUT trade_bill_detail/_mapping
{
"properties" : {
"begin_time" : {
"type" : "date"
},
"expense_begin_time" : {
"type" : "keyword"
},
"account_id" : {
"type" : "long"
},
"price_new" : {
"type" : "double"
}
}
}
(2) 查询字段信息
# 查看索引的所有字段
GET trade_bill_detail/_mapping
4.4.3、 文档操作
(1) 查询文档信息
# 查询文档信息,1798023是文档的id
GET trade_bill_detail/_doc/1798023
4.4.4、 其他操作
(1) 查询数据总量
# 查询数据总量,以kb为单位。用来在进行数据同步时查询同步情况
GET _cat/indices/trade_bill_detail?v&h=index,docs.count,store.size&bytes=kb
4.5、查询语句(ES 查询详解)
4.5.1、 match查询
S的查询有一个很大的特点就是分词。所以大家在使用ES的过程中脑子要始终有这么一个意识,你要查找的text是通过分词器分过词的,所以你去匹配的实际上是一个个被分词的片段。而你搜索的query也有可能会被分词,match就是一种会将你搜索的query进行分词的查询方法。我们结合例子来看!
比如我们要查询的索引结构如下:
{
"_index": "textbook",
"_id": "kIwXeYQB8iTYJNkI986Y",
"_source": {
"bookName": "This is a test doc",
"author": "dxl",
"num": 20
}
}
_ index 代表索引名称,_id代表该条数据唯一id, _ source代表该条数据具体的结构。
这里我们通过bookName字段来查询。
输入query语句如下:
GET http://ip:prot/textbook/_search
{
"query": {
"match": {
"bookName":"test"
}
}
}
该条语句代表用match方式搜索索引为textbook中bookName可以匹配到test的语句。因为:
"bookName": "This is a test doc"
原文被分词器分词后包含test这个词语,所以可以正常被匹配出来。
这个例子比较简单,我们换个复杂一点的例子:
GET http://ip:prot/textbook/_search
{
"query": {
"match": {
"bookName":"my test"
}
}
}
大家认为这个能否被匹配出来呢?
原文中根本就没有my这个词语,那怎么被匹配出来?但实际上是可以匹配出来的。
原因是match查询里,会对你查询的query也进行分词,也就是会将你的"my test"进行分词,得到my与test两个词语,然后用这两个词语分别去匹配文本,发现虽然my匹配不到,但是test可以匹配到,所以依然可以查出来。这个和我们传统的搜索方式确实存在差异,大家要注意。
那这种搜索方式存在的价值是什么呢?其实还有蛮大用处的。比如我们的ES库存储的是很多的英文好词好句,然后用户想提高自己的英文写作,因此想搜索出一些比较好的表达加在自己的文章中,那这个时候对于用户来讲,严格的匹配方式大概率什么都搜不到,但是像match这样的搜索方式便非常合适。例如有个好句是这样的:
If at first you don't succeed, try again.
然后用户用下面的方式搜索:
If you don't success
用match就可以很好的匹配出来。
4.5.2、 match_phrase查询
既然match的限制比较小,那如果我们需要这个限制更强一点用什么方式呢?match_phrase便是一个比较不错的选择。match_phrase和match一样也是会对你的搜索query进行分词,但是,不同的是它不是匹配到某一处分词的结果就算是匹配成功了,而是需要query中所有的词都匹配到,而且相对顺序还要一致,而且默认还是连续的,如此一来,限制就更多了。我们还是举个例子。比如还是刚刚的索引数据:
{
"_index": "textbook",
"_id": "kIwXeYQB8iTYJNkI986Y",
"_source": {
"bookName": "This is a test doc",
"author": "dxl",
"num": 20
}
}
如果我们还用刚刚的方式搜索:
GET http://ip:prot/textbook/_search
{
"query": {
"match_phrase": {
"bookName":"my test"
}
}
}
这次是匹配不到结果的。那么怎样才能匹配到结果呢?只能是搜索原文中的连续字串:
GET http://ip:prot/textbook/_search
{
"query": {
"match_phrase": {
"bookName":"is a test"
}
}
}
这样是可以匹配到结果的。但是如此一来限制可能太大了一点,所以官方还给了一个核心餐宿可以调整搜索的严格程度,这个参数叫slop,我们举个例子:
GET http://ip:prot/textbook/_search
{
"query": {
"match_phrase": {
"bookName":{
"query":"is test",
"slop":1
}
}
}
}
比如我们将slop置为1,然后搜索"is test",虽然is test中间省略了一个词语"a",但是在slop为1的情况下是可以容忍你中间省略一个词语的,也可以搜索出来结果。以此类推,slop为2就可以省略两个词语了。大家可以根据自己的实际情况进行调整。
另外我们可以发现,如果在搜索时添加了辅助参数(比如slop)我们搜索格式的层级要往下扩展一层,之前的
"bookName":"my test"
要改为:
"bookName":{
"query":"is test",
"slop":1
}
我们注意一下就好了。
4.5.3、 multi_match查询
有了前面的基础,multi_match比较好理解。实际上就是可以从多个字段中去寻找我们要查找的query:
GET http://ip:prot/textbook/_search
{
"query": {
"multi_match": {
"query" : "dxl",
"fields" : ["bookName", "author"]
}
}
}
比如这里我们是从bookName和author两个字段里去寻找dxl,虽然bookName没有,但是author可以匹配到,那也可以找到数据。所以本质上就是对bookName和author分别做了一次match:
{
"_index": "textbook",
"_id": "kIwXeYQB8iTYJNkI986Y",
"_source": {
"bookName": "This is a test doc",
"author": "dxl",
"num": 20
}
}
4.5.4、 term查询
(1) term查询
term查询也是比较常用的一种查询方式,它和match的唯一区别就是match需要对query进行分词,而term是不会进行分词的,它会直接拿query整体和原文进行匹配。所以不理解的小伙伴使用起来可能会非常奇怪:
GET http://ip:prot/textbook/_search
{
"query": {
"term": {
"bookName": "This is a test doc"
}
}
}
当我们用这种方式进行搜索时,明明要搜索的和被搜索的文本一模一样,确就是搜不出来。这就是因为我们去搜的实际上并不是原文本身,而是被分词的原文,在原文被分好的每一个词语里,没有一个词语是:“This is a test doc”,那自然是什么都搜不到了。所以在这种情况下就只能用某一个词进行搜索才可以搜到:
GET http://ip:prot/textbook/_search
{
"query": {
"term": {
"bookName": "This"
}
}
}
(2) terms查询
在 Elasticsearch 中,terms 查询默认使用 OR 运算符来组合多个查询条件。这意味着当您在 terms 查询中指定多个值时,它将返回与任何一个值匹配的文档。
例如,以下查询将返回包含 “apple” 或 “orange” 或 “banana” 中任何一个单词的文档:
{
"query": {
"terms": {
"fruit": ["apple", "orange", "banana"]
}
}
}
如果您需要使用 AND 运算符来组合多个查询条件,则可以使用 bool 查询,并将多个 term 查询作为子查询嵌套在其中。例如:
{
"query": {
"bool": {
"must": [
{ "term": { "fruit": "apple" } },
{ "term": { "fruit": "orange" } },
{ "term": { "fruit": "banana" } }
]
}
}
}
以上查询将仅返回同时包含 “apple” 和 “orange” 和 “banana” 的文档。
请注意,使用 bool 查询进行组合查询可能会导致性能下降,因为它需要执行多个子查询。因此,在设置查询时,请根据您的需求和数据规模进行评估和测试。
4.5.6、 fuzzy查询
fuzzy是ES里面的模糊搜索,它可以借助term查询来进行理解。fuzzy和term一样,也不会将query进行分词,但是不同的是它在进行匹配时可以容忍你的词语拼写有错误,至于容忍度如何,是根据参数fuzziness决定的。fuzziness默认是2,也就是在默认情况下,fuzzy查询容忍你有两个字符及以下的拼写错误。即如果你要匹配的词语为test,但是你的query是text,那也可以匹配到。这里无论是错写多写还是少写都是计算在内的。我们同样还是举例说明。
对于索引数据:
{
"_index": "textbook",
"_id": "kIwXeYQB8iTYJNkI986Y",
"_source": {
"bookName": "This is a test doc",
"author": "dxl",
"num": 20
}
}
如果查询语句为:
GET http://ip:prot/textbook/_search
{
"query": {
"fuzzy": {
"bookName":"text"
}
}
}
这时肯定是用text来匹配原文中的每一个词,发现text和test最为接近,但是有一个字符的差异,在默认fuzziness为2的情况下,依然可以匹配出来。
当然这个fuzziness是可以调的,比如:
GET http://ip:prot/textbook/_search
{
"query": {
"fuzzy": {
"bookName":{
"value":"texts",
"fuzziness":1
}
}
}
}
在容忍度为1的情况下,如果你想查texts就查不到结果了。
4.5.7、 range查询
range查询时对于某一个数值字段的大小范围查询,比如我这里特意所加的nums字段就是这个时候派上用场的。range的语法设计到了一些关键字:
- gte:大于等于
- gt:大于
- lt:小于
- lte:小于等于
GET http://ip:prot/textbook/_search
{
"query": {
"range": {
"num": {
"gte":20,
"lt":30
}
}
}
}
比如这样的条件就是去查找字段num大于等于20小于30的数据
那我们的数据便可以被查询到:
{
"_index": "textbook",
"_id": "kIwXeYQB8iTYJNkI986Y",
"_source": {
"bookName": "This is a test doc",
"author": "dxl",
"num": 20
}
}
4.5.8、 bool查询
bool查询是上面查询的一个综合,它可以用多个上面的查询去组合出一个大的查询语句,它也有一些关键字:
- must:代表且的关系,也就是必须要满足该条件
- should:代表或的关系,代表符合该条件就可以被查出来
- must_not:代表非的关系,也就是要求不能是符合该条件的数据才能被查出来
例如有这样一个查询:
GET http://ip:prot/textbook/_search
{
"query":{
"bool":{
"must":{
"match":{
"bookName":"dxl"
}
},
"should":{
"term":{
"author":"dxl"
},
"range":{
"num":{
"gt":20
}
},
}
}
}
}
这里就要求must里面的match是必须要符合的,但是should里面的两个条件就可以符合一条即可。
4.5.8、 排序和分页
排序和分页也是建立在上述的那些搜索之上的。排序和分页的条件是和query平级去写的,我们一个一个来看。先举个例子:
GET http://ip:prot/textbook/_search
{
"query":{
"match":{
"bookName":"dxl"
}
},
"from":0,
"size":100,
"sort":{
"num":{
"order":"desc"
}
}
}
这里关于分页的语句是:
"from":0,
"size":100,
它代表的意思是按照页容量为100进行分页,取第一页。
关于排序的语句是:
"sort":{
"num":{
"order":"desc"
}
}
它需要指定一个字段,然后根据这个字段进行升序或降序。这里我们根据num来进行降序排序,如果想升序就把order的值改为asc就好了。
4.6 ES 扩展查询-前缀匹配、通配符查询、正则查询
ES的无论什么搜索,对于text类型字段其实都是基于倒排索引去进行搜索的,也就是进行分词后的,因此如果想像传统数据库一样的模糊匹配,一般可以使用它的keyword进行搜索。(keyword不会被分词)
以下的搜索在大型生产环境都不推荐使用。
4.6.1、 前缀索引查询
以xx开头的搜索,不计算相关度评分,和filter比,没有bitcache。前缀搜索,尽量把前缀长度设置的更长,性能差,一般大规模产品不使用。(是去倒排索引中去匹配前缀,需要遍历每一个倒排索引才能找到所有匹配的)
GET index/_search
{
"query": {
"prefix": {
"title": {
"value": "text"
}
}
}
}
为了加快前缀搜索速度,可以设置默认的 前缀索引 (空间换时间)
PUT my_index
{
"mappings": {
"properties": {
"text": {
"type": "text",
"index_prefixes": {
"min_chars":2,
"max_chars":4
}
}
}
}
}
上面这个设置的意思是,把分词后的每个词项的2-4个字符额外进行建立前缀倒排索引,从而提高后续前缀匹配的速度,但是占用空间也是相对变大。
index_prefixes: 默认 “min_chars” : 2, “max_chars” : 5 。
4.6.2、 通配符查询
通配符查询类似于正则,但没正则强大,允许对匹配表达式进行通配符占位。
- 表示匹配任意长度的任意字符
? 表示匹配一个任意字符
[…]则表示匹配括号中列出的字符中的任意一个
[!..]表示不匹配括号中列出的字符中的任意一个
语法:
{
"query": {
"wildcard": {
"text": {
"value": "eng?ish"
}
}
}
}
4.6.3、 正则查询
regexp查询的性能可以根据提供的正则表达式而有所不同。为了提高性能,应避免使用通配符模式,如.或 .?+未经前缀或后缀
语法:
{
"query": {
"regexp": {
"name": {
"value": "[\\s\\S]*nfc[\\s\\S]*",
"flags": "ALL",
"max_determinized_states": 10000, #防止正则内存过大的保护措施
"rewrite": "constant_score"
}
}
}
}
关于参数flags,有几个配置可选:
ALL (Default)
启用所有可选操作符。
COMPLEMENT
启用操作符。可以使用对下面最短的模式进行否定。例如
a~bc # matches ‘adc’ and ‘aec’ but not ‘abc’
INTERVAL
启用<>操作符。可以使用<>匹配数值范围。例如
foo<1-100> # matches ‘foo1’, ‘foo2’ … ‘foo99’, ‘foo100’
foo<01-100> # matches ‘foo01’, ‘foo02’ … ‘foo99’, ‘foo100’
INTERSECTION
启用&操作符,它充当AND操作符。如果左边和右边的模式都匹配,则匹配成功。例如:
aaa.+&.+bbb # matches ‘aaabbb’
ANYSTRING
启用@操作符。您可以使用@来匹配任何整个字符串。
您可以将@操作符与&和 ~ 操作符组合起来,创建一个“everything except”逻辑。例如:
@&~(abc.+) # matches everything except terms beginning with ‘abc’
4.7 Es聚合查询(指标聚合、桶聚合)
所有的聚合,无论它们是什么类型,都遵从以下的规则。
- 使用查询中同样的 JSON 请求来定义它们,而且你是使用键 aggregations 或者是 aggs 来进行标记。需要给每个聚合起一个名字,指定它的类型以及和该类型相关的选项。
- 它们运行在查询的结果之上。和查询不匹配的文档不会计算在内,除非你使用 global 聚集将不匹配的文档囊括其中。
- 可以进一步过滤查询的结果,而不影响聚集。
以下是聚合的基本结构:
"aggregations" : { <!-- 最外层的聚合键,也可以缩写为 aggs -->
"<aggregation_name>" : { <!-- 聚合的自定义名字 -->
"<aggregation_type>" : { <!-- 聚合的类型,指标相关的,如 max、min、avg、sum,桶相关的 terms、filter 等 -->
<aggregation_body> <!-- 聚合体:对哪些字段进行聚合,可以取字段的值,也可以是脚本计算的结果 -->
}
[,"meta" : { [<meta_data_body>] } ]? <!-- 元 -->
[,"aggregations" : { [<sub_aggregation>]+ } ]? <!-- 在聚合里面在定义子聚合 -->
}
[,"<aggregation_name_2>" : { ... } ]* <!-- 聚合的自定义名字 2 -->
}
- 在最上层有一个 aggregations 的键,可以缩写为 aggs。
- 在下面一层,需要为聚合指定一个名字。可以在请求的返回中看到这个名字。在同一个请求中使用多个聚合时,这一点非常有用,它让你可以很容易地理解每组结果的含义。
- 最后,必须要指定聚合的类型。
关于聚合分析的值来源,可以取字段的值,也可以是脚本计算的结果。
但是用脚本计算的结果时,需要注意脚本的性能和安全性;尽管多数聚集类型允许使用脚本,但是脚本使得聚集变得缓慢,因为脚本必须在每篇文档上运行。为了避免脚本的运行,可以在索引阶段进行计算。
此外,脚本也可以被人可能利用进行恶意代码攻击,尽量使用沙盒(sandbox)内的脚本语言。
示例
查询所有球员的平均年龄是多少,并对球员的平均薪水加 188(也可以理解为每名球员加 188 后的平均薪水)。
POST /player/_search?size=0
{
"aggs": {
"avg_age": {
"avg": {
"field": "age"
}
},
"avg_salary_188": {
"avg": {
"script": {
"source": "doc.salary.value + 188"
}
}
}
}
}
4.7.1、 指标聚合
指标聚合(又称度量聚合)主要从不同文档的分组中提取统计数据,或者,从来自其他聚合的文档桶来提取统计数据。
这些统计数据通常来自数值型字段,如最小或者平均价格。用户可以单独获取每项统计数据,或者也可以使用 stats 聚合来同时获取它们。更高级的统计数据,如平方和或者是标准差,可以通过 extended stats 聚合来获取。
Max Aggregation
Max Aggregation 用于最大值统计。例如,统计 sales 索引中价格最高的是哪本书,并且计算出对应的价格的 2 倍值,查询语句如下:
GET /sales/_search?size=0
{
"aggs" : {
"max_price" : {
"max" : {
"field" : "price"
}
},
"max_price_2" : {
"max" : {
"field" : "price",
"script": {
"source": "_value * 2.0"
}
}
}
}
}
指定的 field,在脚本中可以用 _value 取字段的值。
聚合结果如下:
{
...
"aggregations": {
"max_price": {
"value": 188.0
},
"max_price_2": {
"value": 376.0
}
}
}
Min Aggregation
Min Aggregation 用于最小值统计。例如,统计 sales 索引中价格最低的是哪本书,查询语句如下:
GET /sales/_search?size=0
{
"aggs" : {
"min_price" : {
"min" : {
"field" : "price"
}
}
}
}
聚合结果如下:
{
...
"aggregations": {
"min_price": {
"value": 18.0
}
}
}
Avg Aggregation
Avg Aggregation 用于计算平均值。例如,统计 exams 索引中考试的平均分数,如未存在分数,默认为 60 分,查询语句如下:
GET /exams/_search?size=0
{
"aggs" : {
"avg_grade" : {
"avg" : {
"field" : "grade",
"missing": 60
}
}
}
}
如果指定字段没有值,可以通过 missing 指定默认值;若未指定默认值,缺失该字段值的文档将被忽略(计算)。
聚合结果如下:
{
...
"aggregations": {
"avg_grade": {
"value": 78.0
}
}
}
Sum Aggregation
Sum Aggregation 用于计算总和。例如,统计 sales 索引中 type 字段中匹配 hat 的价格总和,查询语句如下:
GET /exams/_search?size=0
{
"query" : {
"constant_score" : {
"filter" : {
"match" : { "type" : "hat" }
}
}
},
"aggs" : {
"hat_prices" : {
"sum" : { "field" : "price" }
}
}
}
聚合结果如下:
{
...
"aggregations": {
"hat_prices": {
"value": 567.0
}
}
}
Value Count Aggregation
Value Count Aggregation 可按字段统计文档数量。例如,统计 books 索引中包含 author 字段的文档数量,查询语句如下:
GET /books/_search?size=0
{
"aggs" : {
"doc_count" : {
"value_count" : { "field" : "author" }
}
}
}
聚合结果如下:
{
...
"aggregations": {
"doc_count": {
"value": 5
}
}
}
Cardinality Aggregation
Cardinality Aggregation 用于基数统计,其作用是先执行类似 SQL 中的 distinct 操作,去掉集合中的重复项,然后统计排重后的集合长度。例如,在 books 索引中对 language 字段进行 cardinality 操作可以统计出编程语言的种类数,查询语句如下:
GET /books/_search?size=0
{
"aggs" : {
"all_lan" : {
"cardinality" : { "field" : "language" }
},
"title_cnt" : {
"cardinality" : { "field" : "title.keyword" }
}
}
}
假设 title 字段为文本类型(text),去重时需要指定 keyword,表示把 title 作为整体去重,即不分词统计。
聚合结果如下:
{
...
"aggregations": {
"all_lan": {
"value": 8
},
"title_cnt": {
"value": 18
}
}
}
Stats Aggregation
Stats Aggregation 用于基本统计,会一次返回 count、max、min、avg 和 sum 这 5 个指标。例如,在 exams 索引中对 grade 字段进行分数相关的基本统计,查询语句如下:
GET /exams/_search?size=0
{
"aggs" : {
"grades_stats" : {
"stats" : { "field" : "grade" }
}
}
}
聚合结果如下:
{
...
"aggregations": {
"grades_stats": {
"count": 2,
"min": 50.0,
"max": 100.0,
"avg": 75.0,
"sum": 150.0
}
}
}
Extended Stats Aggregation
Extended Stats Aggregation 用于高级统计,和基本统计功能类似,但是会比基本统计多出以下几个统计结果,sum_of_squares(平方和)、variance(方差)、std_deviation(标准差)、std_deviation_bounds(平均值加/减两个标准差的区间)。在 exams 索引中对 grade 字段进行分数相关的高级统计,查询语句如下:
GET /exams/_search?size=0
{
"aggs" : {
"grades_stats" : {
"extended_stats" : { "field" : "grade" }
}
}
}
聚合结果如下:
{
...
"aggregations": {
"grades_stats": {
"count": 2,
"min": 50.0,
"max": 100.0,
"avg": 75.0,
"sum": 150.0,
"sum_of_squares": 12500.0,
"variance": 625.0,
"std_deviation": 25.0,
"std_deviation_bounds": {
"upper": 125.0,
"lower": 25.0
}
}
}
}
Percentiles Aggregation
Percentiles Aggregation 用于百分位统计。百分位数是一个统计学术语,如果将一组数据从大到小排序,并计算相应的累计百分位,某一百分位所对应数据的值就称为这一百分位的百分位数。默认情况下,累计百分位为 [ 1, 5, 25, 50, 75, 95, 99 ]。以下例子给出了在 latency 索引中对 load_time 字段进行加载时间的百分位统计,查询语句如下:
GET latency/_search
{
"size": 0,
"aggs" : {
"load_time_outlier" : {
"percentiles" : {
"field" : "load_time"
}
}
}
}
需要注意的是,如上的 load_time 字段必须是数字类型。
聚合结果如下:
{
...
"aggregations": {
"load_time_outlier": {
"values" : {
"1.0": 5.0,
"5.0": 25.0,
"25.0": 165.0,
"50.0": 445.0,
"75.0": 725.0,
"95.0": 945.0,
"99.0": 985.0
}
}
}
}
百分位的统计也可以指定 percents 参数指定百分位,如下:
GET latency/_search
{
"size": 0,
"aggs" : {
"load_time_outlier" : {
"percentiles" : {
"field" : "load_time",
"percents": [60, 80, 95]
}
}
}
}
Percentiles Ranks Aggregation
Percentiles Ranks Aggregation 与 Percentiles Aggregation 统计恰恰相反,就是想看当前数值处在什么范围内(百分位), 假如你查一下当前值 500 和 600 所处的百分位,发现是 90.01 和 100,那么说明有 90.01 % 的数值都在 500 以内,100 % 的数值在 600 以内。
GET latency/_search
{
"size": 0,
"aggs" : {
"load_time_ranks" : {
"percentile_ranks" : {
"field" : "load_time",
"values" : [500, 600]
}
}
}
}
同样 load_time 字段必须是数字类型。
返回结果大概类似如下:
{
...
"aggregations": {
"load_time_ranks": {
"values" : {
"500.0": 90.01,
"600.0": 100.0
}
}
}
}
可以设置 keyed 参数为 true,将对应的 values 作为桶 key 一起返回,默认是 false。
GET latency/_search
{
"size": 0,
"aggs": {
"load_time_ranks": {
"percentile_ranks": {
"field": "load_time",
"values": [500, 600],
"keyed": true
}
}
}
}
返回结果如下:
{
...
"aggregations": {
"load_time_ranks": {
"values": [
{
"key": 500.0,
"value": 90.01
},
{
"key": 600.0,
"value": 100.0
}
]
}
}
}
4.7.2、 桶聚合
bucket 可以理解为一个桶,它会遍历文档中的内容,凡是符合某一要求的就放入一个桶中,分桶相当于 SQL 中的 group by。从另外一个角度,可以将指标聚合看成单桶聚合,即把所有文档放到一个桶中,而桶聚合是多桶型聚合,它根据相应的条件进行分组。
桶聚合种类
| 类型 | 描述/场景 |
|---|---|
| 词项聚合 | 用于分组聚合,让用户得知文档中每个词项的频率,它返回每个词项出现的次数。 |
| 差异词项聚合 | 它会返回某个词项在整个索引中和在查询结果中的词频差异,这有助于我们发现搜索场景中有意义的词。 |
| 过滤器聚合 | 指定过滤器匹配的所有文档到单个桶(bucket),通常这将用于将当前聚合上下文缩小到一组特定的文档。 |
| 多过滤器聚合 | 指定多个过滤器匹配所有文档到多个桶(bucket)。 |
| 范围聚合 | 范围聚合,用于反映数据的分布情况。 |
| 日期范围聚合 | 专门用于日期类型的范围聚合。 |
| IP 范围聚合 | 用于对 IP 类型数据范围聚合。 |
| 直方图聚合 | 可能是数值,或者日期型,和范围聚集类似。 |
| 时间直方图聚合 | 时间直方图聚合,常用于按照日期对文档进行统计并绘制条形图。 |
| 空值聚合 | 空值聚合,可以把文档集中所有缺失字段的文档分到一个桶中。 |
| 地理点范围聚合 | 用于对地理点(geo point)做范围统计。 |
Terms Aggregation
Terms Aggregation 用于词项的分组聚合。最为经典的用例是获取 X 中最频繁(top frequent)的项目,其中 X 是文档中的某个字段,如用户的名称、标签或分类。由于 terms 聚集统计的是每个词条,而不是整个字段值,因此通常需要在一个非分析型的字段上运行这种聚集。原因是, 你期望“big data”作为词组统计,而不是“big”单独统计一次,“data”再单独统计一次。
用户可以使用 terms 聚集,从分析型字段(如内容)中抽取最为频繁的词条。还可以使用这种信息来生成一个单词云。
{
"aggs": {
"profit_terms": {
"terms": { // terms 聚合 关键字
"field": "profit",
......
}
}
}
}
在 terms 分桶的基础上,还可以对每个桶进行指标统计,也可以基于一些指标或字段值进行排序。示例如下:
{
"aggs": {
"item_terms": {
"terms": {
"field": "item_id",
"size": 1000,
"order":[{
"gmv_stat": "desc"
},{
"gmv_180d": "desc"
}]
},
"aggs": {
"gmv_stat": {
"sum": {
"field": "gmv"
}
},
"gmv_180d": {
"sum": {
"script": "doc['gmv_90d'].value*2"
}
}
}
}
}
}
返回的结果如下:
{
...
"aggregations": {
"hospital_id_agg": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 260,
"buckets": [
{
"key": 23388,
"doc_count": 18,
"gmv_stat": {
"value": 176220
},
"gmv_180d": {
"value": 89732
}
},
{
"key": 96117,
"doc_count": 16,
"gmv_stat": {
"value": 129306
},
"gmv_180d": {
"value": 56988
}
},
...
]
}
}
}
默认情况下返回按文档计数从高到低的前 10 个分组,可以通过 size 参数指定返回的分组数。
Filter Aggregation
{
"aggs": {
"age_terms": {
"filter": {"match":{"gender":"F"}},
"aggs": {
"avg_age": {
"avg": {
"field": "age"
}
}
}
}
}
}
Filters Aggregation
Filters Aggregation 是多过滤器聚合,可以把符合多个过滤条件的文档分到不同的桶中,即每个分组关联一个过滤条件,并收集所有满足自身过滤条件的文档。
{
"size": 0,
"aggs": {
"messages": {
"filters": {
"filters": {
"errors": { "match": { "body": "error" } },
"warnings": { "match": { "body": "warning" } }
}
}
}
}
}
在这个例子里,我们分析日志信息。聚合会创建两个关于日志数据的分组,一个收集包含错误信息的文档,另一个收集包含告警信息的文档。而且每个分组会按月份划分。
{
...
"aggregations": {
"messages": {
"buckets": {
"errors": {
"doc_count": 1
},
"warnings": {
"doc_count": 2
}
}
}
}
}
Range Aggregation
Range Aggregation 范围聚合是一个基于多组值来源的聚合,可以让用户定义一系列范围,每个范围代表一个分组。在聚合执行的过程中,从每个文档提取出来的值都会检查每个分组的范围,并且使相关的文档落入分组中。注意,范围聚合的每个范围内包含 from 值但是排除 to 值。
{
"aggs": {
"age_range": {
"range": {
"field": "age",
"ranges": [{
"to": 25
},
{
"from": 25,
"to": 35
},
{
"from": 35
}]
},
"aggs": {
"bmax": {
"max": {
"field": "balance"
}
}
}
}
}
}
}
返回结果如下:
{
...
"aggregations": {
"age_range": {
"buckets": [{
"key": "*-25.0",
"to": 25,
"doc_count": 225,
"bmax": {
"value": 49587
}
},
{
"key": "25.0-35.0",
"from": 25,
"to": 35,
"doc_count": 485,
"bmax": {
"value": 49795
}
},
{
"key": "35.0-*",
"from": 35,
"doc_count": 290,
"bmax": {
"value": 49989
}
}]
}
}
}
5、Springboot 整合es(这里整合的是ES7)
5.1、依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
5.2、yml配置
spring:
elasticsearch:
uris: http://172.16.3.52:9200
data:
elasticsearch:
repositories:
enabled: true
5.3、ElasticsearchRestTemplate配置
@Configuration
public class ElasticsearchRestTemplateConfig extends AbstractElasticsearchConfiguration {
@Value("${spring.elasticsearch.rest.uris}")
private String uris;
@Override
public RestHighLevelClient elasticsearchClient() {
ClientConfiguration configuration = ClientConfiguration.builder()
.connectedTo(uris)
.build();
return RestClients.create(configuration).rest();
}
}
5.4、 代码
Model
Model类似于数据库实体,不过此处所映射的是Index和Document的字段。
@Data
@Document(indexName = "order", shards = 1, replicas = 1)
public class Order implements Serializable {
@Id
private Integer id;
@Field(type = FieldType.Keyword)
private Long orderNo;
@Field(type = FieldType.Integer)
private Integer orderType;
@Field(type = FieldType.Long)
private Long orderAmount;
@Field(type = FieldType.Text, analyzer = "ik_smart", searchAnalyzer = "ik_max_word")
private String orderDesc;
@Field(type = FieldType.Keyword, analyzer = "ik_smart", searchAnalyzer = "ik_max_word")
private String username;
@Field(type = FieldType.Keyword, analyzer = "ik_smart", searchAnalyzer = "ik_max_word")
private String userPhone;
private Map<String, List<String>> highlights;
}
Repository
ElasticsearchRepository接口封装了Document的CRUD操作,我们直接定义接口继承它即可。
public interface OrderRepository extends ElasticsearchRepository<Order, Integer> {
}
Service
public interface OrderService {
void saveAll(List<Order> orders);
Order findById(Integer id);
void deleteById(Integer id);
void updateById(Order order);
PageResponse<Order> findList(Order order, Integer pageIndex, Integer pageSize);
PageResponse<Order> findAll(Integer pageIndex, Integer pageSize);
PageResponse<Order> findHighlight(Order order, Integer pageIndex, Integer pageSize);
}
@Service
@Slf4j
public class OrderServiceImpl implements OrderService {
@Autowired
OrderRepository orderRepository;
@Autowired
ElasticsearchRestTemplate elasticsearchRestTemplate;
@Override
public void saveAll(List<Order> orders) {
orderRepository.saveAll(orders);
}
@Override
public void deleteById(Integer id) {
orderRepository.deleteById(id);
}
@Override
public void updateById(Order order) {
orderRepository.save(order);
}
@Override
public PageResponse<Order> findList(Order order, Integer pageIndex, Integer pageSize) {
CriteriaQuery criteriaQuery = new CriteriaQuery(new Criteria()
.and(new Criteria("orderDesc").contains(order.getOrderDesc()))
.and(new Criteria("orderNo").is(order.getOrderNo())))
.setPageable(PageRequest.of(pageIndex, pageSize));
SearchHits<Order> searchHits = elasticsearchRestTemplate.search(criteriaQuery, Order.class);
List<Order> result = searchHits.get().map(SearchHit::getContent).collect(Collectors.toList());
PageResponse<Order> pageResponse = new PageResponse<Order>();
pageResponse.setTotal(searchHits.getTotalHits());
pageResponse.setResult(result);
return pageResponse;
}
@Override
public PageResponse<Order> findAll(Integer pageIndex, Integer pageSize) {
Page<Order> page = orderRepository.findAll(PageRequest.of(pageIndex, pageSize));
PageResponse<Order> pageResponse = new PageResponse<Order>();
pageResponse.setTotal(page.getTotalElements());
pageResponse.setResult(page.getContent());
return pageResponse;
}
@Override
public PageResponse<Order> findHighlight(Order order, Integer pageIndex, Integer pageSize) {
if (order == null) {
PageResponse<Order> pageResponse = new PageResponse<Order>();
pageResponse.setTotal(0L);
pageResponse.setResult(new ArrayList<>());
return pageResponse;
}
CriteriaQuery criteriaQuery = new CriteriaQuery(new Criteria()
.and(new Criteria("orderNo").is(order.getOrderNo()))
.and(new Criteria("orderDesc").contains(order.getOrderDesc())))
.setPageable(PageRequest.of(pageIndex, pageSize));
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("orderNo").field("orderDesc");
highlightBuilder.requireFieldMatch(false);
highlightBuilder.preTags("<h3 style="color:blue">");
highlightBuilder.postTags("</h3>");
HighlightQuery highlightQuery = new HighlightQuery(highlightBuilder);
criteriaQuery.setHighlightQuery(highlightQuery);
SearchHits<Order> searchHits = elasticsearchRestTemplate.search(criteriaQuery, Order.class);
List<Order> result = searchHits.get().map(e -> {
Order element = e.getContent();
element.setHighlights(e.getHighlightFields());
return element;
}).collect(Collectors.toList());
PageResponse<Order> pageResponse = new PageResponse<Order>();
pageResponse.setTotal(searchHits.getTotalHits());
pageResponse.setResult(result);
return pageResponse;
}
@Override
public Order findById(Integer id) {
return orderRepository.findById(id).orElse(null);
}
Controller
Index操作 使用ElasticsearchRestTemplate直接就可以创建和删除索引。
@RequestMapping("/index/")
@RestController
public class IndexController {
@Autowired
private ElasticsearchRestTemplate elasticsearchRestTemplate;
/**
* 创建索引
*/
@GetMapping("create")
public String create(@RequestParam String indexName) {
IndexOperations indexOperations = elasticsearchRestTemplate.indexOps(IndexCoordinates.of(indexName));
if (indexOperations.exists()) {
return "索引已存在";
}
indexOperations.create();
return "索引创建成功";
}
/**
* 删除索引
*/
@GetMapping("delete")
public String delete(@RequestParam String indexName) {
IndexOperations indexOperations = elasticsearchRestTemplate.indexOps(IndexCoordinates.of(indexName));
indexOperations.delete();
return "索引删除成功";
}
}
Document操作 主要包括简单查询、增删改、分页查询、高亮搜索。
@RequestMapping("/doc/")
@RestController
public class DocController {
@Autowired
OrderService orderService;
/**
* 批量创建
*/
@PostMapping("saveBatch")
public String saveBatch(@RequestBody List<Order> orders) {
if (CollectionUtils.isEmpty(orders)) {
return "文档不能为空";
}
orderService.saveAll(orders);
return "保存成功";
}
/**
* 根据id删除
*/
@GetMapping("deleteById")
public String deleteById(@RequestParam Integer id) {
orderService.deleteById(id);
return "删除成功";
}
/**
* 根据id更新
*/
@PostMapping("updateById")
public String updateById(@RequestBody Order order) {
orderService.updateById(order);
return "更新成功";
}
/**
* 根据id搜索
*/
@GetMapping("findById")
public String findById(@RequestParam Integer id) {
return JSON.toJSONString(orderService.findById(id));
}
/**
* 分页搜索所有
*/
@GetMapping("findAll")
public String findAll(@RequestParam Integer pageIndex, @RequestParam Integer pageSize) {
return JSON.toJSONString(orderService.findAll(pageIndex, pageSize));
}
/**
* 条件分页搜索
*/
@GetMapping("findList")
public String findList(@RequestBody Order order, @RequestParam Integer pageIndex, @RequestParam Integer pageSize) {
return JSON.toJSONString(orderService.findList(order, pageIndex, pageSize));
}
/**
* 条件高亮分页搜索
*/
@GetMapping("findHighlight")
public String findHighlight(@RequestBody(required = false) Order order, @RequestParam Integer pageIndex, @RequestParam Integer pageSize) {
return JSON.toJSONString(orderService.findHighlight(order, pageIndex, pageSize));
}
}
测试
注意!!!
如果多个中文检索不到,应该是没有使用中文分词器,导致中文被分词成一个一个字,建议参照上面的IK中文分词器配置中文分词器。
直接postman访问controller进行测试即可。 示例:
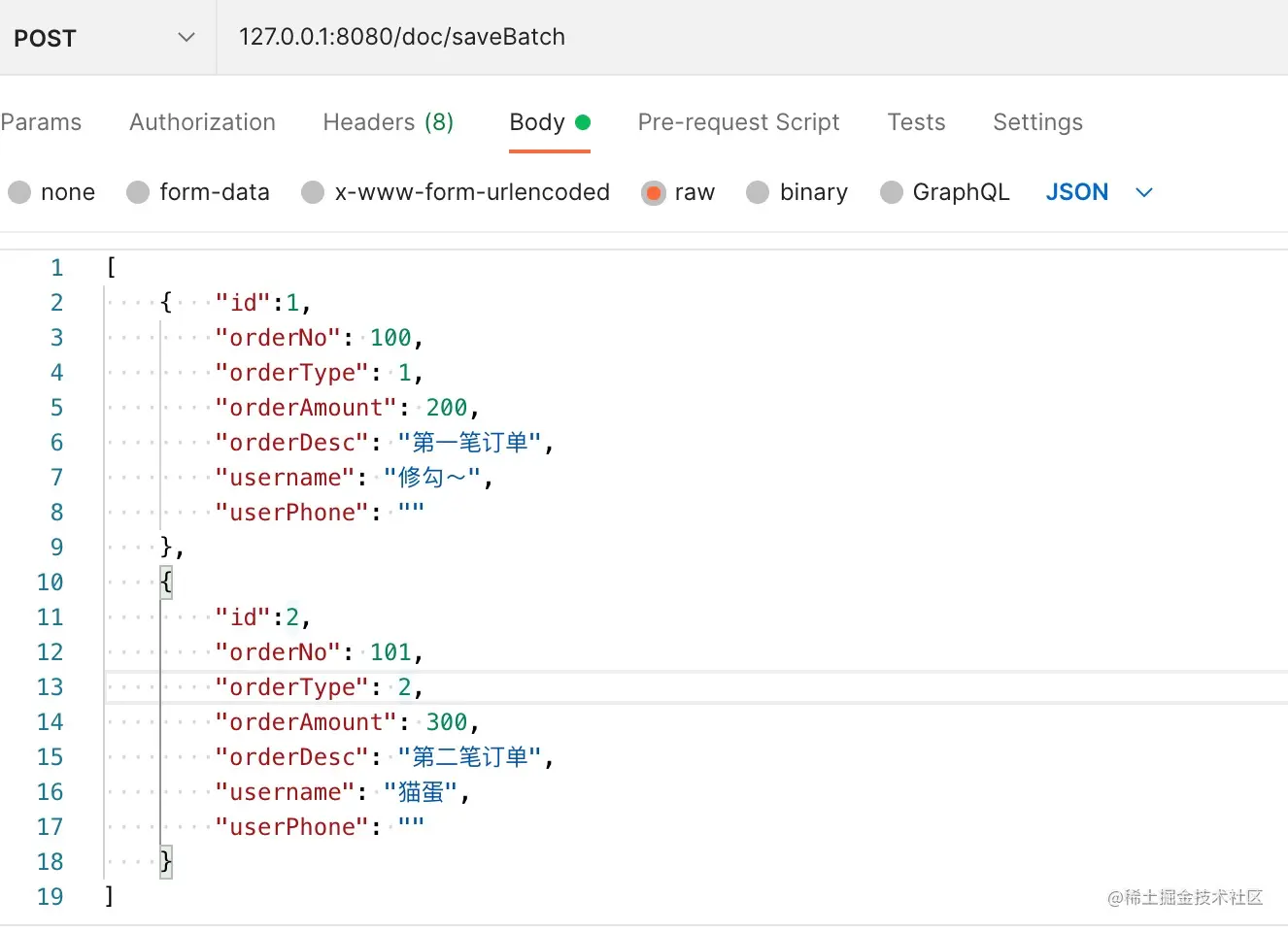















 2195
2195

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









