






ElasticSearch全文搜索引擎
一.全文搜索Lucene
1.全文搜索概述
1.1.什么是全文检索
狭义的理解主要针对文本数据的搜索。数据可分为“结构化”数据(关系数据库表形式管理的数据),半结构化数据(XML文档、JSON文档),和非结构化数据(WORD、PDF),通常而言在结构化的数据中搜索性能是比较高的,全文搜索的目的就是把非结构化的数据变成有结构化的数据进行搜索,从而提高搜索效率。
1.2.为什么要使用全文搜索
-
搜索效率高,是like无法比拟的 like %keyword%
-
相关度最高的排在最前面,官网中相关的网页排在最前面; java
-
关键词的高亮。
-
搜索效果更好, 基于单词搜索
-
只处理文本,不处理语义。 以单词方式进行搜索,比如在输入框中输入“中国的首都在哪里”,搜索引擎不会以对话的形式告诉你“在北京”,而仅仅是列出包含了搜索关键字的网页。
java ---->javascript java
代替大量数据表中的like查询
1.3.常见的全文搜索
- 全文搜索工具包(jar)-Lucene(核心)
- 全文搜索服务器 ,Elastic Search(ES) / Solr等封装了lucene并扩展
2.Lucene概述
2.1.什么是Lucene
Lucene是apache下的一个开源的全文检索引擎工具包(一堆jar包)。它为软件开发人员提供一个简单易用的工具包(类库),以方便的在小型目标系统中实现全文检索的功能。Lucene适用于中小型项目 ,ES适用于中大型项目(它底层是基于lucene实现的)
2.2.Lucene索引原理
任何技术都有一些核心,Lucene也有核心,而它的核心分为:索引创建,索引搜索
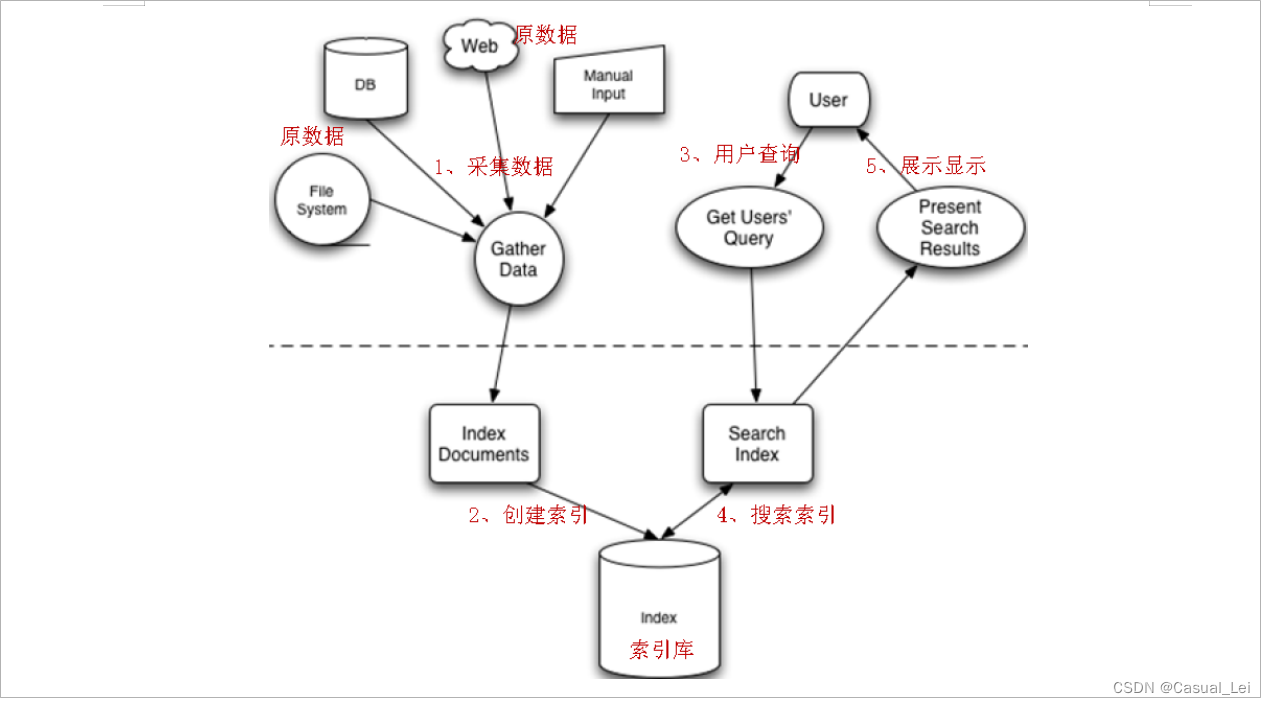
Lucene入门程序
Lucene的索引库和数据库一样,都提供相应的API来便捷操作。Lucene中的索引维护使用IndexWriter,由这个类提供添删改相关的操作;索引的搜索则是使用IndexSearcher进行索引的搜索。
1.导入依赖
HelloWorld代码如下,导入三个jar包:lucene-analyzers-common-5.5.0.jar,lucene-core-5.5.0.jar,lucene-queryparser-5.5.0.jar
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>5.5.0</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>5.5.0</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>5.5.0</version>
</dependency>
2.创建索引
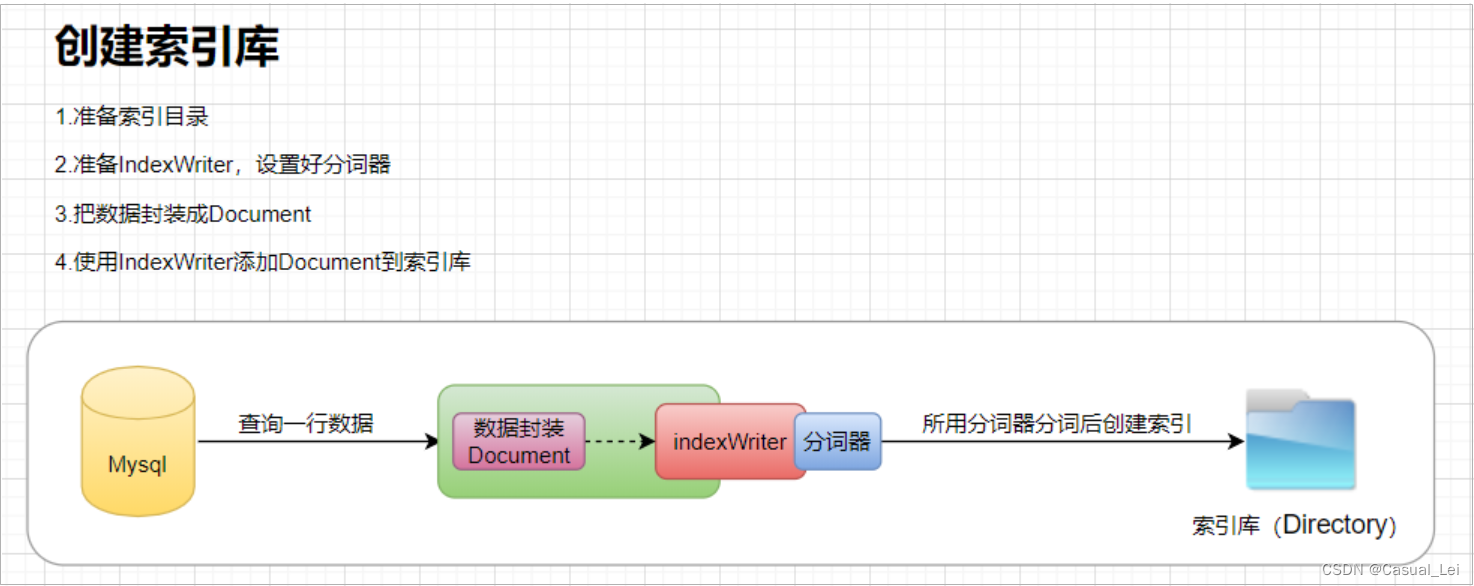
String doc1 = "hello world";
String doc2 = "hello java world";
String doc3 = "hello lucene world";
private String path ="F:/eclipse/workspace/lucene/index/hello";
@Test
public void testCreate() {
try {
//2、准备IndexWriter(索引写入器)
//索引库的位置 FS fileSystem
Directory d = FSDirectory.open(Paths.get(path ));
//分词器 -- 把文档进行分词
Analyzer analyzer = new SimpleAnalyzer();
//索引写入器的配置对象
IndexWriterConfig conf = new IndexWriterConfig(analyzer);
IndexWriter indexWriter = new IndexWriter(d, conf);
System.out.println(indexWriter);
//1、 把文本内容转换为Document对象
//把文本转换为document对象
Document document1 = new Document();
//标题字段
document1.add(new TextField("title", "doc1", Store.YES));
document1.add(new TextField("content", doc1, Store.YES));
//添加document到缓冲区
indexWriter.addDocument(document1);
Document document2 = new Document();
//标题字段
document2.add(new TextField("title", "doc2", Store.YES));
document2.add(new TextField("content", doc2, Store.YES));
//添加document到缓冲区
indexWriter.addDocument(document2);
Document document3 = new Document();
//标题字段
document3.add(new TextField("title", "doc3", Store.YES));
document3.add(new TextField("content", doc3, Store.YES));
//3 、通过IndexWriter,把Document添加到缓冲区并提交
//添加document到缓冲区
indexWriter.addDocument(document3);
indexWriter.commit();
indexWriter.close();
} catch (Exception e) {
e.printStackTrace();
}
}
使用luke工具可以看到索引库中的数据
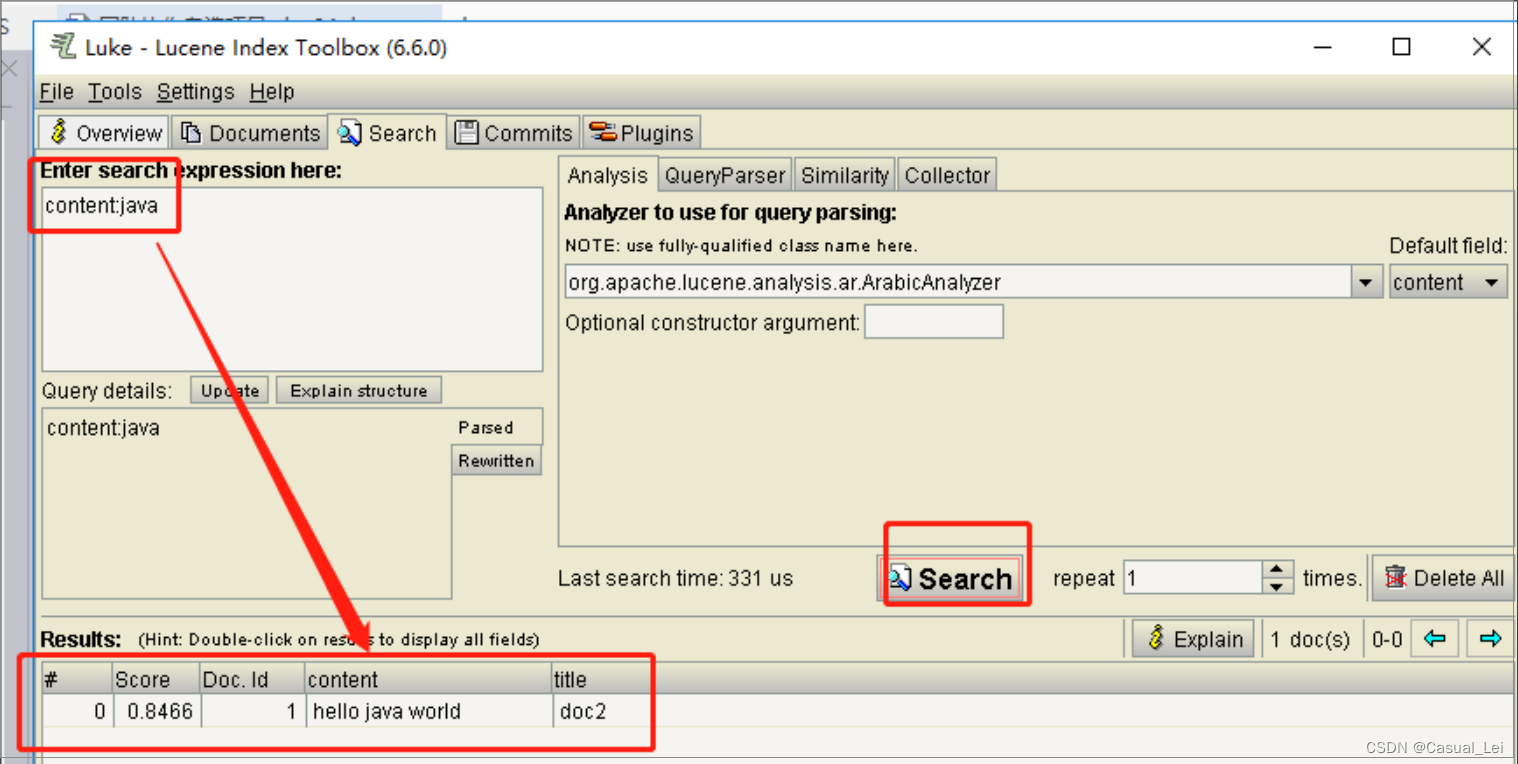
https://github.com/DmitryKey/luke
2.搜索索引

1 封装查询提交为查询对象
2 准备IndexSearcher
3 使用IndexSearcher传入查询对象做查询-----查询出来只是文档编号DocID
4 通过IndexSearcher传入DocID获取文档
5 把文档转换为前台需要的对象
@Test
public void testSearch() {
String keyWord = "lucene";
try {
// * 1 封装查询提交为查询对象
//通过查询解析器解析一个字符串为查询对象
String f = "content"; //查询的默认字段名,
Analyzer a = new SimpleAnalyzer();//查询关键字要分词,所有需要分词器
QueryParser parser = new QueryParser(f, a);
Query query = parser.parse("content:"+keyWord);
// * 2 准备IndexSearcher
Directory d = FSDirectory.open(Paths.get(path ));
IndexReader r = DirectoryReader.open(d);
IndexSearcher searcher = new IndexSearcher(r);
// * 3 使用IndexSearcher传入查询对象做查询-----查询出来只是文档编号DocID
TopDocs topDocs = searcher.search(query, 1000);//查询ton条记录 前多少条记录
System.out.println("总命中数:"+topDocs.totalHits);
ScoreDoc[] scoreDocs = topDocs.scoreDocs;//命中的所有的文档的封装(docId)
// * 4 通过IndexSearcher传入DocID获取文档
for (ScoreDoc scoreDoc : scoreDocs) {
int docId = scoreDoc.doc;
Document document = searcher.doc(docId);
// * 5 把文档转换为前台需要的对象 Docment----> Article
System.out.println("=======================================");
System.out.println("title:"+document.get("title")
+",content:"+document.get("content"));
}
} catch (Exception e) {
e.printStackTrace();
}
}
二.ElasticSearch相关概念
1.ElasticSearch介绍
1.1. 为什么要使用ElasticSearch
虽然全文搜索领域,Lucene可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。但是,Lucene只是一个库。想要使用它,你必须使用Java来作为开发语言并将其直接集成到你的应用中,更糟糕的是,Lucene的配置及使用非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的。
1.2.什么是ElasticSearch
ES是一个分布式的全文搜索引擎,为了解决原生Lucene使用的不足,优化Lucene的调用方式,并实现了高可用的分布式集群的搜索方案,ES的索引库管理支持依然是基于Apache Lucene™的开源搜索引擎。
ES也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的 RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
总的来说ElasticSearch简化了全文检索lucene的使用,同时增加了分布式的特性,使得构建大规模分布式全文检索变得非常容易。
1.3.ES的特点
- 分布式的实时文件存储
- 分布式全文搜索引擎,每个字段都被索引并可被搜索
- 能在分布式项目/集群中使用
- 本身支持集群扩展,可以扩展到上百台服务器
- 处理PB级结构化或非结构化数据
- 简单的 RESTful API通信方式
- 支持各种语言的客户端
- 基于Lucene封装,使操作简单
2.ES的使用案例
-
Github(美国)使用Elasticsearch搜索20TB的数据,包括13亿的文件和1300亿行的代码.
-
Foursquare实时搜索5千万地点信息?Foursquare每天都用Elasticsearch做这样的事.
-
德国SoundCloud使用Elasticsearch来为1.8亿用户提供即时精准的音乐搜索服务.
-
Mozilla公司以火狐著名,它目前使用 WarOnOrange 这个项目来进行单元或功能测试,测试的结果以 json的方式索引到elasticsearch中,开发人员可以非常方便的查找 bug.
-
Sony公司使用elasticsearch 作为信息搜索引擎.
三.ES下载和安装
ES的安装比较简单,只需要官方下载ES的运行包,然后启动ES服务即可。ES的使用主要是通过能够发起HTTP请求的终端来接入,比如Poster插件、CURL、kibana5等。
1.ElasticSearch安装
ES服务只依赖于JDK,推荐使用JDK1.8+。本课程以在window环境下,ES 6.8.6版本为例,下载对应的ZIP文件
1.1.下载ElasticSearch
下载地址:https://www.elastic.co/downloads/elasticsearch
1.2.安装与启动
解压即可,双击安装目录 bin/elasticsearch.bat即可启动
1.3.ElasticSearch测试
使用浏览器访问:http://localhost:9200
.
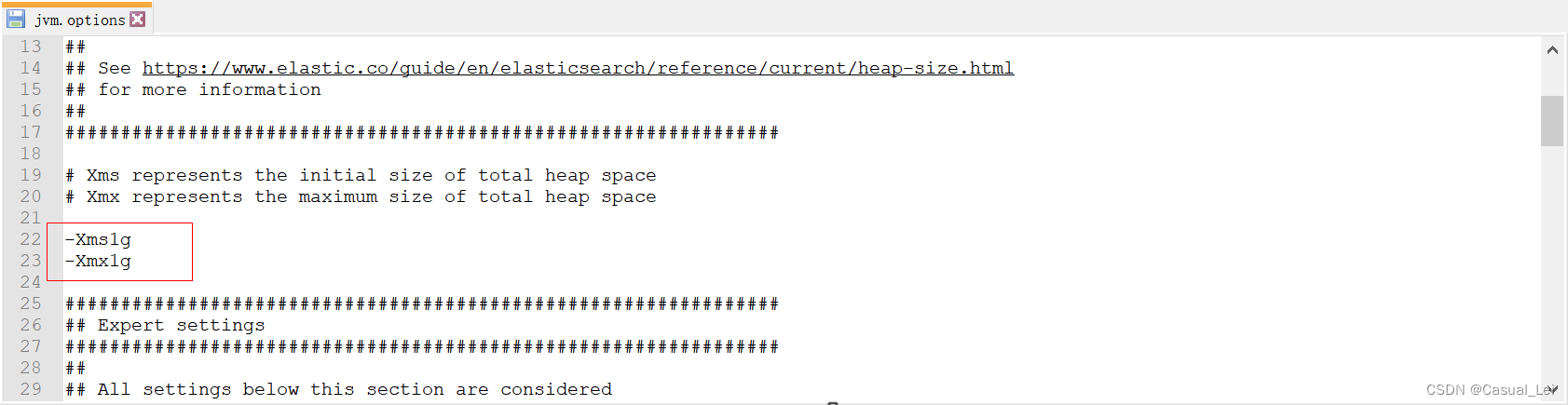
1.4.ES内存配置
如果ES启动占用的内存比较大可以通过修改 jvm.options 文件来修改内存
2.Kibana5安装
2.1.下载Kibana5
下载地址:https://www.elastic.co/downloads/kibana
2.2.安装与启动
解压即可安装 , 执行bin\kibana.bat 即可启动Kibana
2.3.Kinbana连接ES配置
解压并编辑config/kibana.yml,设置elasticsearch.url的值为已启动的ES
默认情况下,Kibana会链接本地的默认ES http://localhost:9200 ,如果需要修改链接的ES服务器,通过修改安装目录下 config/kibana.yml,将配置项 #elasticsearch.url: "http://localhost:9200" 取消注释即可修改连接的ES服务器地址。
2.4.测试Kibana
浏览器访问 http://localhost:5601 Kibana默认地址
Kibana组件详细说明:https://www.cnblogs.com/hunttown/p/6768864.html
Discover:可视化查询分析器
Visualize:统计分析图表
Dashboard:自定义主面板(添加图表)
Timelion:Timelion是一个kibana时间序列展示组件(暂时不用)
Dev Tools :Console(同CURL/POSTER,操作ES代码工具,代码提示,很方便)
Management:管理索引库(index)、已保存的搜索和可视化结果(save objects)、设置 kibana 服务器属性。
四.ElasticSearch基础
1.几个基本概念
1.1.Near Realtime(NRT)
近实时,两个意思,从写入数据到数据可以被搜索到有一个小延迟(大概1秒);基于es执行搜索和分析可以达到秒级
1.2.Index:索引库
包含一堆有相似结构的文档数据,比如可以有一个客户索引,商品分类索引,订单索引,索引有一个名称。一个index包含很多document,一个index就代表了一类类似的或者相同的document。比如说建立一个product index,商品索引,里面可能就存放了所有的商品数据,所有的商品document。
类似于关系型数据库中的 数据库
1.3.Type:类型
每个索引库里都可以有一个或多个type,type是index中的一个逻辑数据分类,一个type下的document,都有相同的field,比如博客系统,有一个索引,可以定义用户数据type,博客数据type,评论数据type。
类似于关系型数据库中的表
1.4.Document&field
文档,es中的最小数据单元,一个document可以是一条客户数据,一条商品分类数据,一条订单数据,通常用JSON数据结构表示,每个index下的type中,都可以去存储多个document。一个document里面有多个field,每个field就是一个数据字段。
document类似于关系型数据库表中的一行数据
| ElastciSearch全文搜索 | Mysql关系型数据库 |
|---|---|
| 索引库(index) | 数据库(database) |
| 文档类型(Type) | 数据表(Table) |
| 文档(Document) | 一行数据(Row) |
| 字段(field) | 一个列(column) |
| 文档ID | 主键ID |
| 查询(Query DSL) | 查询(SQL) |
| GET http://… | SELECT * FROM … |
| PUT http:// | UPDATE table set… |
2.索引库CRUD
2.1增加索引库
创建一个名字为 shopping的索引库,5个Master Shard分片,每个Master Shard分片有1个Replica Shard从分片
PUT shopping
{
"settings":{
"number_of_shards":5,
"number_of_replicas":1
}
}
2.2.查询索引库
查询所有索引库
GET _cat/indices?v
查看指定索引库
GET _cat/indices/shopping
2.3.删除索引库
DELETE 名字
2.4.修改索引库
删除再添加
3.文档的CRUD
3.1.添加文档
我们以员工对象为例,我们首先要做的是存储员工数据,每个文档代表一个员工。在ES中存储数据的行为就叫做索引(indexing),文档归属于一种类型(type),而这些类型存在于索引(index)中,我们可以简单的对比传统数据库和ES的对应关系:
| ES | Mysql |
|---|---|
| _index(索引库) | 数据库 |
| _type(文档类型) | 表 |
| _document(文档对象) | 一行数据 |
| _id(文档ID) | 主键ID |
| field(字段) | 列 |
ES集群可以包含多个索引(indices)(数据库),每一个索引库中可以包含多个类型(types)(表),每一个类型含有多个文档(documents)(行),然后每个文档包含多个字段(Fields)(列)。
- 基本语法
指定ID创建索引文档
PUT index/type/id
{
JSON,文档内容
}
--解释---------------------------------------
PUT 索引库/文档类型/文档id
{
JSON格式,文档原始数据
}
使用内置ID创建索引文档
POST index/type/
{
JSON,文档内容
}
--解释---------------------------------------
PUT 索引库/文档类型/
{
JSON格式,文档原始数据
}
没有指定文档ID,ES会自动生成ID
- 案例
PUT crm/user/11
{
"id":11,
"username":"zs",
"age":18,
"name":"zs",
"sex":1,
"join_date": 1584092062348
}
解释:添加id为11的用户 , 索引库为 crm,类型为 User
【注意】:如果不指定文档的id,ES会自动生成文档id
3.2.获取文档
- 获取指定文档
GET 索引库/类型/文档ID
- 指定返回的列
GET /crm/user/123?_source=fullName,email
- 只要内容不要元数据
GET /crm/user/123/_source
3.3.修改文档
-
整体修改
全量修改的语法跟添加文档语法一样,如果文档已经存在就是修改,否则就是新增,
文档修改过程:1.标记删除旧文档,2.添加新文档
PUT {index}/{type}/{id}
{
"id":11,
"username":"zs"
}
注意:上面的修改会把ES中的数据全部覆盖,即age字段会消失。
-
局部修改
局部修改过程: 1.检索旧文档 , 2.修改文档 ,3.标记删除旧文档 , 4.添加新文档
POST /crm/user/123/_update
{
"doc":{
"id" : 11,
"username": "xx"
}
}
注意:上面修改只会修改id,和username字段,age字段不会作任何改变。
2.4.删除文档
DELETE {index}/{type}/{id}
4.文档简单查询
4.1.基本查询
- 查询所有 - 查询所有库里面的
GET _search
- 查询指定索引库
GET crm/_search
- 查询指定类型
GET crm/user/_search
- 查询指定文档
GET crm/user/11
4.2.分页查询
&size=2&from=2
-
size: 每页条数
-
form:从多少条数据开始查
4.3.字符串查询
条件查询+分页+排序
GET crm/user/_search?q=age:17&size=2&from=2&sort=id:desc&_source=id,username
字符串查询(query string)其实就是在url后面以字符串的方式拼接各种查询条件,这种方式不推荐,因为条件过多,拼接起来比较麻烦
查询URL可携带参数:
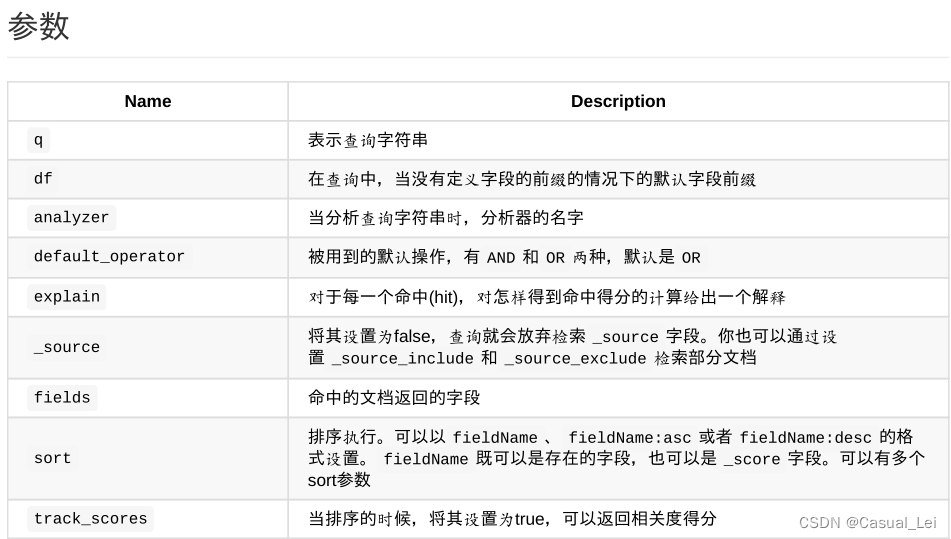

4.4.批量查询
批量查询很重要,对相比单个查询来说,批量查询性能更高。
- 同索引库同类型 - 推荐
GET ronghuanet/blog/_mget
{
"ids" : [ "2", "1" ]
}
五.DSL查询与DSL过滤
1.DSL查询
1.1.什么是DSL查询
对于简单查询,使用查询字符串比较好,但是对于复杂查询,由于条件多,逻辑嵌套复杂,查询字符串不易组织与表达,且容易出错,因此推荐复杂查询通过DSL使用JSON内容格式的请求体代替。
DSL查询是由ES提供丰富且灵活的查询语言叫做DSL查询(Query DSL),它允许你构建更加复杂、强大的查询。DSL(Domain Specific Language特定领域语言)以JSON请求体的形式出现。DSL有两部分组成:DSL查询(like)和DSL过滤(非like)。
1.2.DSL查询语法
一个常用的相对完整的DSL查询:
GET /crm/user/_search
{
"query": {
"match_all": {}
},
"from": 20,
"size": 10,
"_source": ["username", "age", "id"],
"sort": [{"join_date": "desc"},{"age": "asc"}]
}
上面查询 , match_all 表示 查询所有数据,查询返回fullName,age和email几个列,按照加入日期和年龄进行排序
1.3.DSL查询案例
GET /crm/user/_search
{
"query" : {
"match" : {
"username" : "老郑"
}
}
}
查询username中包含“老郑”的内容,match指的是“标准查询”,该查询方式会对查询的内容进行分词。DSL查询可以支持的查询方式很多,如term词元查询 ,range范围查询等等。
2.DSL过滤
2.1.什么是DSL过滤
DSL过滤语句和DSL查询语句非常相似,但是它们的使用目的却不同:DSL过滤查询文档的方式更像是对于我的条件"有"或者"没有"(等于 ;不等于),而DSL查询语句则像是"有多像"(模糊查询)。
2.2.查询与过滤的区别
DSL过滤和DSL查询在性能上的区别:
-
过滤结果可以缓存并应用到后续请求。-> 精确过滤后的结果拿去模糊查询性能高
-
查询语句同时匹配文档,计算相关性,所以更耗时,且不缓存。
-
过滤语句可有效地配合查询语句完成文档过滤。
总结:需要模糊查询的使用DSL查询 ,需要精确查询的使用DSL过滤,在开发中组合使用(组合查询) ,关键字查询使用DSL查询,其他的都是用DSL过滤。
2.3.DSL查询+过滤语法
存储的内容:chen whale 搜索的内容: whale zhang
GET /crm/user/_search
{
"query": {
"bool": { //booleanQuery 组合
"must": [{ //与(must) 或(should) 非(must not)
"match": { //match : 匹配,吧查询的内容分词后去查询
"username": "zs"
},
}],
"should": [{ //与(must) 或(should) 非(must not)
"match": { //match : 匹配,吧查询的内容分词后去查询
"username": "zs"
},
}],
"filter": {
"term": {
"name": "zs ls"
}
},
"filter": {
"term": {
"name": "zs ls"
}
},
"filter": {
"term": {
"name": "zs ls" # name = "zs ls"
}
}
}
},
"from": 20,
"size": 10,
"_source": ["name", "age", "username"],
"sort": [{
"join_date": "desc"
}, {
"age": "asc"
}]
}
解释:
-
query : 查询,所有的查询条件在query里面
-
bool : 组合搜索bool可以组合多个查询条件为一个查询对象,这里包含了 DSL查询和DSL过滤的条件
-
must : 必须匹配 :与(must) 或(should) 非(must_not)
-
match:分词匹配查询,会对查询条件分词 , multi_match :多字段匹配
-
filter: 过滤条件
-
term:词元查询,不会对查询条件分词
-
from,size :分页
-
_source :查询结果中需要哪些列
-
sort:排序
2.4.综合案例
名称(name)中有 “zs” 的用户 ,性别sex是男生(1),年龄(age)在 18- 20之间,按照年龄(age)倒排序,查询第 1 页,每页10 条 ,查询结果中只需要 :id,name,username,age
GET /aigou/product/_search
{
"query":{
"bool": {
"must": [{
"match": {
"name": "zs"
}
}],
"filter": [
{
"range":{ //范围查询
"age":{
"gte":18,
"lte":20
}
}
},
{
"term": { //词元查询
"sex": 1
}
}
]
}
},
"from": 1,
"size": 10,
"_source": ["id", "name", "age","username"],
"sort": [{
"age": "desc"
}]
}
3.查询方式
在上面的案例中,我们接触了 match , range 等查询方式(查询对象),在ES还有很多其他的查询方式,在不同的场景中我们需要根据情况进行合理的选择。
3.1.全匹配(match_all)
普通搜索(匹配所有文档)
GET _search
{
"query": {
"bool": {
"must": [
{
"match_all": {}
}
],
"filter": {
"term": {
"name": "zs1"
}
}
}
}
}
3.2.标准查询(match和multi_match)
标准查询,可以理解为,分词查询有点像模糊匹配(like),会对查询的内容进行分词后,得到多个单词,分别带着多个单词去检索ES库,只要有一个单词能查出结果,整个查询就有结果。不管你需要全文本查询还是精确查询基本上都要用到它。
如下面的搜索会对Steven King分词,并找到包含Steven或King的文档,然后给出排序分值。
{
"query": {
"match": {
"fullName": "Steven King"
}
}
}
注意:上面效果如同 where fullName like "%Steven%" or fullName like "%King%"
提示:match一般只用于全文字段的匹配与查询,一般不用于过滤。
multi_match 查询允许你做 match查询的基础上同时搜索多个字段:
{
"query": {
"multi_match": {
"query": "Steven King",
"fields": ["fullName", "title"]
}
}
}
注意:上面的搜索同时在fullName和title字段中匹配。
3.3.单词搜索与过滤(Term和Terms)
单词/词元查询 , 可以理解为等值查询,字符串,数字等都可以使用它,把查询的内容看成一个整体去检索ES库
{
"query": {
"bool": {
"must": {
"match_all": {
}
},
"filter": {
"term": {
"username": "Steven King"
}
}
}
}
}
提示:上面的“Steven King”会被当成一个去term中匹配,它跟match不同的地方在于match会把“Steven King”分成“steven”和“king”分别取username中查询。
Terms支持多个字段查询
{
"query": {
"terms": {
"tags": [
"jvm",
"hadoop",
"lucene"
],
"minimum_match": 1
}
}
}
提示:minimum_match:至少匹配个数,默认为1
3.4.组合条件搜索与过滤(Bool)
组合搜索bool可以组合多个查询条件为一个查询对象,查询条件包括must、should和must_not。
例如:查询爱好有美女,同时也有喜欢游戏或运动,且出生于1990-06-30及之后的人。
{
"query": {
"bool": {
"must": [
{
"term": {
"hobby": "美女"
}
}
],
"should": [
{
"term": {
"hobby": "游戏"
}
},
{
"term": {
"hobby": "运动"
}
}
],
"must_not": [
{
"range": {
"birth_date": {
"lte": "1990-06-30"
}
}
}
],
"filter": [
...
]
}
}
}
上面案例如同:Hobby=美女 and (hobby=游戏 or hobby=运动) and birth_date >= 1990-06-30
提示: 如果 bool 查询下没有must子句,那至少应该有一个should子句。但是 如果有 must子句,那么没有 should子句也可以进行查询。
3.5.范围查询与过滤(range)
range过滤允许我们按照指定范围查找一批数据
gt 大于 gte 大于等于 lt 小于 lte 小于等于
{
"query": {
"range": {
"age": {
"gte": 20,
"lt": 30
}
}
}
}
上例中查询年龄大于等于20并且小于30。
gt:> gte:>= lt:< lte:<=
3.6.存在和缺失过滤器(exists和missing)
{
"query": {
"bool": {
"must": [
{
"match_all": {
}
}
],
"filter": {
"exists": {
"field": "gps"
}
}
}
}
}
提示:exists和missing只能用于过滤结果。
3.7.前匹配搜索与过滤(prefix)
和term查询相似,前匹配搜索不是精确匹配,而是类似于SQL中的like ‘key%’
{
"query": {
"prefix": {
"fullName": "王"
}
}
}
提示:上例即查询姓王的所有人。
3.8.通配符搜索(wildcard)
使用*代表0~N个,使用?代表1个。
{
"query": {
"wildcard": {
"fullName": "姚*鹏"
}
}
}
六.分词器安装和使用
1.基本概念
1.1.什么是分词
在全文检索理论中,文档的查询是通过关键字查询文档索引来进行匹配,因此将文本拆分为有意义的单词,对于搜索结果的准确性至关重要,因此,在建立索引的过程中和分析搜索语句的过程中都需要对文本进行分词。ES的倒排索引是分词的结果。
正排索引:通过id查找内容,mysql就是正排索引
倒排索引:先将原始数据根据分词器进行分词,语义转换,排序,分组等操作生成词元,词元对应文档id,再搜索时先通过词元找到文档id,再通过文档id找到对应的文档
1.2.理解分词的作用
分词器的作用至关重要,数据的查询结果是否精准跟分词器有很大的关系
为了方便理解,我们用一个模拟图跟踪一下ES创建倒排索引的过程,如有原始数据:
| ID | username | intro |
|---|---|---|
| 1 | zs | my name is zs |
| 2 | ls | my name is ls |
如果对intro进行倒排索引,ES会根据分词器进行分词 , 语义转换,排序, 分组等操作最终倒排索引如下:
| 词元 | ID倒排 |
|---|---|
| is | 1 -> 2 |
| ls | 2 |
| my | 1 -> 2 |
| name | 1 -> 2 |
| zs | 1 |
当ES进行关键字查询的时候,如需要查询“my” ,那么ES可以根据二分查找更快的定位到 my | 1 -> 2 , 根据ID值1 ,2直接取出结果。
2.IK分词器
2.1.为什么用IK分词器
ES默认对英文文本的分词器支持较好,但和lucene一样,如果需要对中文进行全文检索,那么需要使用中文分词器,同lucene一样,在使用中文全文检索前,需要集成IK分词器 - 大家都在用IK
在es以插件方式集成ik分词器
发请求使用分词器
2.2.安装IK分词器
1.下载ES的IK分词器
插件源码地址:https://github.com/medcl/elasticsearch-analysis-ik
2.解压elasticsearch-analysis-ik-5.2.2.zip文件
并将解压后的内容放置于ES根目录/plugins/ik
3.IK分词器配置
在ik/config 目录可以对分词器进行配置,如停词 , 自定义字典等。
4.IK分词测试
POST _analyze
{
"analyzer":"ik_smart",
"text":"中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"
}
提示:IK分词器指定:ik_smart ; ik_max_word , ik_max_word 相比 ik_smart 来说会将文本做最细粒度的拆分。
七.文档类型映射
1什么是文档映射
ES的文档映射(mapping)机制用于进行字段类型确认,将每个字段匹配为一种确定的数据类型。就如果Mysql创建表时候指定的每个column列的类型。 为了方便字段的检索,我们会指定存储在ES中的字段是否进行分词,但是有些字段类型可以分词,有些字段类型不可以分词,所以对于字段的类型需要我们自己去指定。
需要注意的是,我们在Mysql建表过程是:
Mysql创建数据库 -> 创建表(指定字段类型) -> crud数据 而在ES中也是一样,
ES创建索引库 -> 文档类型映射 - 给字段设置类型 -> crud文档
2 默认映射
没有进行自定义类型映射的时候,直接添加数据。就会按照默认规则进行映射,这种映射叫做默认映射
查看索引类型的映射配置:GET {indexName}/_mapping/{typeName}
ES在没有配置Mapping的情况下新增文档,ES会尝试对字段类型进行猜测,并动态生成字段和类型的映射关系。
| 内容 | 默认映射类型 |
|---|---|
| JSON type | Field type |
| Boolean: true or false | “boolean” |
| Whole number: 123 | “long” |
| Floating point: 123.45 | “double” |
| String, valid date:“2014-09-15” | “date” |
| String: “foo bar” | “text” |
3 自定义映射
3.1 es支持哪些字段类型
- 基本字段类型
| 字符串 | text(分词lucene TextField) | keyword(不分词lucene StringField) | |||
|---|---|---|---|---|---|
| 数字 | long | integer | short | double | float |
| 日期 | date | ||||
| 逻辑 | boolean |
- 复杂字段类型
| 对象类型 | object |
|---|---|
| 数组类型 | array |
| 地理位置 | geo_point,geo_shape |
3.2 详细映射写法
字段映射的常用属性配置列表 - 即给某个字段执行类的时候可以指定以下属性
| type | 类型:基本数据类型,integer,long,date,boolean,keyword,text… |
|---|---|
| enable | 是否启用:默认为true。 false:不能索引、不能搜索过滤,仅在_source中存储 |
| boost | 权重提升倍数:用于查询时加权计算最终的得分。 |
| format | 格式:一般用于指定日期格式,如 yyyy-MM-dd HH:mm:ss.SSS |
| ignore_above | 长度限制:长度大于该值的字符串将不会被索引和存储。 |
| ignore_malformed | 转换错误忽略:true代表当格式转换错误时,忽略该值,被忽略后不会被存储和索引。 |
| include_in_all | 是否将该字段值组合到_all中。 |
| null_value | 默认控制替换值。如空字符串替换为”NULL”,空数字替换为-1 |
| store | 是否存储:默认为false。true意义不大,因为**_source**中已有数据 |
| index | 索引模式:analyzed (索引并分词,text默认模式), not_analyzed (索引不分词,keyword默认模式),no(不索引) |
| analyzer | 索引分词器:索引创建时使用的分词器,如ik_smart,ik_max_word,standard |
| search_analyzer | 搜索分词器:搜索该字段的值时,传入的查询内容的分词器。如ik_smart,ik_max_word,standard |
| fields | 多字段索引:当对该字段需要使用多种索引模式时使用。如:城市搜索
New York"city":“city”:{
“type”: “text”,
“analyzer”: “ik_smart”,
“fields”: {
“raw”: {
“type”: “keyword”
}
}
}
解释:相当于给 city取了一个别名 city.raw,city的类型为text , city.raw的类型keyword
搜索 city分词 ; 搜索city.raw 不分词那么以后搜索过滤和排序就可以使用city.raw字段名 |
3.3.自定义映射简单实现
注意:如果索引库已经有数据了,就不能再添加映射了
2.1.创建新的索引库
put yaoasang
2.2.单类型创建映射
put yaoasang/goods/_mapping
{
"properties": {
"id": {
"type": "long"
},
"name": {
"type": "text",
"analyzer": "ik_smart",
"search_analyzer": "ik_smart"
}
}
}
解释:给aigou索引库中的是goods类型创建映射 ,id指定为long类型 , name指定为text类型(要分词),analyzer分词使用ik,查询分词器也使用ik
3.4. 自定义映射细节
1.对象映射
{
"id" : 1,
"girl" : {
"name" : "王小花",
"age" : 22
}
}
文档映射
{
"properties": {
"id": {"type": "long"},
"girl": {
"properties":{
"name": {"type": "keyword"},
"age": {"type": "integer"}
}
}
}
}
2.基本类型数组映射
{
"id" : 1,
"hobbys" : ["王小花","林志玲"]
}
文档映射
{
"properties": {
"id": {"type": "long"},
"hobbys": {"type": "keyword"}
}
}
解释:数组的映射只需要映射一个元素即可,因为数组中的元素类型是一样的。
3.对象数组
{
"id" : 1,
"girl":[{"name":"林志玲","age":32},{"name":"赵丽颖","age":22}]
}
文档映射
"properties": {
"id": {
"type": "long"
},
"girl": {
"properties": {
"age": { "type": "long" },
"name": { "type": "text" }
}
}
}
2.5.全局映射(了解)
索引库中多个类型(表)的字段是有相同的映射,如所有的ID都可以指定为integer类型,基于这种思想,我们可以做全局映射,让所有的文档都使用全局文档映射。全局映射可以通过动态模板和默认设置两种方式实现。
- 默认方式:default
索引下所有的类型映射配置会继承_default_的配置,如:
PUT {indexName}
{
"mappings": {
"_default_": {
"_score": {
"enabled": false
}
},
"user": {},
"dept": {
"_score": {
"enabled": true
}
}
}
关闭默认的 _all ,dept自定义开启 all
- 动态模板
在实际应用场景中,一个对象的属性中,需要全文检索的字段较少,大部分字符串不需要分词,因此,需要利用全局模板覆盖自带的默认模板
PUT _template/global_template //创建名为global_template的模板
{
"template": "*", //匹配所有索引库
"settings": { "number_of_shards": 5 }, //匹配到的索引库创建5个主分片
"mappings": {
"_default_": {
"_all": {
"enabled": false //关闭所有类型的_all字段
},
"dynamic_templates": [
{
"string_as_text": {
"match_mapping_type": "string",//匹配类型string username="xxx xxx"
"match": "*_text", //匹配字段名字以_text结尾
"mapping": {
"type": "text",//将类型为string的字段映射为text类型
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word",
"fields": {
"raw": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
},
{
"string_as_keyword": {
"match_mapping_type": "string",//匹配类型string
"mapping": {
"type": "keyword"//将类型为string的字段映射为keyword类型
}
}
}
]
}
}}
PS : 映射方式优先级 (低 -> 高):默认 -> 全局 -> 自定义
2.6.最佳实践
在实际项目中,我们按照如下流程操作ES
1.建索引库
2.全局映射-可选
3.自定义映射
4.Java-API做CRUD
八.JavaApi操作ES
1.集成ES
官方文档API:https://www.elastic.co/guide/en/elasticsearch/client/java-api/index.html
1.1.导入依赖
下面采用ES提供的Jar进行ES操作
<dependencies>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>transport</artifactId>
<version>6.8.6</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>compile</scope>
</dependency>
</dependencies>
1.2.连接ElasticSearch
编写工具
public class ESClientUtil {
public static TransportClient getClient(){
TransportClient client = null;
Settings settings = Settings.builder()
.put("cluster.name", "elasticsearch").build();
try {
client = new PreBuiltTransportClient(settings)
.addTransportAddress(new TransportAddress(InetAddress.getByName("127.0.0.1"), 9300));
} catch (UnknownHostException e) {
e.printStackTrace();
}
return client;
}
}
2.文档CRUD
2.1.添加文档
@Test
public void testAdd() {
//获取客户端对象
TransportClient client = ESClientUtil.getClient();
//创建索引
IndexRequestBuilder indexRequestBuilder = client.prepareIndex("shopping", "user", "1");
Map<String,Object> data = new HashMap<>();
data.put("id",1);
data.put("username","zs");
data.put("age",11);
//获取结果
IndexResponse indexResponse = indexRequestBuilder.setSource(data).get();
System.out.println(indexResponse);
client.close();
}
2.2.获取文档
GetResponse response = client.prepareGet("crm", "vip", "1").get();
2.3.更新文档
@Test
public void testUpdate(){
//获取客户端对象
TransportClient client = ESClientUtil.getClient();
//修改索引
UpdateRequestBuilder updateRequestBuilder = client.prepareUpdate("shopping", "user", "1");
Map<String,Object> data = new HashMap<>();
data.put("id",1);
data.put("username","zs");
data.put("age",11);
//获取结果设置修改内容
UpdateResponse updateResponse = updateRequestBuilder.setDoc(data).get();
System.out.println(updateResponse);
client.close();
}
2.4.删除文档
@Test
public void testDelete(){
//获取客户端对象
TransportClient client = ESClientUtil.getClient();
DeleteRequestBuilder deleteRequestBuilder = client.prepareDelete("shopping", "user", "1");
DeleteResponse deleteResponse = deleteRequestBuilder.get();
System.out.println(deleteResponse);
client.close();
}
2.5.批量操作
@Test
public void testBuilkAdd(){
//获取客户端对象
TransportClient client = ESClientUtil.getClient();
BulkRequestBuilder bulkRequestBuilder = client.prepareBulk();
Map<String,Object> data1 = new HashMap<>();
data1.put("id",11);
data1.put("username","zs");
data1.put("age",11);
bulkRequestBuilder.add(client.prepareIndex("shopping", "user", "11").setSource(data1));
Map<String,Object> data2 = new HashMap<>();
data2.put("id",22);
data2.put("username","zs");
data2.put("age",11);
bulkRequestBuilder.add(client.prepareIndex("shopping", "user", "11").setSource(data2));
BulkResponse bulkItemResponses = bulkRequestBuilder.get();
Iterator<BulkItemResponse> iterator = bulkItemResponses.iterator();
while(iterator.hasNext()){
BulkItemResponse next = iterator.next();
System.out.println(next.getResponse());
}
client.close();
}
2.6.查询
@Test
public void testSearch(){
//获取客户端对象
TransportClient client = ESClientUtil.getClient();
SearchRequestBuilder searchRequestBuilder = client.prepareSearch("shopping");
searchRequestBuilder.setTypes("user");
searchRequestBuilder.setFrom(0);
searchRequestBuilder.setSize(10);
searchRequestBuilder.addSort("age", SortOrder.ASC);
//查询条件
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
List<QueryBuilder> must = boolQueryBuilder.must();
must.add(QueryBuilders.matchQuery("username" , "zs"));
List<QueryBuilder> filter = boolQueryBuilder.filter();
filter.add(QueryBuilders.rangeQuery("age").lte(20).gte(10));
filter.add(QueryBuilders.termQuery("id",11));
searchRequestBuilder.setQuery(boolQueryBuilder);
SearchResponse searchResponse = searchRequestBuilder.get();
SearchHits hits = searchResponse.getHits();
System.out.println("条数:"+hits.getTotalHits());
for (SearchHit hit : hits.getHits()) {
System.out.println(hit.getSourceAsMap());
}
client.close();
}















 5091
5091











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









