







文章目录
Streamsets介绍
Streamsets是一款图形化的数据集成工具。
StreamSets 数据连接器,分为源(Origin)和目标(Destination)两类。数据从源进入,经过转换,传输到目标,从而构建出一条数据管道(Pipeline)。
准备
配置Kerberos认证
- sdc.properties文件中添加如下配置

- 重启streamsets
安装外部库
- 创建目录
mkdir /opt/sdc-extras - 授权用户
chown -R sdc:sdc /opt/sdc-extras - 设置环境变量
export STREAMSETS_LIBRARIES_EXTRA_DIR="/opt/sdc-extras/" - 设置安全策略
sdc-security.policy文件中添加
// user-defined external directory
grant codebase “file:///opt/sdc-extras/-” {
permission java.security.AllPermission;
}; - 重启streamsets
- 上传mysql的jdbc驱动
mysql开启binlog
- 此处省略
1.mysql导入hbase
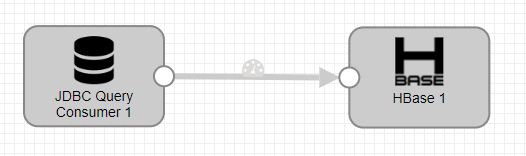
配置JDBC Query Consumer

- JDBC Connection String:jdbc连接字符串
- Incremental Mode:增量模式,启用该模式后mysql插入新数据就会输出到下一个处理器
- SQL Query:sql查询语句,开启增量查询后使用’${OFFSET}'变量获取修改的字段
- Initial Offset:初始偏移,新增id为1,所以从0开始
- Offset Column:根据哪一个字段检查增量

- 设置jdbc驱动
配置HBase

- Stage Library:本次使用HDP 2.6.2.1-1

- ZooKeeper Quorum:设置ZooKeeper地址
- ZooKeeper Parent Znode:HBase中zookeeper.znode.parent设置
- Fields:设置对应的列
- Kerberos Authentication:勾选以后启用Kerberos身份认证
2.mysql导入hive

配置JDBC Query Consumer
- 配置同上
配置Hive Metadata

- Stage Library:本次使用2.6.1.0-129

- JDBC URL:jdbc连接hive语句,查看更多URL写法,点击此处。
- Hadoop Configuration Directory:将core-site.xml,hdfs-site.xml,hive-site.xml放到该目录下,如果提示权限不足可以放到sdc目录下

- Database Expression:数据库名
- Table Name:表名
- Partition Configuration:删除其中的字段,本例只手动创建mysql表,hive表由streamsets自动创建

- Data Format:数据格式选择Avro
配置Hadoop FS

- Stage Library:设置同上

- Hadoop FS URI:设置hdfs的URI
- Kerberos Authentication:启用Kerberos身份验证
- Hadoop FS Configuration Directory :配置文件设置同上

- Idle Timeout:时间设置为3秒写入一次
- Directory in Header:勾选该属性
- Use Roll Attribute:勾选该属性
- Roll Attribute Name:选择roll

- Data Format :数据格式选择Avro
配置Hive Metastore
Stage Library
- Stage Library:配置同上

- 配置同上
验证
- mysql表结构
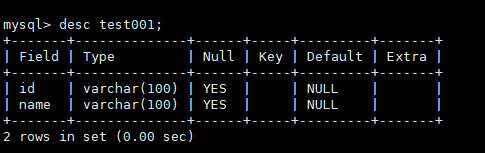
- 启动管道,在mysql中添加一行记录

- 查看streamsets监控,Input数量为1

- 查看hive,发现已经创建好表并且添加好新增的列

3.创建自定义节点
- 官方文档
- 以Origins为例,创建maven模板项目

- sdc会反复调用product()方法创建数据流

- 根据模板构建项目

- 复制文件到user-libs下

- 使用刚刚创建的自定义节点
- 测试刚刚的自定义节点

4.任务调度
- 情景:任务执行结束以后停止管道并激活其他任务
执行完成后停止管道

- Produce Events:勾选该选项以用来创建活动

- Preconditions:JDBC Query Consumer会生成查询成功,查询失败和无数据三种事件类型,此处只需要传递查询成功类型,以用来告知查询完毕。更多事件类型请查阅此处
- On Record Error:选择Discard
停止管道后激活其他任务

- Stop Event :设置为写入其他管道

- SDC RPC Connection :如图设置
- SDC RPC ID :为管道起一个ID

- 创建一个新的管道并如图设置,SDC RPC会接收其他管道发送的信息
验证
- 在mysql中添加一条数据

- 启动SDC RPC管道

- 启动mysql_to_hive管道稍等后提示管道执行完成,并且管道会停止

- 查看SDC RPC管道,看到监控界面有输出

5.读取kafka消息
准备
- 本次使用没有LDAP身份验证的RPM,tarball或Cloudera Manager安装的安装方式
- Tarball或RPM安装在使用systemd init系统的操作系统上作为服务启动的启动方式
- 创建/etc/sdc/config/kafka_jaas.conf文件,内容如图

- 修改/usr/lib/systemd/system/sdc.service文件,内容如图

- 重新加载配置
systemctl daemon-reload - 重启streamsets
service sdc restart
kafka Consumer配置

- Stage Library:选择2.6.2.1-1

配置如图
验证
kafka推送消息后查看仪表盘
















 699
699











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









