







实例百度网盘下载(永久有效):
链接: https://pan.baidu.com/s/1ltXeOlMEMYyfJD6eplUg1A 密码: 3ii5
实例下载:
streamsets2.6.0.1版本使用需要的环境
- 确保streamsets2.6.0.1平台能够正常运行,无报错
- streamsets使用案例.zip所有的实例都是streamsets2.6.0.1版本的
Streamsets2.6.0.1 使用案例
一、读取JDBC映射成Hive实例
-
使用场景
以下场景适用于从Oracle或PostgreSQL或其他支持JDBC的数据库,读取数据源分为多表消费(JDBC Query Consumer )和单表消费(JDBC Query Consumer),
直接把数据映射成Hive表,方便直接查询Hive的数据
-
示例下载
请解压streamsets使用案例.zip 文件查找压缩文件中的yt50_cancel_record.json文件,导入到平台中即可
-
实例展示
yt50_cancel_record.json
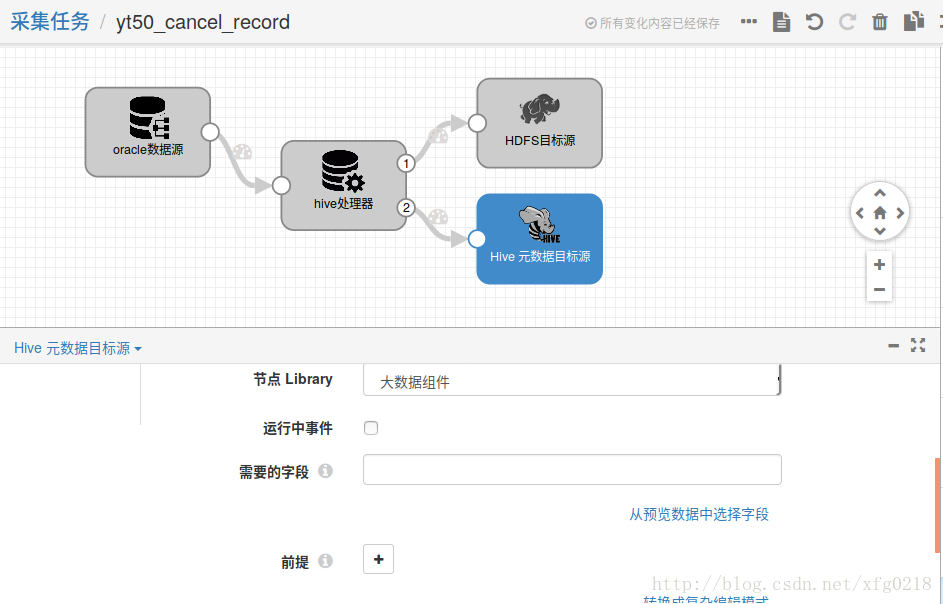

二、读取JDBC数据映射成Hive表,当读完JDBC数据源中的数据时让任务自动停止
-
使用场景
以下实例主要读取JDBC中的数据,当读完数据源中的数据后让程序自动停止
-
示例下载
请解压streamsets使用案例.zip 文件查找压缩文件中的yt50_return_by_statistics.json文件,导入到平台中即可
-
示例展示
yt50_return_by_statistics.json


三、采用单表消费的形式读取JDBC数据源中的数据映射到Hive表中
-
使用场景
以下示例主要使用streamsets2.6.0.1中的(JDBC 查询消费者)组件来读取oracle中的一个表来进行消费,也可以在(JDBC 查询消费者)中的SQL 查询处写SQL,
使用次组件比较灵活,容易配合
-
示例下载
请解压streamsets使用案例.zip 文件查找压缩文件中的yt50_cancle_record_by_statistics_date_partition.json文件,导入到平台中即可
-
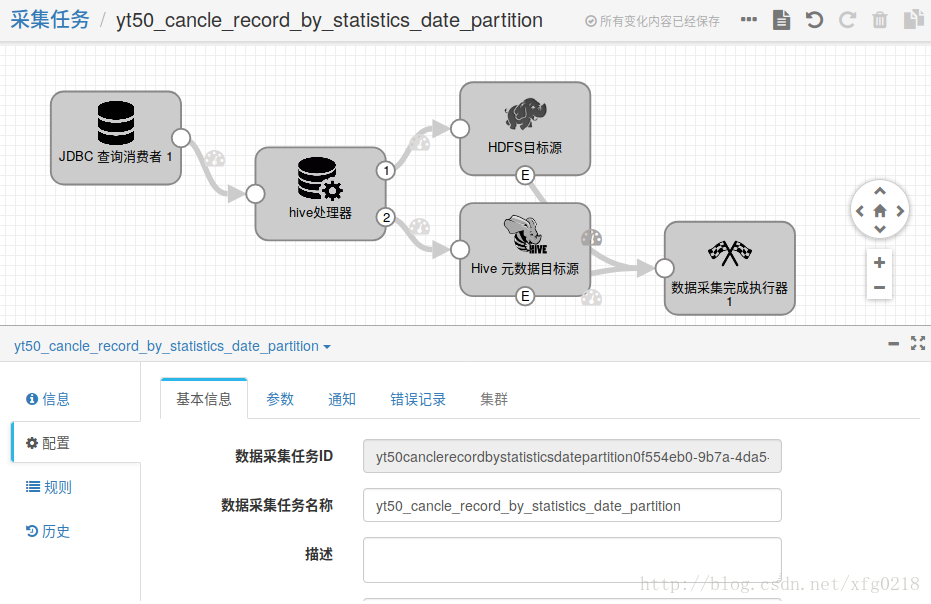
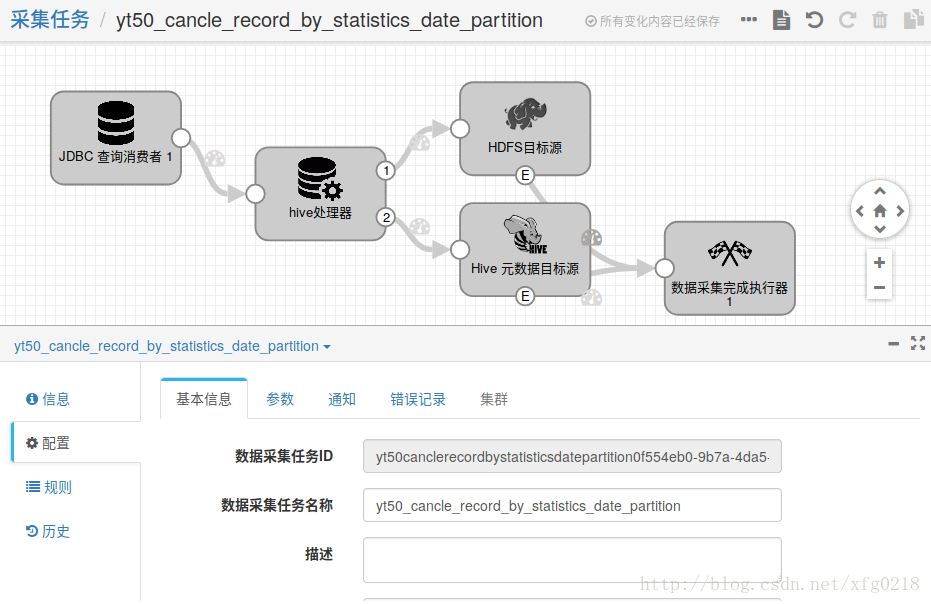
示例展示
yt50_cancle_record_by_statistics_date_partition.json

四、使用streamsets2.6.0.1版本中的jdbc多表消费这组件消费oracle的数据到Hbase中
-
使用场景
本示例主要使用streamsets2.6.0.1版本中的jdbc多表消费者组件消费oracle数据库中的数据并存放到Hbase中,如果不加数据采集完成执行器组件,任务会一直处于等待状态 -
示例下载
请解压streamsets使用案例.zip 文件查找压缩文件中的oracle-Hbase.json文件,导入到平台中即可
-
示例展示
oracle-Hbase.json

五、使用streamsets2.6.0.1版本导入非结构化数据案例
结构化与非结构化名词解释:https://zhidao.baidu.com/question/1541228834938237347.html
-
使用场景
本示例主要使用streamsets2.6.0.1版本中的FTP作为数据源读取非结构化数据,FTP组件能读取子目录下的文件,放到HDFS中,如果任务启动此任务会发现新的数据,一直处于等待的状态
-
示例下载
请解压streamsets使用案例.zip 文件查找压缩文件中的unstructured-local-to-hdfs-admin.json文件,导入到平台中即可
-
示例展示
unstructured-local-to-hdfs-admin.json

六、使用streamsets2.6.0.1版本导入结构化数据案例
结构化与非结构化名词解释:https://zhidao.baidu.com/question/1541228834938237347.html
-
使用场景
本示例主要使用streamsets2.6.0.1版本中的FTP作为数据源读取结构化数据,FTP组件能读取子目录下的文件,放到HDFS中,如果任务启动此任务会发现新的数据,一直处于等待的状态
-
示例下载
请解压streamsets使用案例.zip 文件查找压缩文件中的structured-local-to-hdfs.json文件,导入到平台中即可
-
示例展示
structured-local-to-hdfs.json

七、streamsets2.6.0.1版本使用FTP组件把数据导入到HIVE中
-
使用场景
本示例主要使用streamsets2.6.0.1版本的FTP组件来把结构化数据导入到HIVE中,可以直接查询HIVE中的数据
-
示例下载
请解压streamsets使用案例.zip 文件查找压缩文件中的ftp-hive-hdfs.json文件,导入到平台中即可
-
示例展示
ftp-hive-hdfs.json

八、使用streamsets2.6.0.1版本中的FTP组件把结构化数据导入到KAFKA中
-
使用场景
本示例主要使用streamsets2.6.0.1中的FTP组件把数据导入到KAFKA中,任务启动后,任务便会一直处于等待状态,任务会一直运行
-
实例下载
请解压streamsets使用案例.zip 文件查找压缩文件中的YS_Kafka.json文件,导入到平台中即可
-
示例展示
YS_Kafka.json

九、使用streamsets2.6.0.1版本中的kafka组件经过spark组件的处理后放到pg数据库中
-
使用场景
本示例主要私用streamsets2.6.0.1中的Kafka的组件获取kafka中的数据,然后经过Spark Evaluator组件的处理,最后把处理好的数据存放到pg中
-
示例下载
请解压streamsets使用案例.zip 文件查找压缩文件中的kafka-spark-pg.json文件,导入到平台中即可
-
示例展示
kafka-spark-pg.json
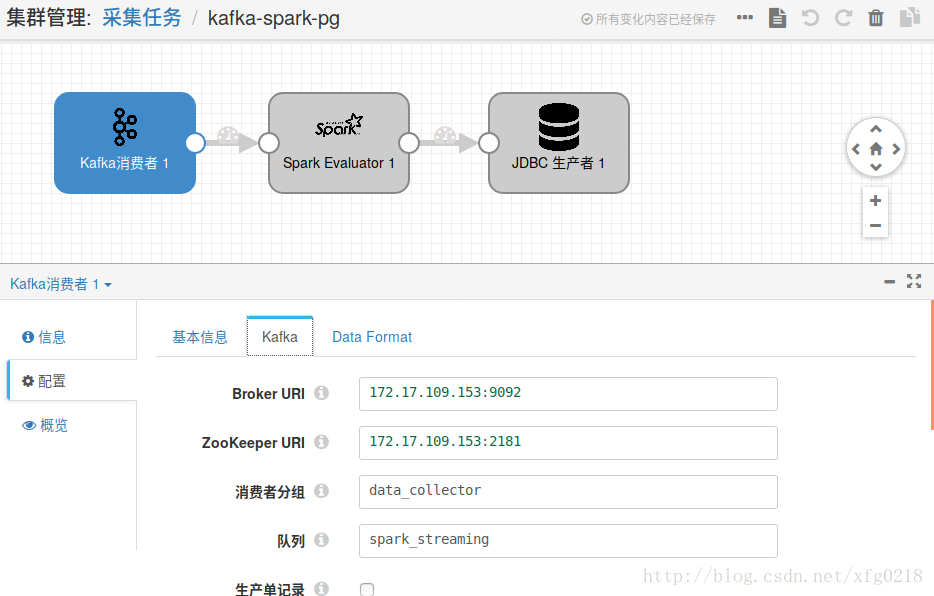

十、使用JDBC Query Consumer组件经过其他组件的过滤最后再把数据存放到pg中
-
使用场景
本示例主要使用streamsets2.6.0.1的JDBC Query Consumer组件读取pg数据库中的数据,经过Field Renamer/Value Replacer/Field Type Converter /
Field Masker操作后最后再把数据存放到pg中,当此任务开启后便会一直运行,会发现pg数据源中的新数据进入
-
示例下载
请解压streamsets使用案例.zip 文件查找压缩文件中的pg-transformation-pg.json文件,导入到平台中即可
-
示例展示
pg-transformation-pg.json
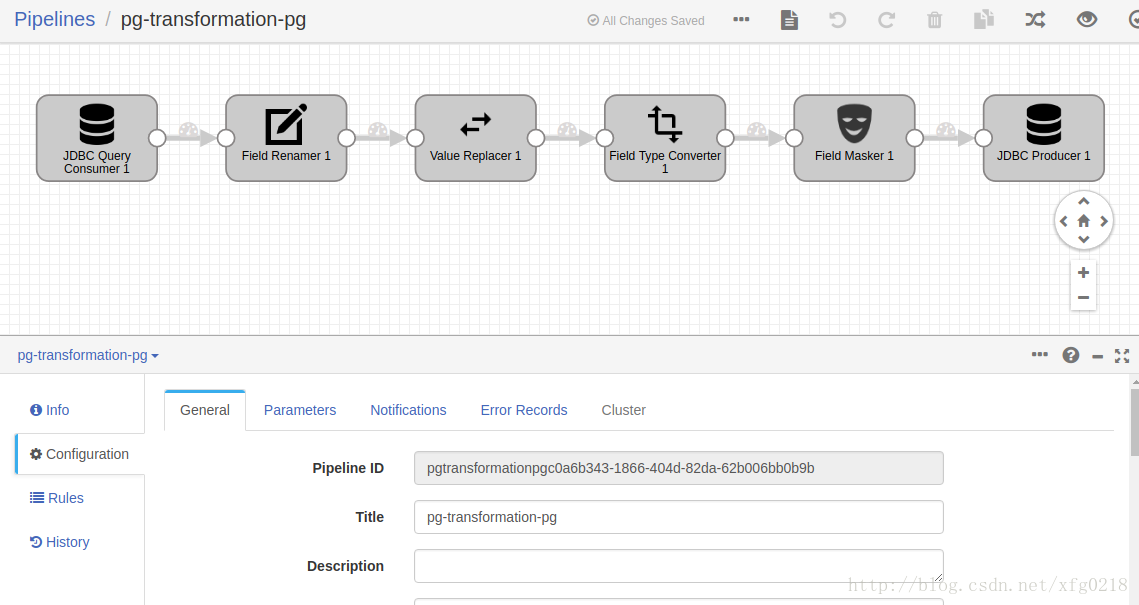

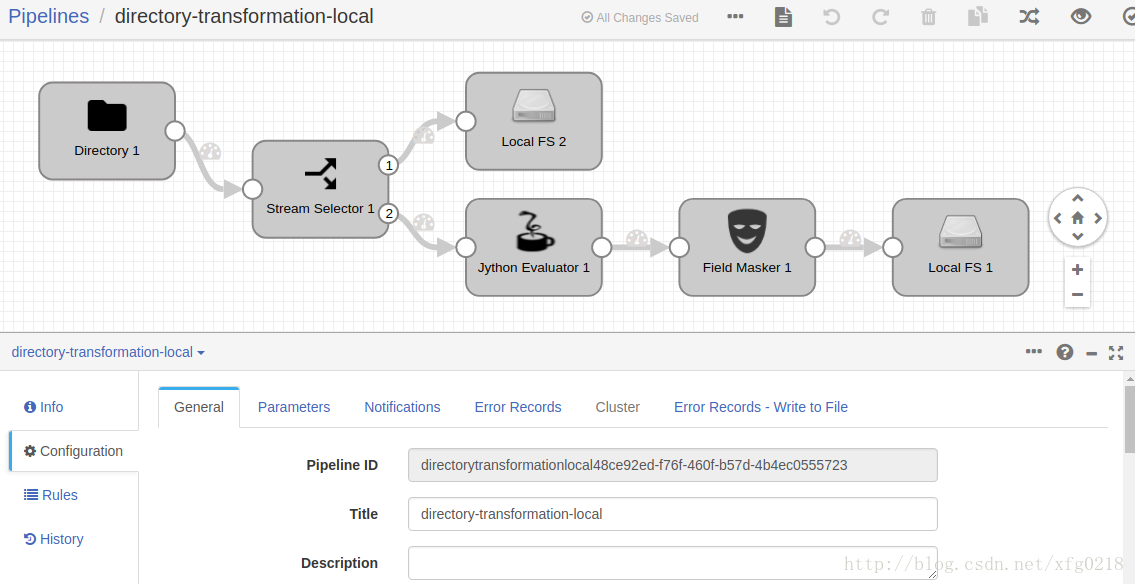
十一、streamsets2.6.0.1版本中的Stream Selector组件的使用
-
使用场景
本示例使用streamsets2.6.0.1中的Stream Selector组件来对数据源中的数据进行不同的操作,例如 把每一行中包含12的数据放到其他地方
-
示例下载
请解压streamsets使用案例.zip 文件查找压缩文件中的directory-transformation-local.json文件,导入到平台中即可
-
示例展示
directory-transformation-local.json

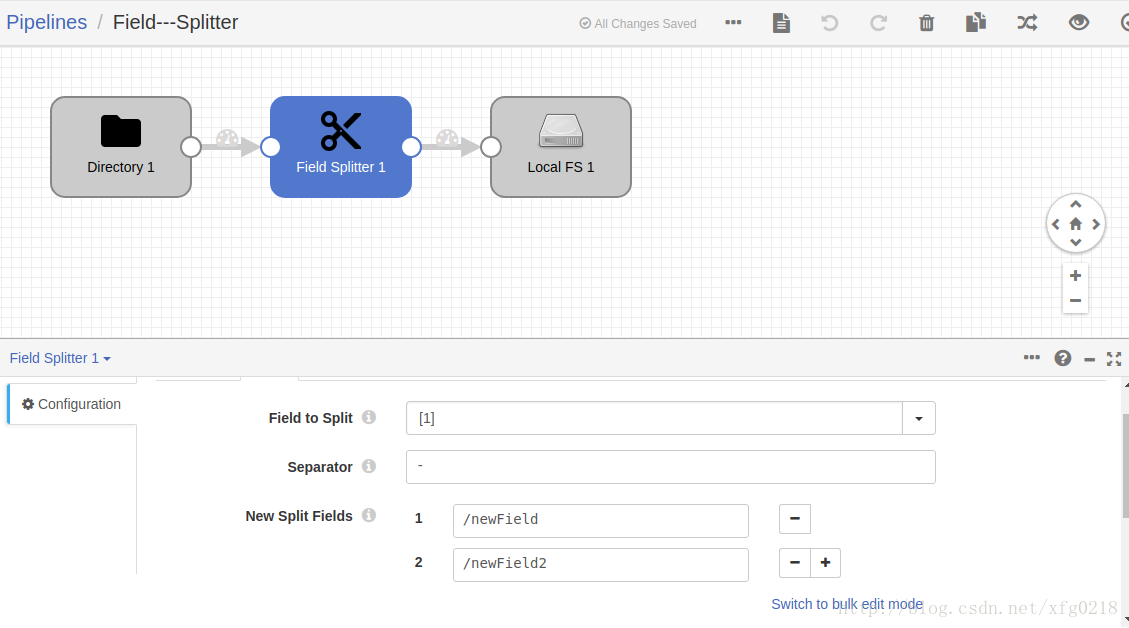
十二、streamsets2.6.0.1版本中的Field Splitter来对结构化的数据进行分割
-
使用场景
streamsets2.6.0.1版本中的Field Splitter组件对结构化数据按照制定的分隔符对字段分割,并映射成新的字段
-
示例下载
请解压streamsets使用案例.zip 文件查找压缩文件中的Field---Splitter.json文件,导入到平台中即可
-
示例展示
Field---Splitter.json

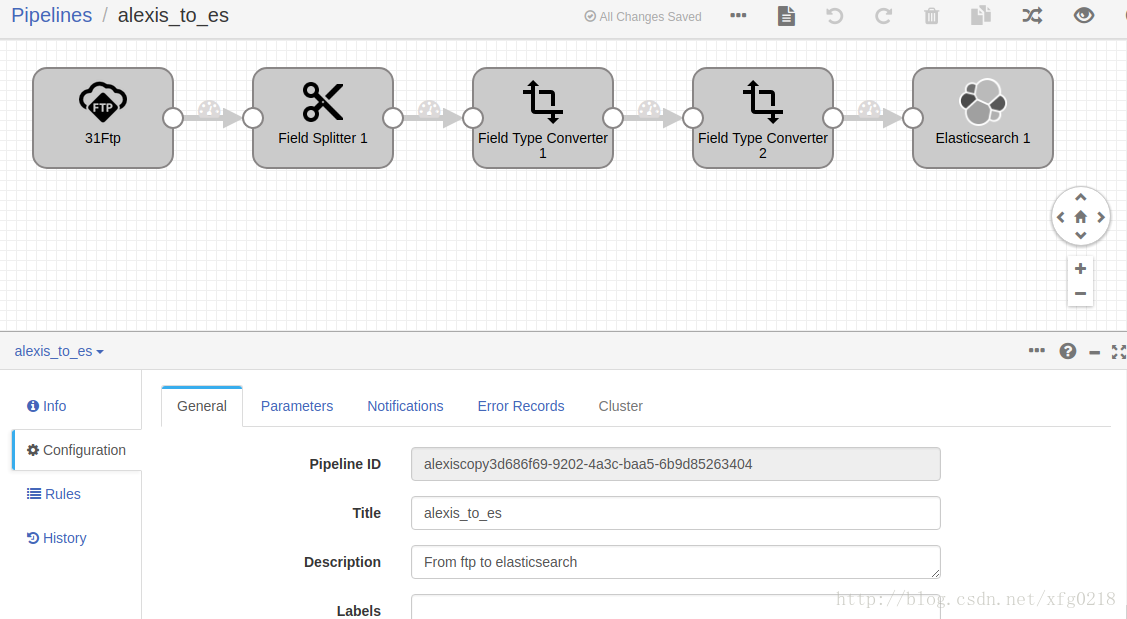
十三、使用streamsets3.0.1.0版本中的FTP作为数据源,经过对数据的分割类型的转换最后并把数据放到ES中
-
使用场景
本示例主要streamsets3.0.1.0版本中的FTP组件读取数据,经过对数据的分割与类型的转换并数据存放到es中,此任务开启后会一直运行,FTP组件会一直等待新的数据进入
-
示例下载
本示例请下载:alexis_to_es.json
-
示例展示
alexis_to_es.json

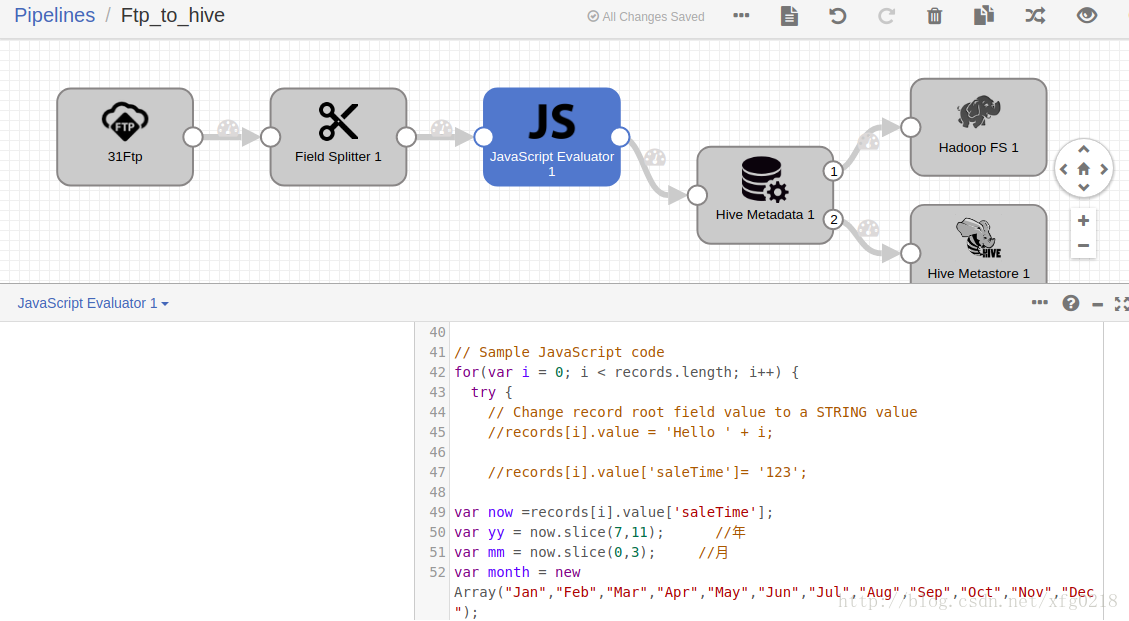
十四、streamsets3.0.1.0版本中JavaScript Evaluator组件的使用
-
使用场景
streamsets3.0.10版本中的JavaScript Evaluator组件对每一行的数据进行处理,使用次组件会减小任务的处理速度,此任务开启后任务会一直处于运行的状态
-
示例下载
本示例请下载:Ftp_to_hive.json
-
示例展示
Ftp_to_hive.json

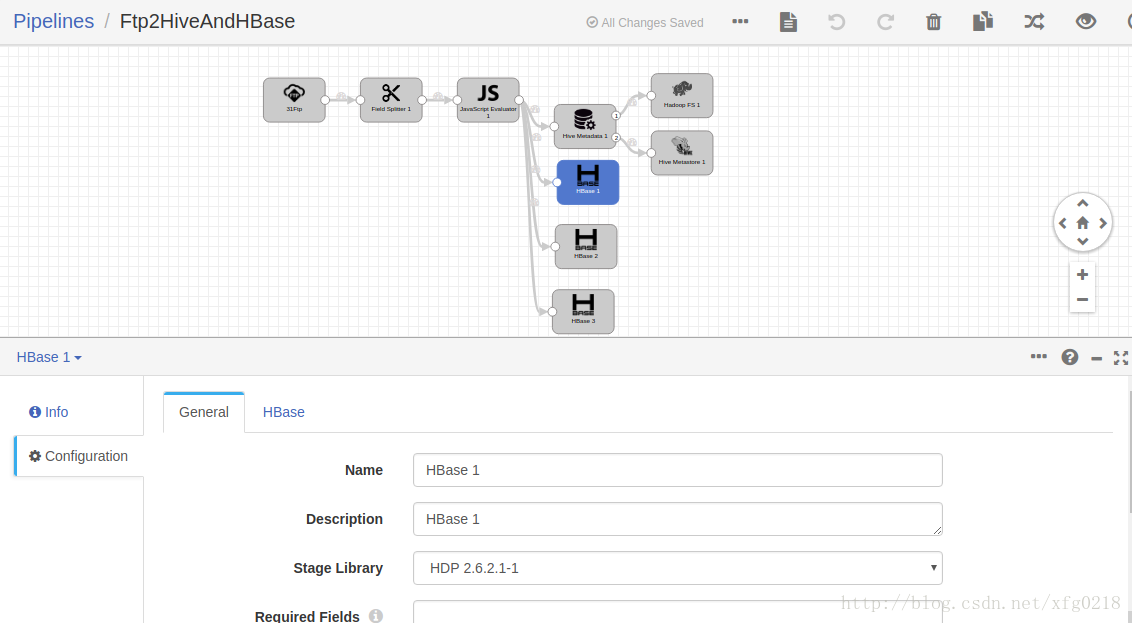
十五、使用streamsets3.0.1.0版本配置多个目标源
-
使用场景
如果把数据从FTP读出来,经过数据的处理后把数据既要放在Hive又放在Hbase中并且Hbase的表示多个,也就是说一个数据源对应多个目标源
-
示例下载
本示例请下载:Ftp2HiveAndHBase.json
-
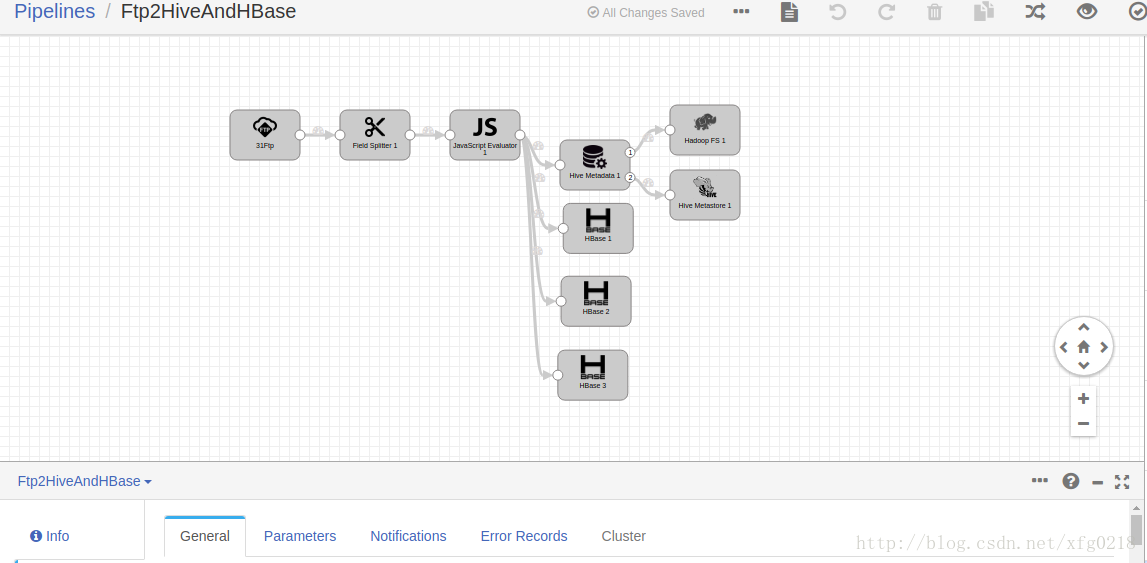
示例展示
Ftp2HiveAndHBase.json

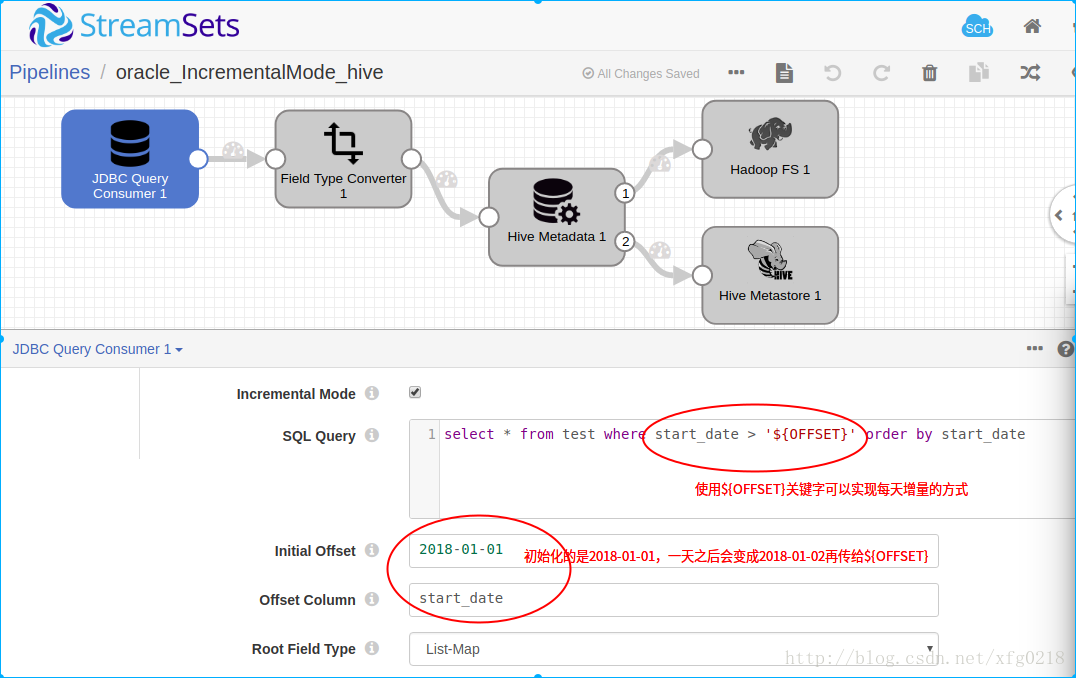
十六、使用streamsets2.6.0.1版本使用JDBC组件,读取oracle数据库中的数据实现增量的方式
-
使用场景
使用streamsets2.6.0.1版本中的JDBC组件,读取oracle数据库中的数据,实现每天自动增量到Hive中,
官网详细的介绍: https://streamsets.com/documentation/datacollector/latest/help/#Origins/JDBCConsumer.html 中搜索SQL Query for Incremental Mode关键字,
在JDBC单表消费者写SQL的方式,在SQL中使用${OFFSET}关键字来实现增量,${OFFSET}需要用单引号引入,Query Interval 设置成${24 * HOURS}即可,这样就实现了
每天增量获取oracle数据库中的增量数据
-
示例下载
本示例请下载:oracle_IncrementalMode_hive.json
-
示例展示
oracle_IncrementalMode_hive.json
















 1564
1564

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











