







文章目录
1、text()、string()、data()、点
参考文章源:https://blog.csdn.net/weixin_39285616/article/details/78463091
XML例子:
<book>
<author>Tom <em>John</em> cat</author>
<pricing>
<price>20</price>
<discount>0.8</discount>
</pricing>
</book>
| 使用举例 | 结果 |
|---|---|
| book/author/text() | Tom cat |
| book/author/string() | Tom John cat |
| book/pricing/data() | 返回分开的20和0.8 |
| book/author/. | Tom John cat |
text()是一个node test,而string()、data()是一个函数,data可以保留数据类型。此外,还有点号(.)表示当前节点。
2、python里lxml.etree._Element才能使用xpath
str类型的数据不能直接使用xpath,需要转换。
包括requests.get()、requests.Session().get()得到的数据都不能直接使用xpath。
scrapy框架里的response是可以直接使用xpath的。


3、输出文本(text、string)

在XPath 中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档节点(或称为根节点)。
xpath选取的元素节点不能直接输出为文本,输出文本可以有下面几种方式

xpath选取的元素节点,也可以通过etree.tostring()转成str

这里etree.tostring里面不加encoding = “utf-8”,输出的可能是HTML实体

html实体可以通过html.unescape转换

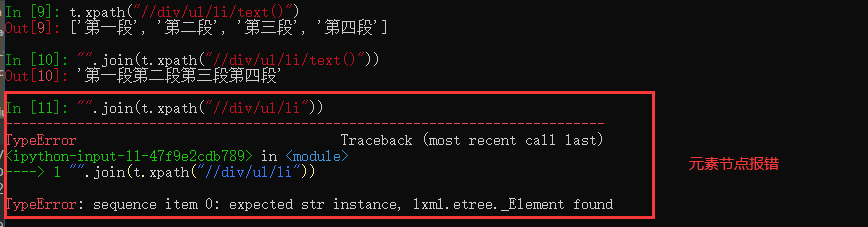
4、xpath输出的是列表类型
不管是元素节点还是文本节点都是列表类型


对于节点,必须先把列表序列化后再取文本,除了用切片,还可以用for in序列化


因为xpath输出的是列表类型,所以可以用join把它转为str(前提是文本节点、元素节点不行)
5、多个class值
div[@属性=“属性值”],获取div里该属性值的节点
例如:
<div class='a'>test</div>
div[@class="a"]
如果有多个class值,例如:
<div class='a b'>test</div>
div[contains(@class,"a")]
或者
div[contains(@class,"a") and contains(@class,"b")]
#它会取class同时有a和b的元素
6、scrapy框架中的get、extract
get() 、getall() 是新版本的方法,extract() 、extract_first()是旧版本的方法。
前者更好用,取不到就返回None,后者取不到就raise一个错误。
推荐使用新方法,官方文档中也都改用前者了。
总结:
对于scrapy.selector.unified.SelectorList对象
get() == extract_first()
返回的是一个list,里面包含了多个string
getall() == extract()
返回的是string,list里面第一个string
参考源:https://www.zhihu.com/question/63370553














 4233
4233











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









