







1、请问你是如何做接口测试的?
大体来说,经历以下过程:接口需求调研、接口测试工具选择、接口测试用例编写、接口测试执行、接口测试回归、接口测试自动化持续集成。具体来说,接口测试流程分成以下九步:
第一步:分析出测试需求,并请开发提供接口说明文档;
第二步:从接口说明文档中整理出接口测试用例,里面要包括详细的入参(正常情况,异常情况包括输入参数个数,类型,可选/必选,考虑参数有互斥或关联的情况)和出参数据(符合接口文档需求)以及明确的格式和检查点;
第三步:与开发一起对接口测试用例进行评审;
第四步:结合开发库,准备接口测试用例中的入参数据和出参数据,并整理成Excel格式的文件;
第五步:结合接口测试用例文档和Excel格式的数据文档,编写接口自动化测试的业务逻辑代码;
第六步:开始执行接口自动化测试用例;
第七步:执行如有bug,提交至缺陷管理平台;
第八步:开发修改完成后,回归bug,跟踪状态;
第九步:完成后进行自动化持续集成。
2、SpringBoot的自动装配讲一下吧!
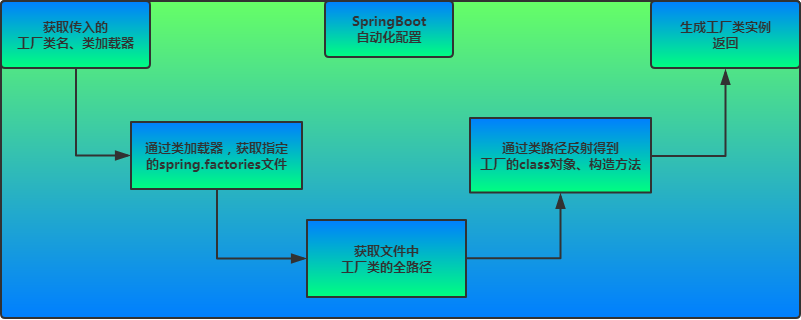
SpringBoot自动配置模块
该配置模块的主要使用到了SpringFactoriesLoader,即Spring工厂加载器,该对象提供了loadFactoryNames方法,入参为factoryClass和classLoader,即需要传入上图中的工厂类名称和对应的类加载器,方法会根据指定的classLoader,加载该类加器搜索路径下的指定文件,即spring.factories文件,传入的工厂类为接口,而文件中对应的类则是接口的实现类,或最终作为实现类,所以文件中一般为如下图这种一对多的类名集合,获取到这些实现类的类名后,loadFactoryNames方法返回类名集合,方法调用方得到这些集合后,再通过反射获取这些类的类对象、构造方法,最终生成实例。
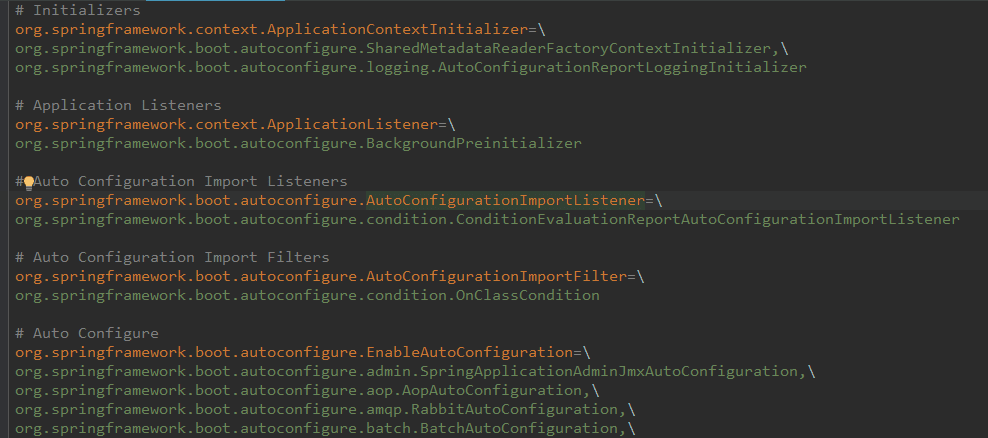
工厂接口与其若干实现类接口名称
下图有助于我们形象理解自动配置流程。

SpringBoot自动化配置关键组件关系图
mybatis-spring-boot-starter、spring-boot-starter-web等组件的META-INF文件下均含有spring.factories文件,自动配置模块中,SpringFactoriesLoader收集到文件中的类全名并返回一个类全名的数组,返回的类全名通过反射被实例化,就形成了具体的工厂实例,工厂实例来生成组件具体需要的bean。
之前我们提到了EnableAutoConfiguration注解,其类图如下:
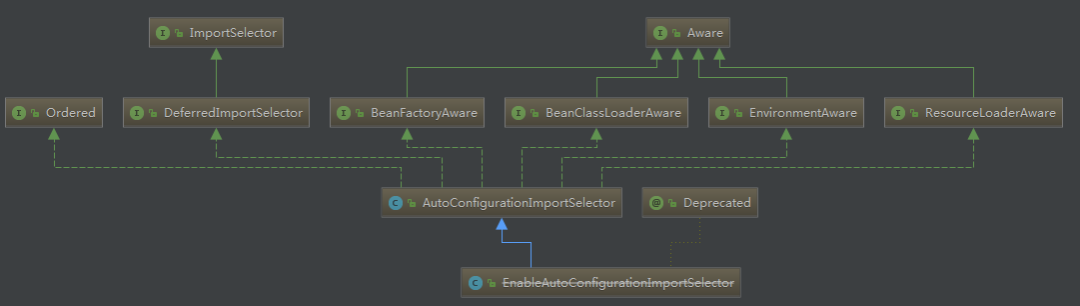
可以发现其最终实现了ImportSelector(选择器)和BeanClassLoaderAware(bean类加载器中间件),重点关注一下AutoConfigurationImportSelector的selectImports方法。
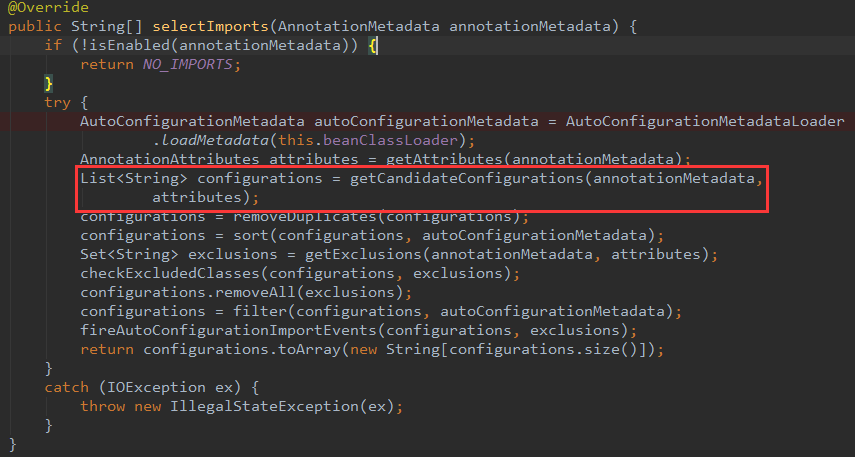
该方法在springboot启动流程——bean实例化前被执行,返回要实例化的类信息列表。我们知道,如果获取到类信息,spring自然可以通过类加载器将类加载到jvm中,现在我们已经通过spring-boot的starter依赖方式依赖了我们需要的组件,那么这些组建的类信息在select方法中也是可以被获取到的,不要急我们继续向下分析。
![]()
该方法中的getCandidateConfigurations方法,通过方法注释了解到,其返回一个自动配置类的类名列表,方法调用了loadFactoryNames方法,查看该方法。
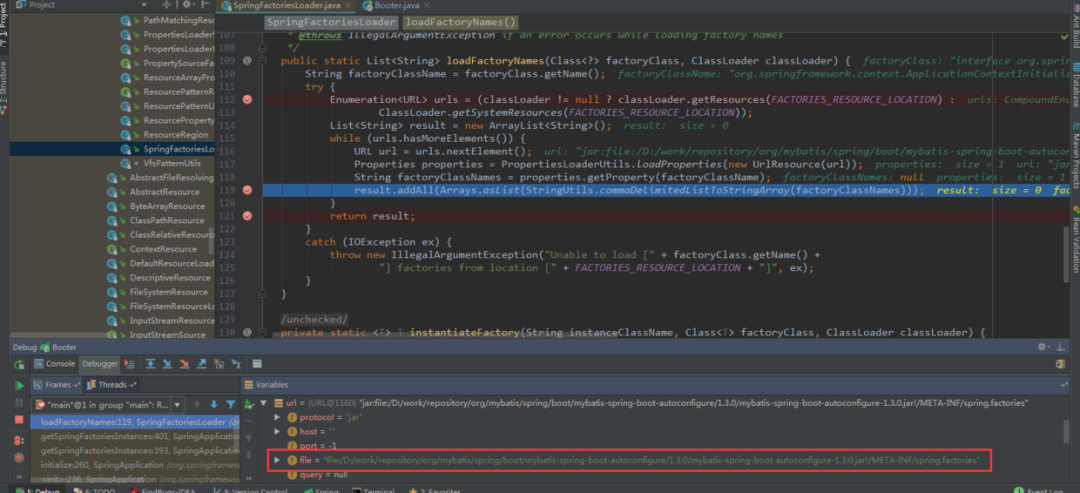
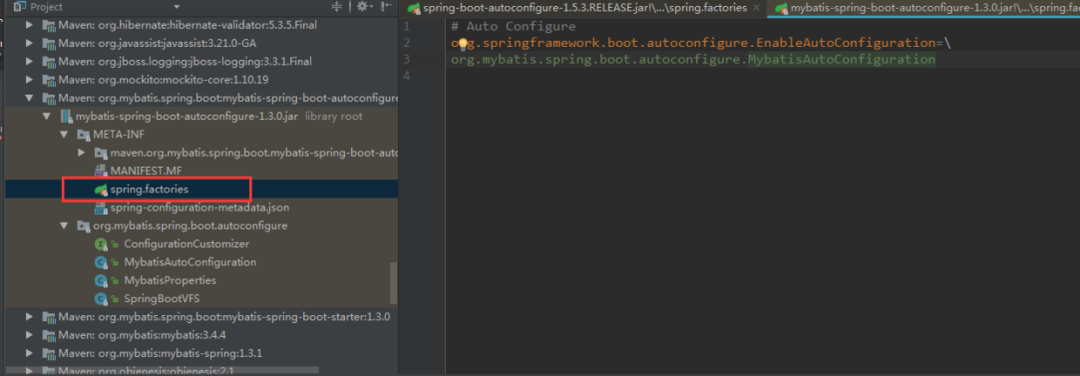
在上面的代码可以看到自动配置器会根据传入的factoryClass.getName()到项目系统路径下所有的spring.factories文件中找到相应的key,从而加载里面的类。我们就选取这个mybatis-spring-boot-autoconfigure下的spring.factories文件。
进入org.mybatis.spring.boot.autoconfigure.MybatisAutoConfiguration中,主要看一下类头:
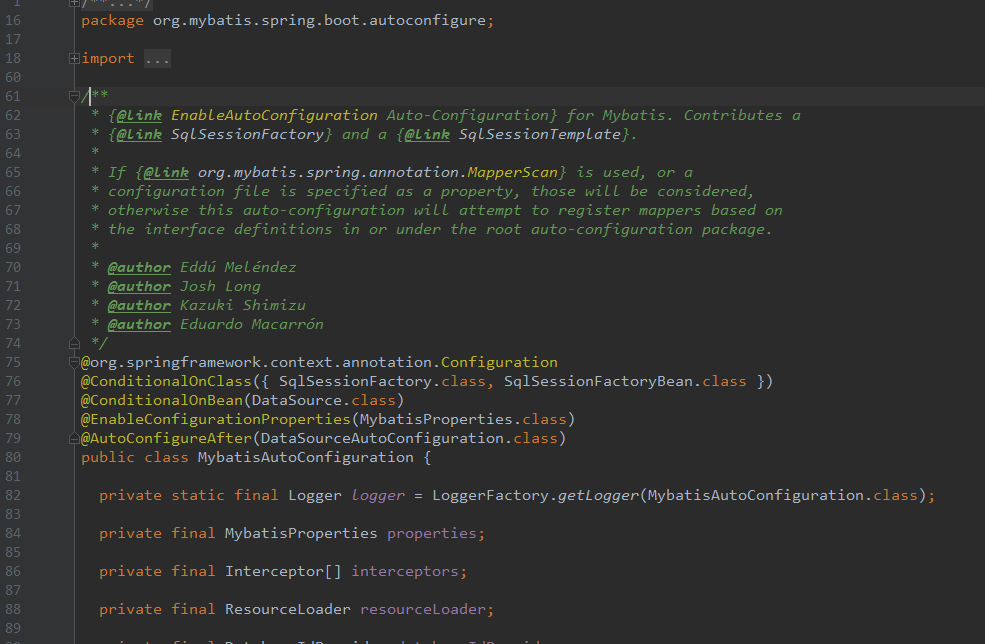
发现Spring的@Configuration,俨然是一个通过注解标注的springBean,继续向下看,
@ConditionalOnClass({ SqlSessionFactory.class, SqlSessionFactoryBean.class})这个注解的意思是:当存在SqlSessionFactory.class, SqlSessionFactoryBean.class这两个类时才解析MybatisAutoConfiguration配置类,否则不解析这一个配置类,make sence,我们需要mybatis为我们返回会话对象,就必须有会话工厂相关类。
@CondtionalOnBean(DataSource.class):只有处理已经被声明为bean的dataSource。
@ConditionalOnMissingBean(MapperFactoryBean.class)这个注解的意思是如果容器中不存在name指定的bean则创建bean注入,否则不执行(该类源码较长,篇幅限制不全粘贴)
以上配置可以保证sqlSessionFactory、sqlSessionTemplate、dataSource等mybatis所需的组件均可被自动配置,@Configuration注解已经提供了Spring的上下文环境,所以以上组件的配置方式与Spring启动时通过mybatis.xml文件进行配置起到一个效果。通过分析我们可以发现,只要一个基于SpringBoot项目的类路径下存在SqlSessionFactory.class, SqlSessionFactoryBean.class,并且容器中已经注册了dataSourceBean,就可以触发自动化配置,意思说我们只要在maven的项目中加入了mybatis所需要的若干依赖,就可以触发自动配置,但引入mybatis原生依赖的话,每集成一个功能都要去修改其自动化配置类,那就得不到开箱即用的效果了。所以Spring-boot为我们提供了统一的starter可以直接配置好相关的类,触发自动配置所需的依赖(mybatis)如下:

这里是截取的mybatis-spring-boot-starter的源码中pom.xml文件中所有依赖:
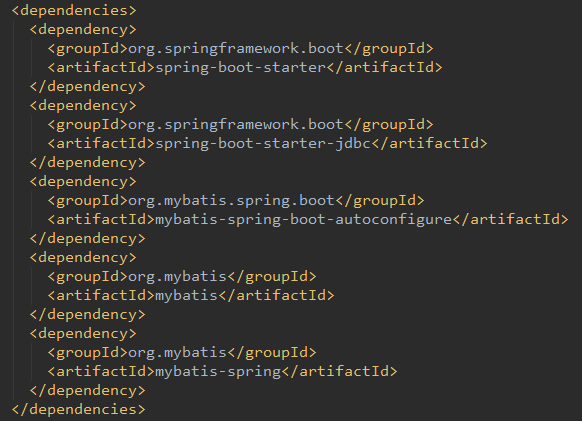
因为maven依赖的传递性,我们只要依赖starter就可以依赖到所有需要自动配置的类,实现开箱即用的功能。也体现出Springboot简化了Spring框架带来的大量XML配置以及复杂的依赖管理,让开发人员可以更加关注业务逻辑的开发。
3、spring循环依赖及解决方案。
1. 什么是循环依赖?
循环依赖其实就是循环引用,也就是两个或则两个以上的bean互相持有对方,最终形成闭环。比如A依赖于B,B依赖于C,C又依赖于A。如下图:
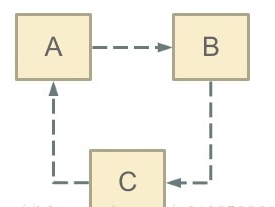
注意,这里不是函数的循环调用,是对象的相互依赖关系。循环调用其实就是一个死循环,除非有终结条件。
Spring中循环依赖场景有:
(1)构造器的循环依赖
(2)field属性的循环依赖。
2. 怎么检测是否存在循环依赖
检测循环依赖相对比较容易,Bean在创建的时候可以给该Bean打标,如果递归调用回来发现正在创建中的话,即说明了循环依赖了。
3. Spring怎么解决循环依赖
Spring的循环依赖的理论依据其实是基于Java的引用传递,当我们获取到对象的引用时,对象的field或则属性是可以延后设置的(但是构造器必须是在获取引用之前)。
Spring的单例对象的初始化主要分为三步:
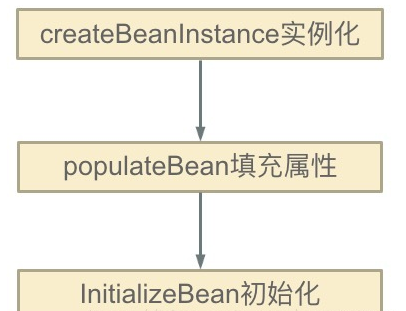
(1)createBeanInstance:实例化,其实也就是调用对象的构造方法实例化对象
(2)populateBean:填充属性,这一步主要是多bean的依赖属性进行填充
(3)initializeBean:调用spring xml中的init 方法。
从上面讲述的单例bean初始化步骤我们可以知道,循环依赖主要发生在第一、第二部。也就是构造器循环依赖和field循环依赖。
那么我们要解决循环引用也应该从初始化过程着手,对于单例来说,在Spring容器整个生命周期内,有且只有一个对象,所以很容易想到这个对象应该存在Cache中,Spring为了解决单例的循环依赖问题,使用了三级缓存。
首先我们看源码,三级缓存主要指:
/** Cache of singleton objects: bean name --> bean instance */private final Map<String, Object> singletonObjects = new ConcurrentHashMap<String, Object>(256);/** Cache of singleton factories: bean name --> ObjectFactory */private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<String, ObjectFactory<?>>(16);/** Cache of early singleton objects: bean name --> bean instance */private final Map<String, Object> earlySingletonObjects = new HashMap<String, Object>(16);
这三级缓存分别指:
singletonFactories :单例对象工厂的cache
earlySingletonObjects :提前暴光的单例对象的Cache
singletonObjects:单例对象的cache
我们在创建bean的时候,首先想到的是从cache中获取这个单例的bean,这个缓存就是singletonObjects。主要调用方法就就是:
protected Object getSingleton(String beanName, boolean allowEarlyReference) {Object singletonObject = this.singletonObjects.get(beanName);if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {synchronized (this.singletonObjects) {singletonObject = this.earlySingletonObjects.get(beanName);if (singletonObject == null && allowEarlyReference) {ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);if (singletonFactory != null) {singletonObject = singletonFactory.getObject();this.earlySingletonObjects.put(beanName, singletonObject);this.singletonFactories.remove(beanName);}}}}return (singletonObject != NULL_OBJECT ? singletonObject : null);}
上面的代码需要解释两个参数:
isSingletonCurrentlyInCreation()判断当前单例bean是否正在创建中,也就是没有初始化完成(比如A的构造器依赖了B对象所以得先去创建B对象, 或则在A的populateBean过程中依赖了B对象,得先去创建B对象,这时的A就是处于创建中的状态。)
allowEarlyReference 是否允许从singletonFactories中通过getObject拿到对象
分析getSingleton()的整个过程,Spring首先从一级缓存singletonObjects中获取。如果获取不到,并且对象正在创建中,就再从二级缓存earlySingletonObjects中获取。如果还是获取不到且允许singletonFactories通过getObject()获取,就从三级缓存singletonFactory.getObject()(三级缓存)获取,如果获取到了则:
this.earlySingletonObjects.put(beanName, singletonObject);this.singletonFactories.remove(beanName);
从singletonFactories中移除,并放入earlySingletonObjects中。其实也就是从三级缓存移动到了二级缓存。
从上面三级缓存的分析,我们可以知道,Spring解决循环依赖的诀窍就在于singletonFactories这个三级cache。这个cache的类型是ObjectFactory,定义如下:
public interface ObjectFactory<T> {T getObject() throws BeansException;}
这个接口在下面被引用
protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) {Assert.notNull(singletonFactory, "Singleton factory must not be null");synchronized (this.singletonObjects) {if (!this.singletonObjects.containsKey(beanName)) {this.singletonFactories.put(beanName, singletonFactory);this.earlySingletonObjects.remove(beanName);this.registeredSingletons.add(beanName);}}}
这里就是解决循环依赖的关键,这段代码发生在createBeanInstance之后,也就是说单例对象此时已经被创建出来(调用了构造器)。这个对象已经被生产出来了,虽然还不完美(还没有进行初始化的第二步和第三步),但是已经能被人认出来了(根据对象引用能定位到堆中的对象),所以Spring此时将这个对象提前曝光出来让大家认识,让大家使用。
这样做有什么好处呢?让我们来分析一下“A的某个field或者setter依赖了B的实例对象,同时B的某个field或者setter依赖了A的实例对象”这种循环依赖的情况。A首先完成了初始化的第一步,并且将自己提前曝光到singletonFactories中,此时进行初始化的第二步,发现自己依赖对象B,此时就尝试去get(B),发现B还没有被create,所以走create流程,B在初始化第一步的时候发现自己依赖了对象A,于是尝试get(A),尝试一级缓存singletonObjects(肯定没有,因为A还没初始化完全),尝试二级缓存earlySingletonObjects(也没有),尝试三级缓存singletonFactories,由于A通过ObjectFactory将自己提前曝光了,所以B能够通过ObjectFactory.getObject拿到A对象(虽然A还没有初始化完全,但是总比没有好呀),B拿到A对象后顺利完成了初始化阶段1、2、3,完全初始化之后将自己放入到一级缓存singletonObjects中。此时返回A中,A此时能拿到B的对象顺利完成自己的初始化阶段2、3,最终A也完成了初始化,进去了一级缓存singletonObjects中,而且更加幸运的是,由于B拿到了A的对象引用,所以B现在hold住的A对象完成了初始化。
知道了这个原理时候,肯定就知道为啥Spring不能解决“A的构造方法中依赖了B的实例对象,同时B的构造方法中依赖了A的实例对象”这类问题了!因为加入singletonFactories三级缓存的前提是执行了构造器,所以构造器的循环依赖没法解决。
4、redis分布式锁能讲一下吗?
场景:拼夕夕优惠券抢购活动
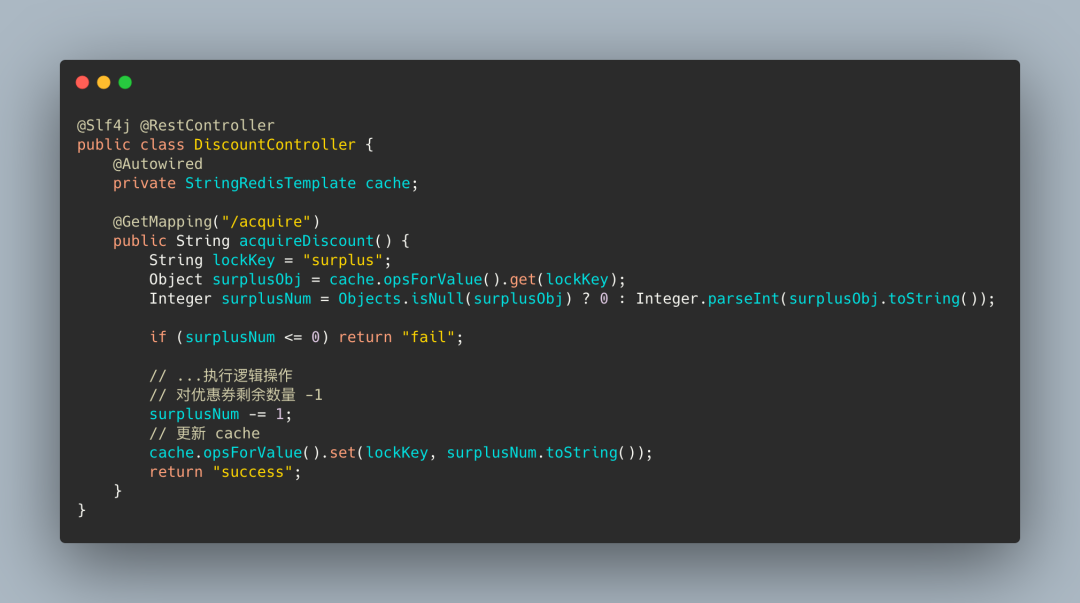
很明显的就是这段流程在并发场景下并不安全, 会导致优惠券发放超过预期, 类似电商抢购超卖问题。
想一哈有什么方式可以避免这种分布式下超量问题?
互斥加锁, Java 中互斥锁的语义就是 同一时间, 只允许一个客户端对资源进行操作
比如 Java 中的关键字 Synchronized, 以及 JUC Lock 包下的 ReentrantLock 都可以实现互斥锁
JVM 锁
如图所示, 加入 JVM synchronized 锁确实可以解决单机下并发问题
但是生产环境为了保证服务高可用, 起码要 部署两台服务, 这样的话 synchronized 就不起作用了, 因为它的 作用域只是单个 JVM
分布式情况下只能通过 分布式锁 来解决多个服务资源共享的问题了。
分布式锁
定义:保证同一时间只能有一个客户端对共享资源进行操作。
必须满足的要求:
1、不会发生死锁。即使有一个客户端在持有锁的期间崩溃而没有主动解锁,也能保证后续其他客户端能加锁;
2、具有容错性。只要大部分的Redis节点正常运行,客户端就可以加锁和解锁;
3、解铃还须系铃人。加锁和解锁必须是同一个客户端,客户端自己不能把别人加的锁给解了。
分布式锁实现大致分为三种, Redis、Zookeeper、数据库
分布式锁演进史
先来构思下分布式锁实现思路
首先我们必须保证同一时间只有一个客户端(部署的优惠券服务)操作数量加减
其次本次 客户端操作完成后, 需要让 其它客户端继续执行
1、客户端一存放一个标志位, 如果添加成功, 操作减优惠券数量操作
2、客户端二添加标志位失败, 本次减库存操作失败(或继续尝试获取等)
3、客户端一优惠券操作完成后, 需要将标志位释放, 以便其余客户端对库存进行操作
第一版 setnx
向 Redis 中添加一个 lockKey 锁标志位, 如果添加成功则能够继续向下执行扣减优惠券数量操作, 最后再释放此标志位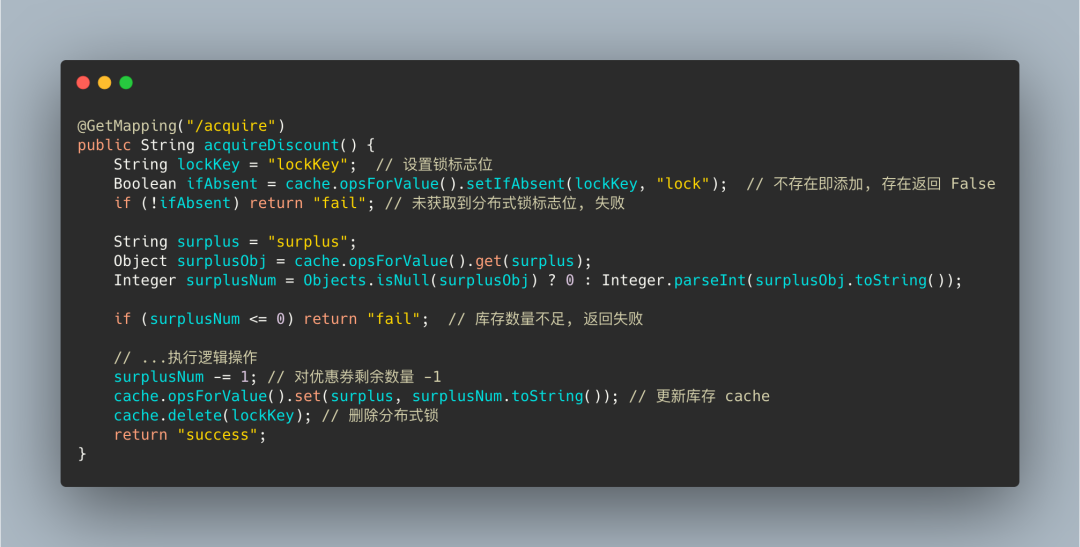
由于使用的是 Spring 提供的 Redis 封装的 Start 包, 所有有些命令与 Redis 原生命令不相符
setIfAbsent(key, val) -> setnx(key, val)加了简单的几行代码, 一个简单的分布式锁的雏形就出来了。
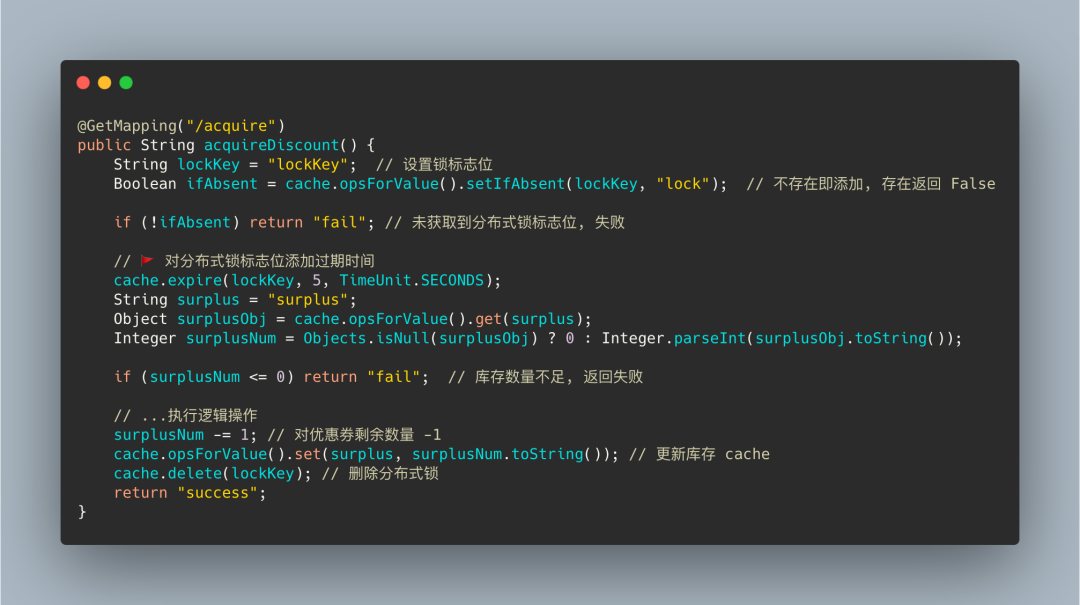
第二版 expire
上面第一版基于 setnx 命令实现分布式锁的缺陷也是很明显的, 那就是 一定情况下可能发生死锁
画个图, 举个例子说明哈
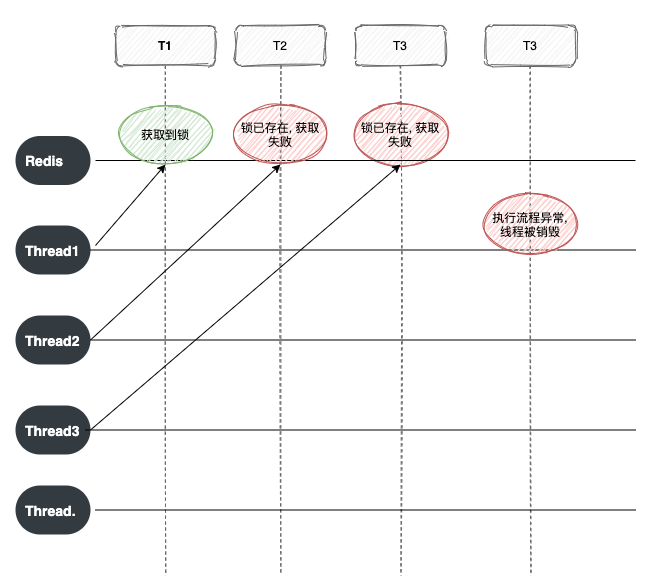
上图说明, 线程1在成功获取锁后, 执行流程时异常结束, 没有执行释放锁操作, 这样就会 产生死锁。
如果方法执行异常导致的线程被回收, 那么可以将解锁操作放到 finally 块中
但是还有存在死锁问题, 如果获得锁的线程在执行中, 服务被强制停止或服务器宕机, 锁依然不会得到释放
这种极端情况下我们还是要考虑的, 毕竟不能只想着服务没问题对吧
对 Redis 的 锁标志位加上过期时间 就能很好的防止死锁问题, 继续更改下程序代码
虽然 小红旗处 对分布式锁添加了过期时间, 但依然无法避免极端情况下的死锁问题
那就是如果在客户端加锁成功后, 还没有设置过期时间时宕机
如果想要避免添加锁时死锁, 那就对添加锁标志位 & 添加过期时间命令 保证一个原子性, 要么一起成功, 要么一起失败
第三版 set
我们的添加锁原子命令就要登场了, 从 Redis 2.6.12 版本起, 提供了可选的 字符串 set 复合命令
SET key value [expiration EX seconds|PX milliseconds] [NX|XX]可选参数如下:
-
EX: 设置超时时间,单位是秒
-
PX: 设置超时时间,单位是毫秒
-
NX: IF NOT EXIST 的缩写,只有 KEY不存在的前提下 才会设置值
-
XX: IF EXIST 的缩写,只有在 KEY存在的前提下 才会设置值
继续完善分布式锁的应用程序, 代码如下:
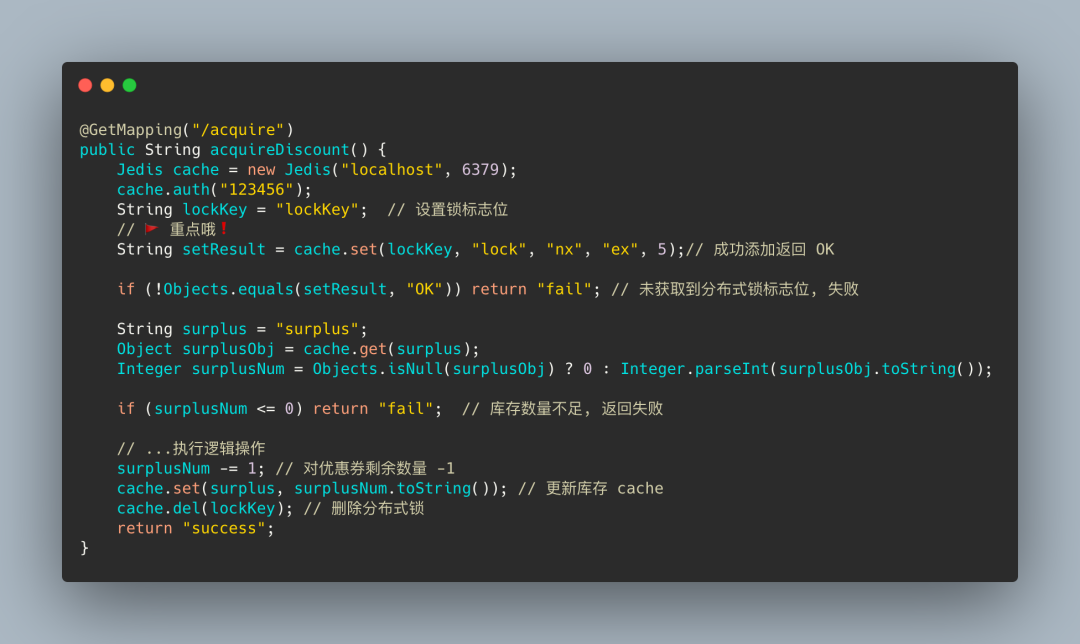
我使用的 2.0.9.RELEASE 版本的 SpringBoot, RedisTemplate 中不支持 set 复合命令, 所以临时换个 Jedis 来实现
加锁以及设置过期时间确实保证了原子性, 但是这样的分布式锁就没有问题了么?
我们根据图片以及流程描述设想一下这个场景
1、线程一获取锁成功, 设置过期时间五秒, 接着执行业务逻辑
2、接着线程一获取锁后执行业务流程, 执行的时间超过了过期时间, 锁标志位过期进行释放, 此时线程二获取锁成功
3、然鹅此时线程一执行完业务后, 开始执行释放锁的流程, 然后顺手就把线程二获取的锁释放了
如果线上真的发生上述问题, 那真的是xxx, 更甚者可能存在线程一将线程二的锁释放掉之后, 线程三获取到锁, 然后线程二执行完将线程三的锁释放
第四版 verify value
事当如今, 只能创建辨别客户端身份的唯一值了, 将加锁及解锁归一化, 上代码~
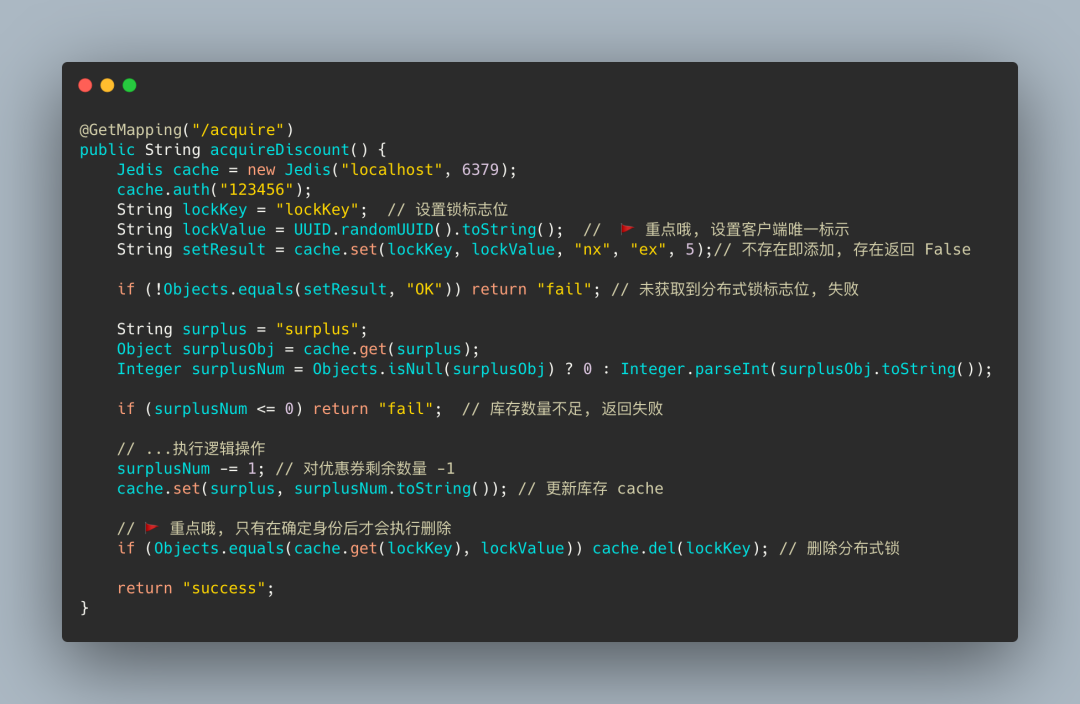
这一版的代码相当于我们添加锁标志位时, 同时为每个客户端设置了 uuid 作为锁标志位的 val, 解锁时需要判断锁的 val 是否和自己客户端的相同, 辨别成功才会释放锁
但是上述代码执行业务逻辑如果抛出异常, 锁只能等待过期时间, 我们可以将解锁操作放到 finally 块
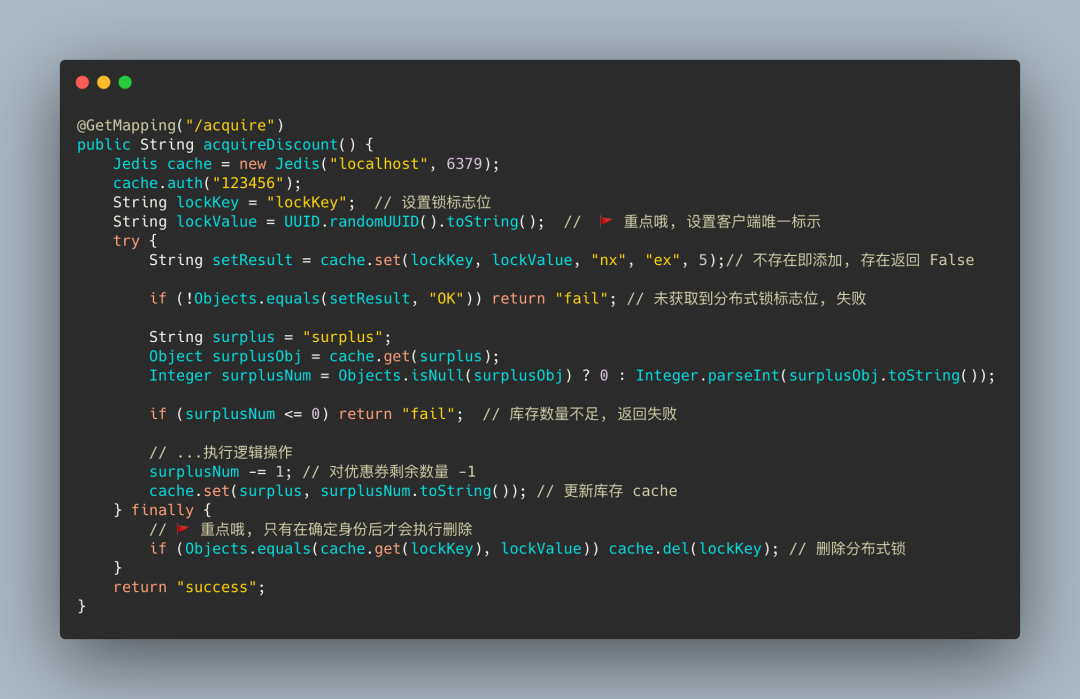
大眼一看, 上上下下实现了四版分布式锁, 也该没问题了吧
真相就是: 解锁时, 由于判断锁和删除标志位并不是原子性的, 所以可能还是会存在误删
1、线程一获取锁后, 执行流程balabala… 判断锁也是自家的, 这时 CPU 转头去做别的事情了, 恰巧线程一的锁过期时间到了
2、线程二此时顺理成章的获取到了分布式锁, 执行业务逻辑balabala…
3、线程一再次分配到时间片继续执行删除操作
解决这种非原子操作的方式只能 将判断元素值和删除标志位当作一个原子操作
第五版 lua
很不友好的是, del 删除操作并没有提供原子命令, 所以我们需要想点办法
Redis在 2.6 推出了脚本功能, 允许开发者使用 Lua 语言编写脚本传到 Redis 中执行
使用 Lua 脚本有什么好处呢?
1、减少网络开销
原本我们需要向 Redis 服务请求多次命令, 可以将命令写在 Lua 脚本中, 这样执行只会发起一次网络请求
2、原子操作
Redis 会将 Lua 脚本中的命令当作一个整体执行, 中间不会插入其它命令
3、复用(大家自己探索哈)
客户端发送的脚步会存储 Redis 中, 其他客户端可以复用这一脚本而不需要使用代码完成相同的逻辑
那我们编写一个简单的 Lua 脚本实现原子删除操作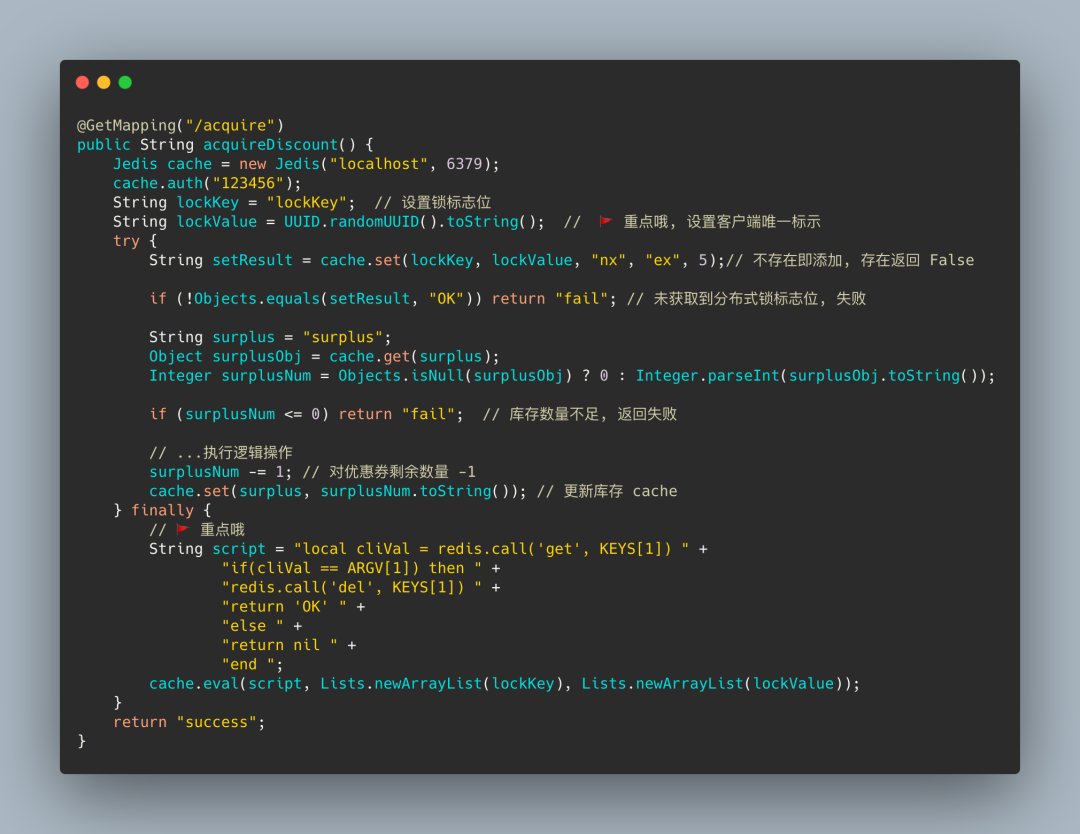
重点就在 Lua 脚本这一块, 重点说一下这块的逻辑
script 脚本就是我们在 Redis 中执行的 Lua 脚本, 后面跟的两个 List 分别是 KEYS、ARGV
cache.eval(script, Lists.newArrayList(lockKey), Lists.newArrayList(lockValue));KEYS[1]: lockKey
ARGV[1]: lockValue
代码不是很多, 也比较简单, 就是在 Java 中代码实现的逻辑放到了一个 Lua 脚本中
# 获取 KEYS[1] 对应的 Vallocal cliVal = redis.call('get', KEYS[1])# 判断 KEYS[1] 与 ARGV[1] 是否保持一致if(cliVal == ARGV[1]) then# 删除 KEYS[1]redis.call('del', KEYS[1])return 'OK'elsereturn nilend
到了这种程度, 已经可以放到一些并发量不大的项目中生产使用了
TODO 列表
虽然上述代码已经很大程度上解决了分布式锁可能存在的一些问题
但是下述列出的问题部分就不是客户端代码范畴内的事情了
1、如何实现可重入锁
2、如何解决代码执行锁超时
3、主从节点同步数据丢失导致锁丢失问题
Redis 官方推荐的客户端: Redisson
Jedis… 等客户端平常使用是绰绰有余的, 但是在功能上还是和 Redisoon 比不了
并不是推荐一定要用 Redisson, 根据不同场景选用不同客户端
Redisson 就是为分布式提供 各种不同锁以及多样化的技术支持, 感兴趣的小伙伴可以看一下 Giuhub 上的介绍, 挺详细的
看了 Redisson 的源码后简直了… 然后对之前项目的分布式锁做了重构, 在原有基础上增加了如下功能
保证了加锁、解锁之间的原子性
可重入的分布式锁
分布式锁自动延期功能
今天的问题内容上比较多,咱就不列举那么多问题了,大家可以好好看一下。














 1069
1069











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









