







高阶函数
map/reduce
map()函数接收两个参数,一个是函数,一个是Iterable,map将传入的函数依次作用到序列的每个元素,并把结果作为新的Iterator返回。
举例说明,比如我们有一个函数
f
(
x
)
=
x
2
f(x)=x^2
f(x)=x2,要把这个函数作用在一个list [1, 2, 3, 4, 5, 6, 7, 8, 9]上,就可以用map()实现如下:
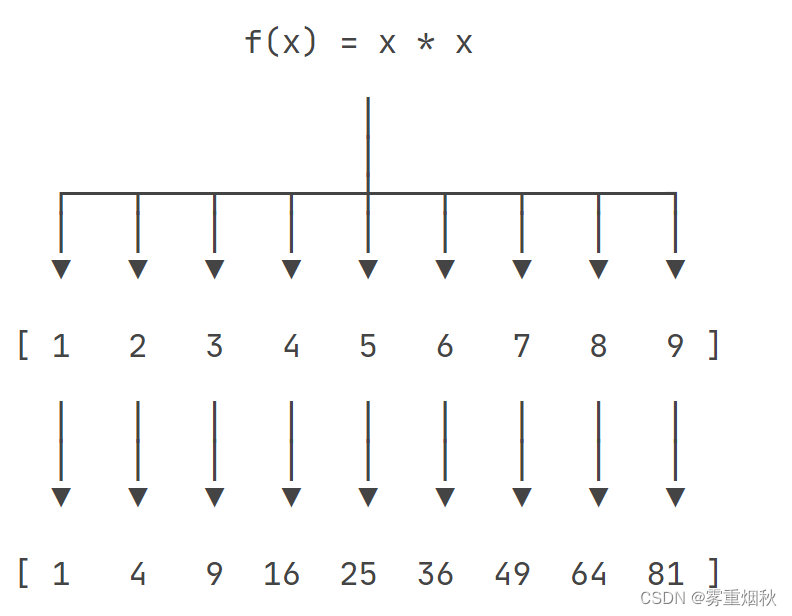
用Python代码实现:
>>> def f(x):
... return x * x
...
>>> r = map(f, [1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> list(r)
[1, 4, 9, 16, 25, 36, 49, 64, 81]
map()传入的第一个参数是f,即函数对象本身。由于结果r是一个Iterator,Iterator是惰性序列,因此通过list()函数把它整个序列都计算出来并返回一个list。
如果不用map()函数,就是写一个循环,计算出结果:
L = []
for n in [1, 2, 3, 4, 5, 6, 7, 8, 9]:
L.append(f(n))
print(L)
从上面的循环代码,不能一眼就看明白“把 f ( x ) f(x) f(x)作用在list的每一个元素并把结果生成一个新的list”,所以,`map()作为高阶函数,事实上它把运算规则抽象了,因此,我们不但可以计算简单的 f ( x ) = x 2 f(x)=x^2 f(x)=x2,还可以计算任意复杂的函数,比如,把这个list所有数字转为字符串:
>>> list(map(str, [1, 2, 3, 4, 5]))
['1', '2', '3', '4', '5']
再看reduce的用法。reduce把一个函数作用在一个序列[x1, x2, x3, ...]上,这个函数必须接收两个参数,reduce把结果继续和序列的下一个元素做累积计算,其效果就是:
reduce(f, [x1, x2, x3, x4]) = f(f(f(x1, x2), x3), x4)
比方说对一个序列求和,就可以用reduce实现:
>>> from functools import reduce
>>> def add(x, y):
... return x + y
...
>>> reduce(add, [1, 3, 5, 7, 9])
25
当然求和运算可以直接用Python内建函数sum(),没必要动用reduce。
但是如果要把序列[1, 3, 5, 7, 9]变换成整数13579,reduce就可以派上用场:
>>> from functools import reduce
>>> def fn(x, y):
... return x * 10 + y
...
>>> reduce(fn, [1, 3, 5, 7, 9])
13579
这个例子本身没多大用处,但是,如果考虑到字符串str也是一个序列,对上面的例子稍加改动,配合map(),我们就可以写出把str转换为int的函数:
>>> from functools import reduce
>>> def fn(x, y):
... return x * 10 + y
...
>>> def char2num(s):
... digits = {'0': 0, '1': 1, '2': 2, '3': 3, '4': 4, '5': 5, '6': 6, '7': 7, '8': 8, '9': 9}
... return digits[s]
...
>>> reduce(fn, map(char2num, '13579'))
13579
整理成一个str2int的函数就是:
from functools import reduce
DIGITS = {'0': 0, '1': 1, '2': 2, '3': 3, '4': 4, '5': 5, '6': 6, '7': 7, '8': 8, '9': 9}
def str2int(s):
def fn(x, y):
return x * 10 + y
def char2num(s):
return DIGITS[s]
return reduce(fn, map(char2num, s))
还可以用lambda函数进一步简化成:
from functools import reduce
DIGITS = {'0': 0, '1': 1, '2': 2, '3': 3, '4': 4, '5': 5, '6': 6, '7': 7, '8': 8, '9': 9}
def char2num(s):
return DIGITS[s]
def str2int(s):
return reduce(lambda x, y: x * 10 + y, map(char2num, s))
也就是说,假设Python没有提供int()函数,你完全可以自己写一个把字符串转化为整数的函数,而且只需要几行代码!
lambda函数的用法在后面介绍。
- 练习
利用map()函数,把用户输入的不规范的英文名字,变为首字母大写,其他小写的规范名字。输入:['adam', 'LISA', 'barT'],输出:['Adam', 'Lisa', 'Bart']:
from functools import reduce
def normalize(name):
return name.capitalize()
# 测试:
L1 = ['adam', 'LISA', 'barT']
L2 = list(map(normalize, L1))
print(L2)
Python提供的sum()函数可以接受一个list并求和,请编写一个prod()函数,可以接受一个list并利用reduce()求积:
from functools import reduce
def prod(L):
return reduce(lambda x, y : x * y, L)
# 测试:
print('3 * 5 * 7 * 9 =', prod([3, 5, 7, 9]))
if prod([3, 5, 7, 9]) == 945:
print('测试成功!')
else:
print('测试失败!')
利用map和reduce编写一个str2float函数,把字符串'123.456'转换成浮点数123.456:
from functools import reduce
DIGITS = {'0': 0, '1': 1, '2': 2, '3': 3, '4': 4, '5': 5, '6': 6, '7': 7, '8': 8, '9': 9}
def str2float(s):
s1, s2 = s.split('.')
flag = True
def Fn(x, y):
return x * 10 + y
def char2num(s):
return DIGITS[s]
return reduce(Fn, map(char2num, s1)) + reduce(Fn, map(char2num, s2)) / (10 ** len(s2))
# 测试:
print('str2float(\'123.456\') =', str2float('123.456'))
if abs(str2float('123.456') - 123.456) < 0.00001:
print('测试成功!')
else:
print('测试失败!')
str2float('123.456') = 123.456
测试成功!
filter
Python内建的filter()函数用于过滤序列。
和map()类似,filter()也接收一个函数和一个序列。和map()不同的是,filter()把传入的函数依次作用于每个元素,然后根据返回值是True还是False决定保留还是丢弃该元素。
例如,在一个list中,删掉偶数,只保留奇数,可以这么写:
def is_odd(n):
return n % 2 == 1
list(filter(is_odd, [1, 2, 4, 5, 6, 9, 10, 15]))
# 结果: [1, 5, 9, 15]
把一个序列中的空字符串删掉,可以这么写:
def not_empty(s):
return s and s.strip()
list(filter(not_empty, ['A', '', 'B', None, 'C', ' ']))
# 结果: ['A', 'B', 'C']
这里利用了短路特性,return s and s.strip(),如果s是空的,就是s是False,那么and操作符在第一个操作数为False时就足以确定整个表达式的结果将是False了,而且,如果s是None,直接调用s.strip()将会引发AttributeError。
可见用filter()这个高阶函数,关键在于正确实现一个“筛选”函数。
注意到filter()函数返回的是一个Iterator,也就是一个惰性序列,所以要强迫filter()完成计算结果,需要用list()函数获得所有结果并返回list。
用filter求素数

用Python来实现这个算法,可以先构造一个从3开始的奇数序列:
def _odd_iter():
n = 1
while True:
n = n + 2
yield n
注意这是一个生成器,并且是一个无限序列。
然后定义一个筛选函数:
def _not_divisible(n):
return lambda x: x % n > 0
这里的这个筛选函数是返回一个lambda函数,这个lambda函数接收一个x,然后判断x % n > 0,如果是返回True,否则返回False,为了filter定义的
最后,定义一个生成器,不断返回下一个素数:
def primes():
yield 2
it = _odd_iter() # 初始序列
while True:
n = next(it) # 返回序列的第一个数
yield n
it = filter(_not_divisible(n), it) # 构造新序列
这个生成器先返回第一个素数2,然后,利用filter()不断产生筛选后的新的序列。
由于primes()也是一个无限序列,所以调用时需要设置一个退出循环的条件:
# 打印1000以内的素数:
for n in primes():
if n < 1000:
print(n)
else:
break
注意到Iterator是惰性计算的序列,所以我们可以用Python表示“全体自然数”,“全体素数”这样的序列,而代码非常简洁。
- 练习
回数是指从左向右读和从右向左读都是一样的数,例如12321,909。请利用filter()筛选出回数:
# -*- coding: utf-8 -*-
# 直接判断是否和反转字符串相等
def is_palindrome(n):
str_n = str(n)
return str_n == str_n[::-1]
# 测试:
output = filter(is_palindrome, range(1, 1000))
print('1~1000:', list(output))
if list(filter(is_palindrome, range(1, 200))) == [1, 2, 3, 4, 5, 6, 7, 8, 9, 11, 22, 33, 44, 55, 66, 77, 88, 99, 101, 111, 121, 131, 141, 151, 161, 171, 181, 191]:
print('测试成功!')
else:
print('测试失败!')
sorted
排序算法:排序也是在程序中经常用到的算法。无论使用冒泡排序还是快速排序,排序的核心是比较两个元素的大小。如果是数字,我们可以直接比较,但如果是字符串或者两个dict呢?直接比较数学上的大小是没有意义的,因此,比较的过程必须通过函数抽象出来。
Python内置的sorted()函数就可以对list进行排序:
>>> sorted([36, 5, -12, 9, -21])
[-21, -12, 5, 9, 36]
此外,sorted()函数也是一个高阶函数,它还可以接收一个key函数来实现自定义的排序,例如按绝对值大小排序:
>>> sorted([36, 5, -12, 9, -21], key=abs)
[5, 9, -12, -21, 36]
key指定的函数将作用于list的每一个元素上,并根据key函数返回的结果进行排序。
我们再看一个字符串排序的例子:
>>> sorted(['bob', 'about', 'Zoo', 'Credit'])
['Credit', 'Zoo', 'about', 'bob']
默认情况下,对字符串排序,是按照ASCII的大小比较的,由于'Z' < 'a',结果,大写字母Z会排在小写字母a的前面。
现在,我们提出排序应该忽略大小写,按照字母序排序。要实现这个算法,不必对现有代码大加改动,只要我们能用一个key函数把字符串映射为忽略大小写排序即可。忽略大小写来比较两个字符串,实际上就是先把字符串都变成大写(或者都变成小写),再比较。
这样,我们给sorted传入key函数,即可实现忽略大小写的排序:
>>> sorted(['bob', 'about', 'Zoo', 'Credit'], key=str.lower)
['about', 'bob', 'Credit', 'Zoo']
要进行反向排序,不必改动key函数,可以传入第三个参数reverse=True:
>>> sorted(['bob', 'about', 'Zoo', 'Credit'], key=str.lower, reverse=True)
['Zoo', 'Credit', 'bob', 'about']
从上述例子可以看出,高阶函数的抽象能力是非常强大的,而且,核心代码可以保持得非常简洁。
相当于,在sorted()函数中,如果提供了一个key函数,sorted()先对序列中的每个元素进行了一次隐式的映射,有点像显式调用了map()然后再排序,隐式的内部优化了排序过程,比显示调用map()再进行排序快。
- 练习
设我们用一组tuple表示学生名字和成绩:
L = [('Bob', 75), ('Adam', 92), ('Bart', 66), ('Lisa', 88)]
请用sorted()对上述列表分别按名字排序:
# -*- coding: utf-8 -*-
L = [('Bob', 75), ('Adam', 92), ('Bart', 66), ('Lisa', 88)]
def by_name(t):
return t[0]
L2 = sorted(L, key=by_name)
print(L2)
再按成绩从高到低排序:
# -*- coding: utf-8 -*-
L = [('Bob', 75), ('Adam', 92), ('Bart', 66), ('Lisa', 88)]
def by_name(t):
return t[1]
L2 = sorted(L, key=by_name, reverse=True)
print(L2)















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









