







本文讨论的内容参考自《神经网络与深度学习》https://nndl.github.io/ 第3章 线性模型
线性模型
线性模型(Linear Model)是机器学习中应用最广泛的模型,指通过样本特征的线性组合来进行预测的模型,给定一个 D D D维样本 x = [ x 1 , . . . , x D ] T \bm x = [x_1,...,x_D]^T x=[x1,...,xD]T,其线性组合函数为

在分类问题中,由于输出目标 y y y是一些离散的标签,而 f ( x ; ω ) f(\bm x;\bm \omega) f(x;ω)的值域为实数,因此无法直接用 f ( x ; ω ) f(\bm x;\bm \omega) f(x;ω)来进行预测,需要引入一个非线性的决策函数 g ( ⋅ ) g(\cdot) g(⋅)来预测输出目标


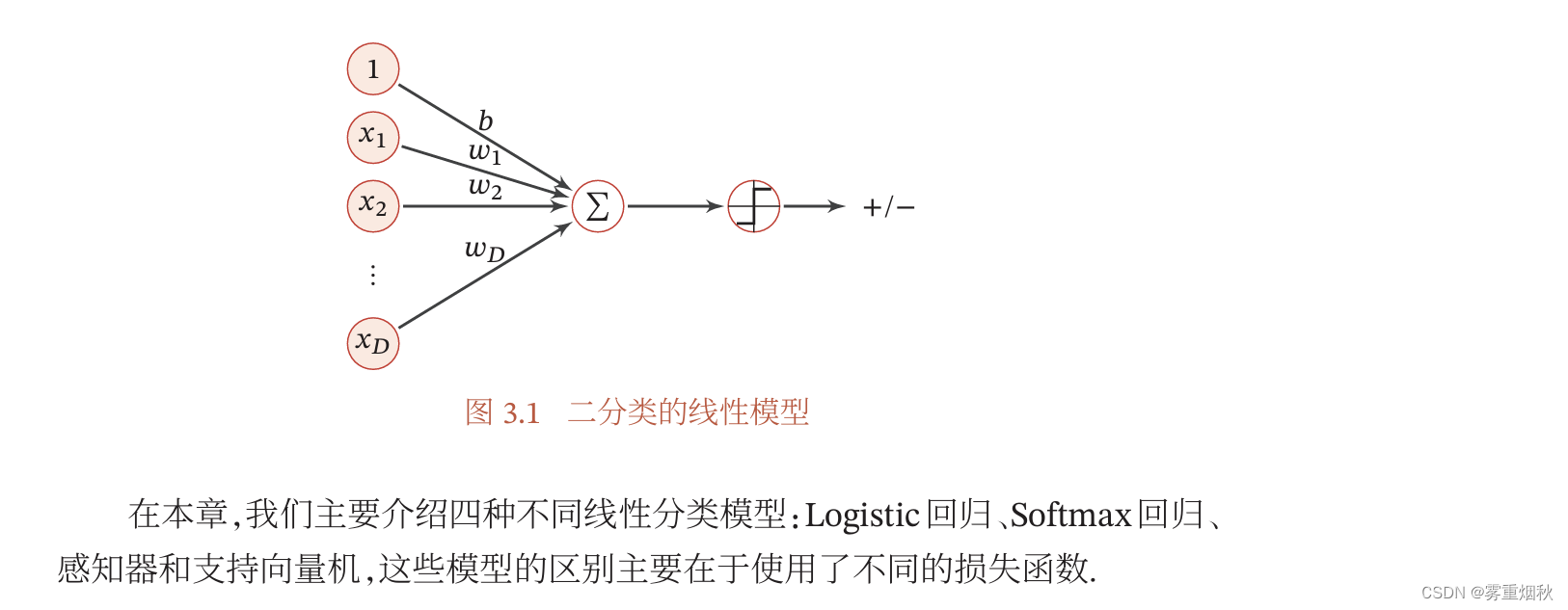
线性判别函数和决策边界
从公式(3.3)可知,一个线性分类模型或线性分类器,是由一个或多个线性的判别函数 f ( x ; ω ) = ω T x + b f(\bm x;\bm \omega)=\bm \omega^T x+b f(x;ω)=ωTx+b和非线性的决策函数 g ( ⋅ ) g(\cdot) g(⋅)组成,我们首先考虑二分类的情况,然后再扩展到多分类的情况。
二分类
二分类问题的类别标签 y y y只有两种取值,通常可以设为 + 1 , − 1 {+1,-1} +1,−1或 0 , 1 {0,1} 0,1。在二分类问题中,常用正例和负例来分别表示属于类别+1和-1的样本。
在二分类问题中,我们只需要一个线性判别函数 f ( x ; ω ) = ω T x + b f(\bm x;\bm \omega)=\bm \omega^T x+b f(x;ω)=ωTx+b。特征空间 R D R^D RD中所有满足 f ( x ; ω ) = 0 f(\bm x; \bm \omega)=0 f(x;ω)=0的点组成一个分割超平面,称为决策边界或决策平面。决策边界将特征空间一分为二,划分成两个区域,每个区域对应一个类别。
所谓“线性分类模型”就是指其决策边界是线性超平面。在特征空间中,决策平面与权重向量 ω \bm \omega ω正交,特征空间中每个样本点到决策平面的有向距离为
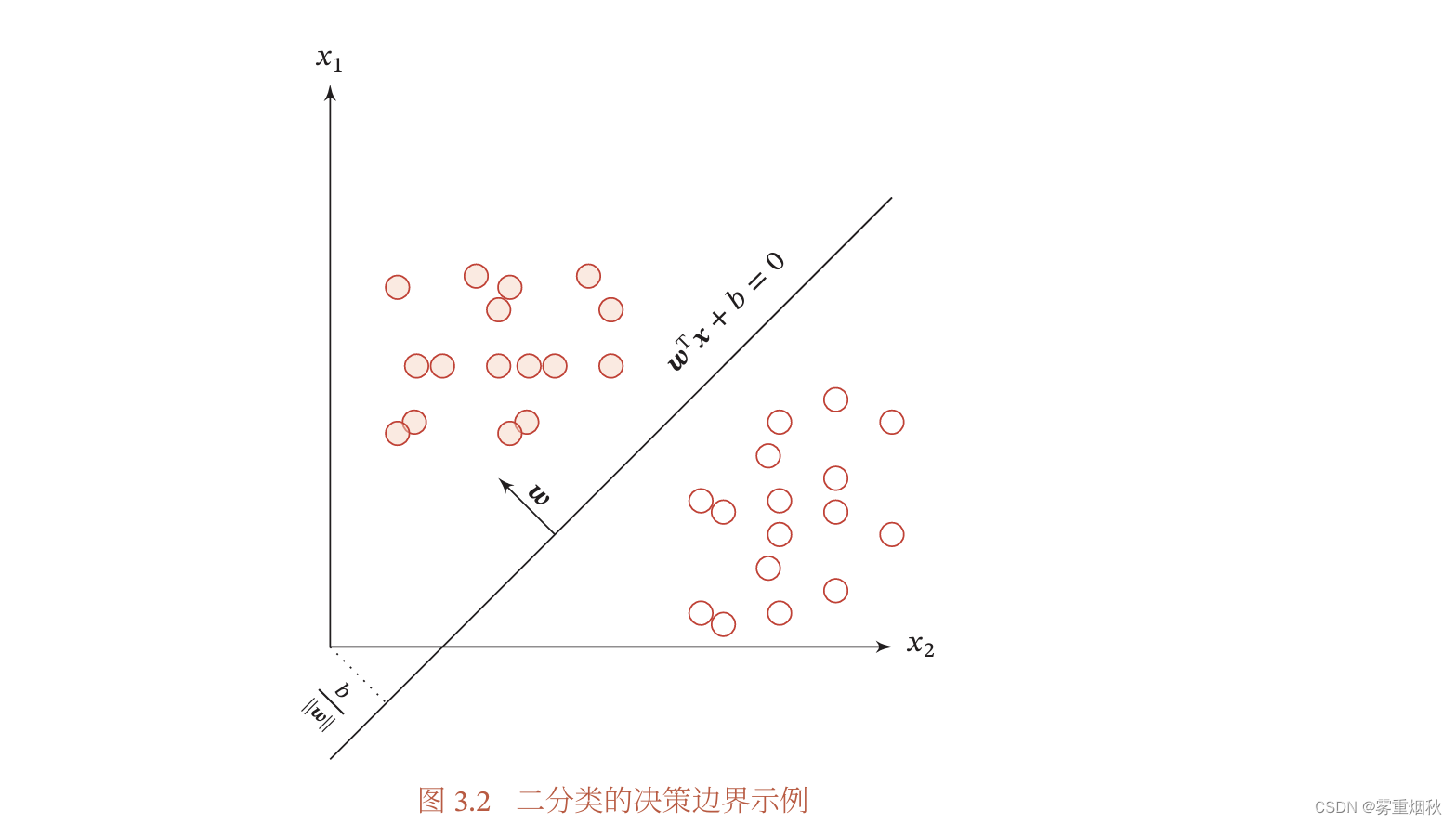
图3.2给出了一个二分类问题的线性决策边界示例,其中样本特征向量 x = [ x 1 , x 2 ] \bm x=[x1,x2] x=[x1,x2],权重向量 ω = [ ω 1 , ω 2 ] \bm \omega=[\omega 1,\omega 2] ω=[ω1,ω2]。


多分类

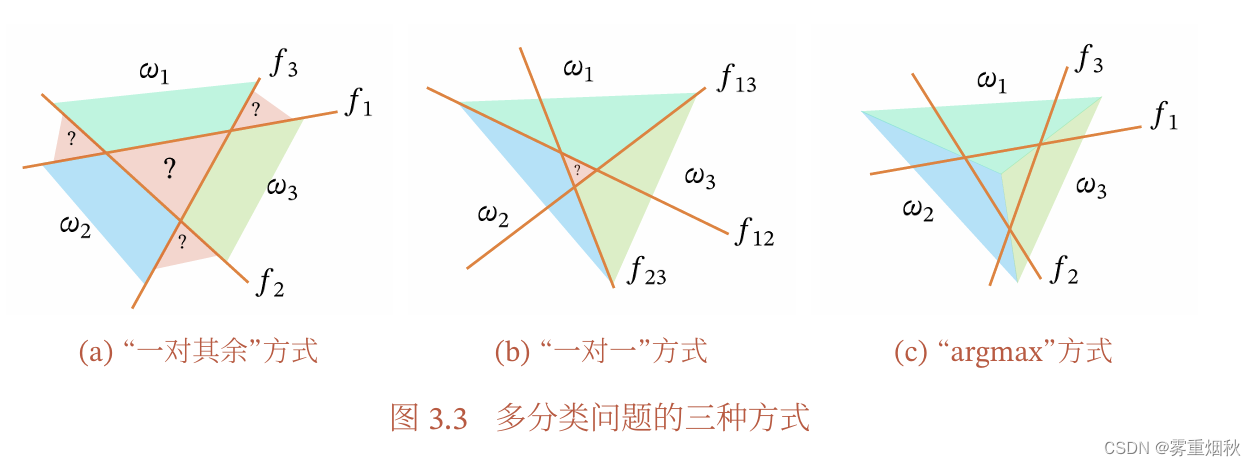
这里解释一下这幅图:
(a)如果有C个类别,那么有C个二分类器,每个二分类器有两种类别(是这个类、不是这个类),以中间区域为例, f 1 f_1 f1显示其不属于类别1,同理,也不属于类别2、3,所以它是无法判断类别的区域。
(b)如果有C个类别,就需要 C ( C − 1 ) / 2 C(C-1)/2 C(C−1)/2个二分类器,每个分类器有两种类别(是这个类,是那个类),比如说 ω 2 \omega 2 ω2和 ω 3 \omega 3 ω3就训练出了一个分类器 f 2 3 f_23 f23,划分第二类或者第三类,而中间部分根据分类器投票结果得到,由于投票可能出现平票的情况,如图就是类别1、2、3各一票,因此也无法判断类别。
(c)C个分类器,但是在难以确定类别的区域,使用argmax来决策,确定为分数最高的类别。

Logistic回归

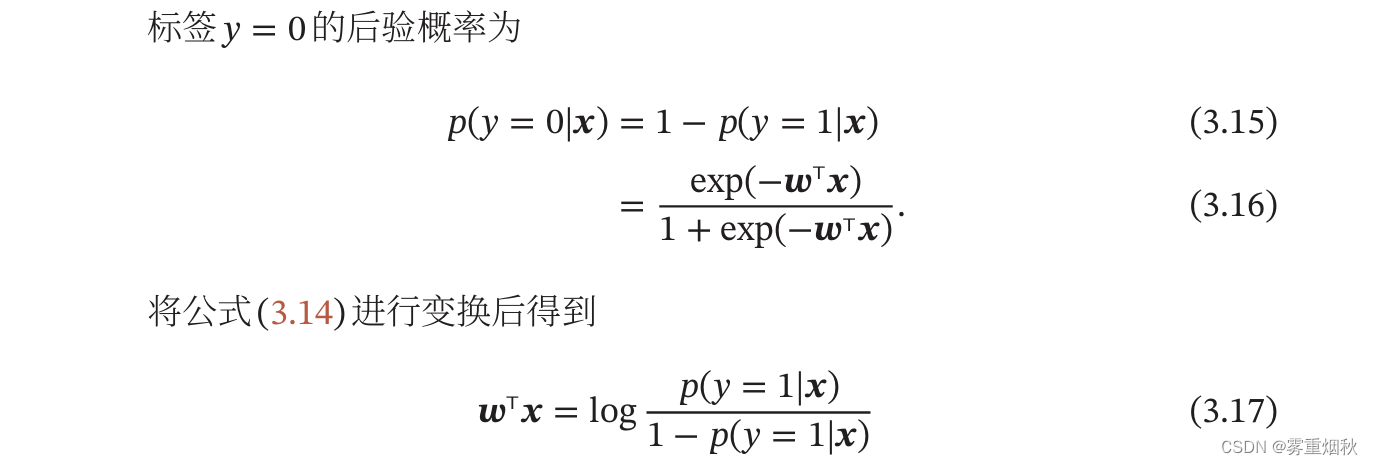

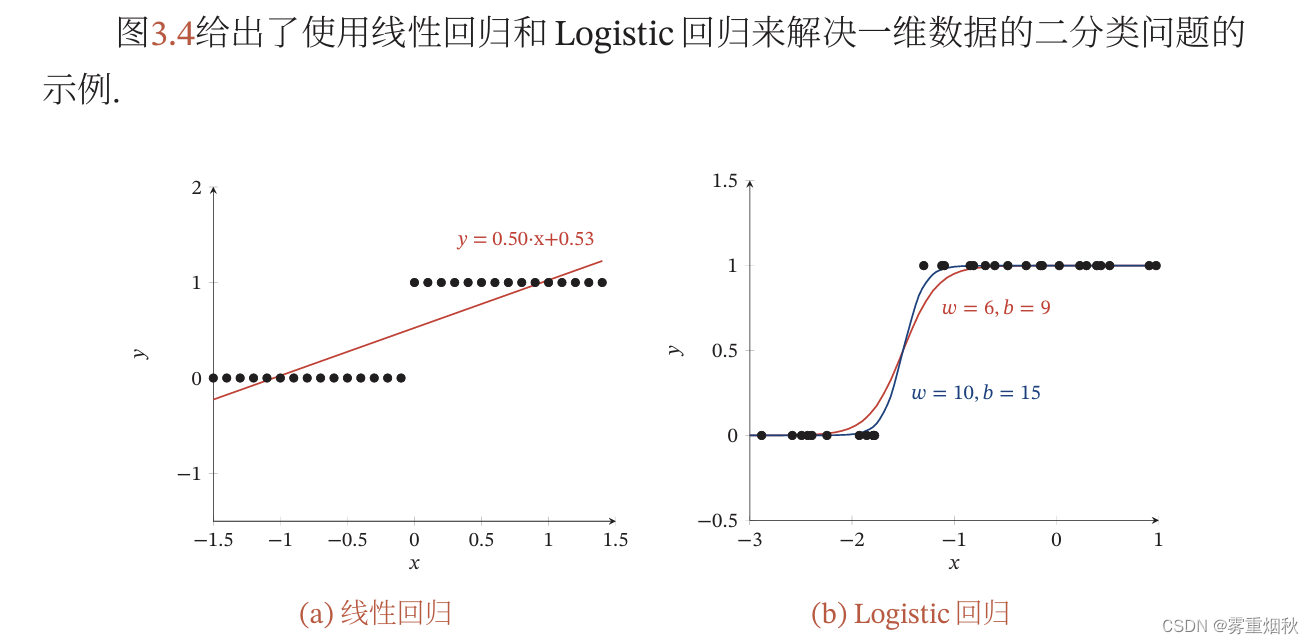
参数学习


Softmax回归


参数学习




感知器

参数学习

这里需要解释更新权重的过程:每次分错一个样本 ( x , y ) (\bm x,y) (x,y)时,即 y ω T x < 0 y\bm \omega^T \bm x<0 yωTx<0,用 ω ^ = ω + y x \hat{\bm \omega} = \bm \omega+y\bm x ω^=ω+yx来更新权重,这样的话,当再次分这个样本的时候, y ω ^ x = y ( ω + y x ) T x = y ω T x + y 2 x T x = y ω T x + x T x > = y ω T x y\hat{\bm \omega} \bm x = y(\bm \omega + y\bm x)^T \bm x =y\bm \omega^T \bm x+y^2\bm x^T \bm x =y\bm \omega^T \bm x+\bm x^T \bm x>=y\bm \omega^T \bm x yω^x=y(ω+yx)Tx=yωTx+y2xTx=yωTx+xTx>=yωTx,所以这个值会变大,最终会大于0,也就是分类正确,所以这个更新权重的方式是合理的。
这种更新参数方式和Logistic回归区别在于,后者是更新的预测和真实值的差异,所以Logistic似乎更加合理。感知器只有犯错才更新,Logistic不管是否犯错,只要与真实分布有差异,就会更新参数。

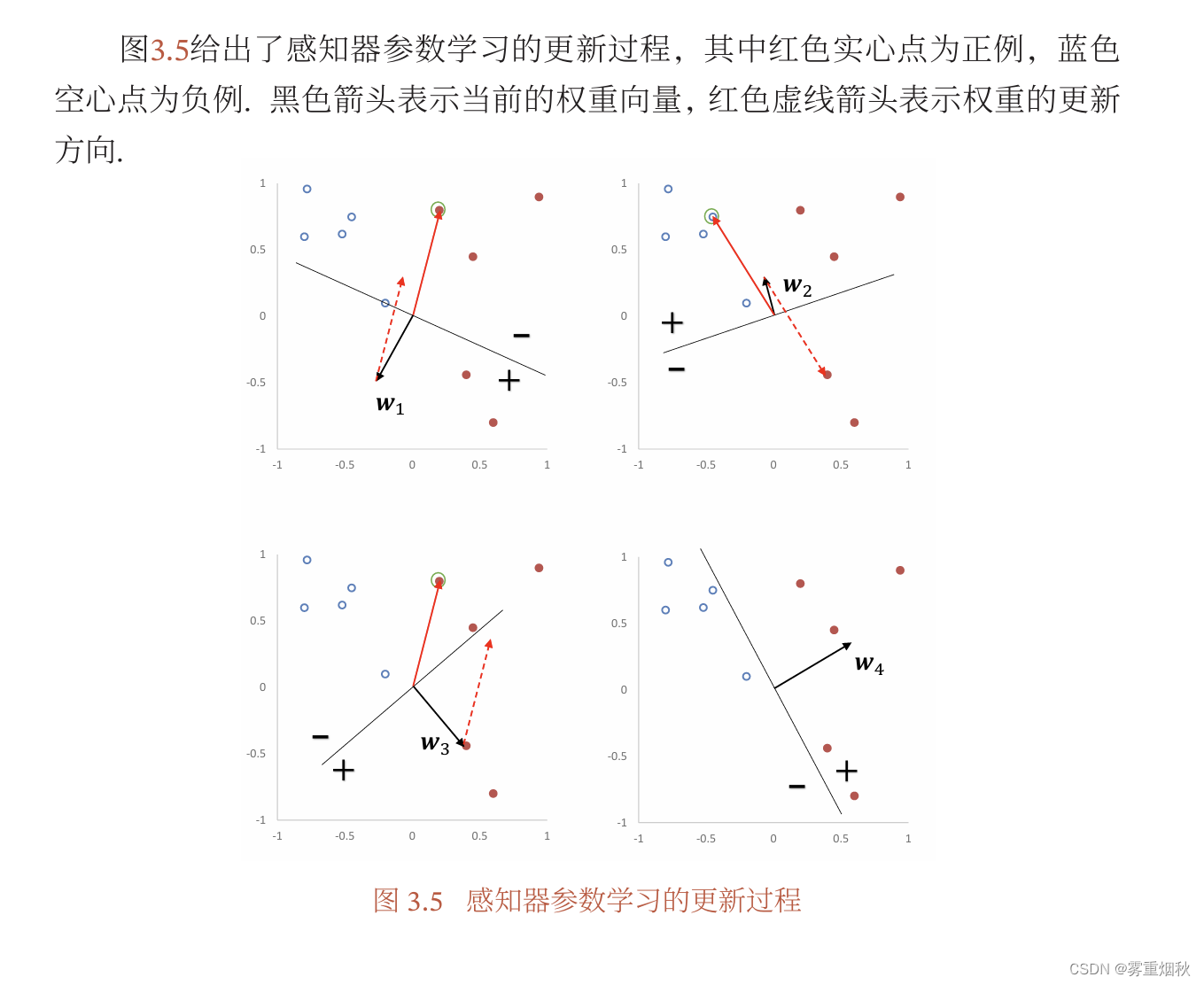
感知器的收敛性



参数平均感知器




扩展到多分类

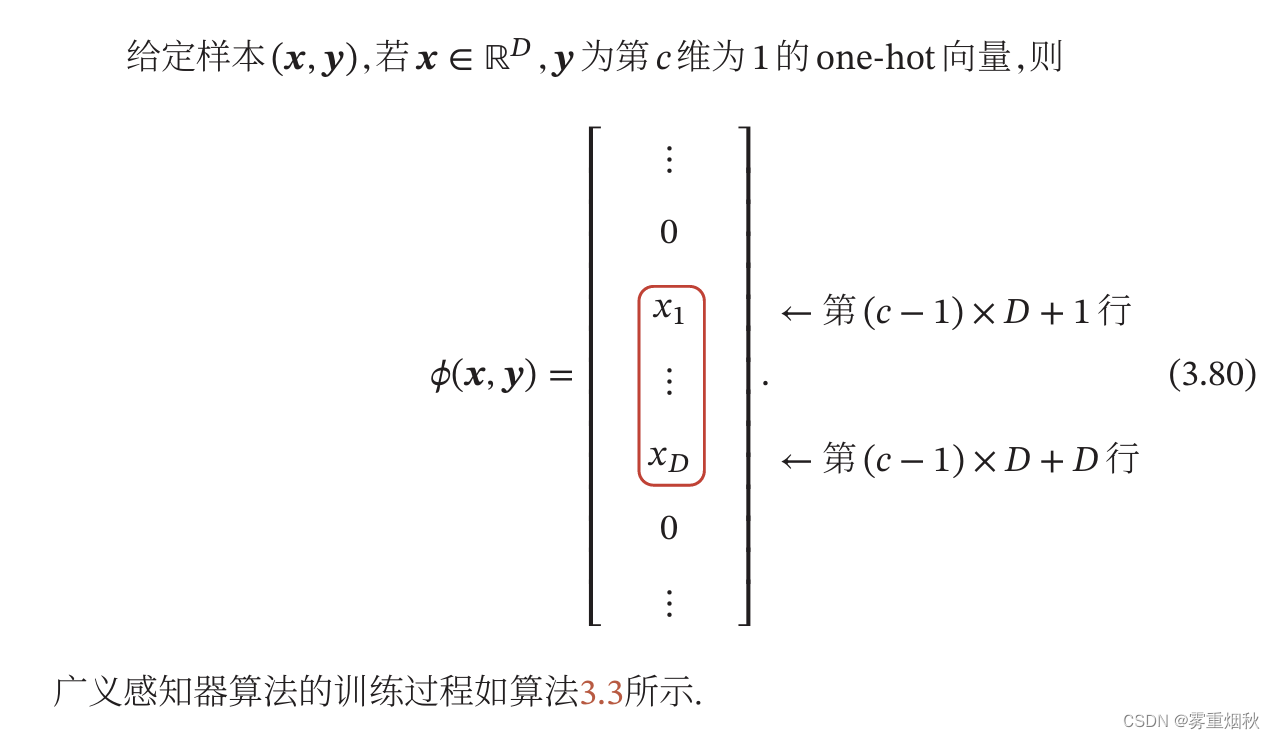

广义感知器的收敛性


支持向量机


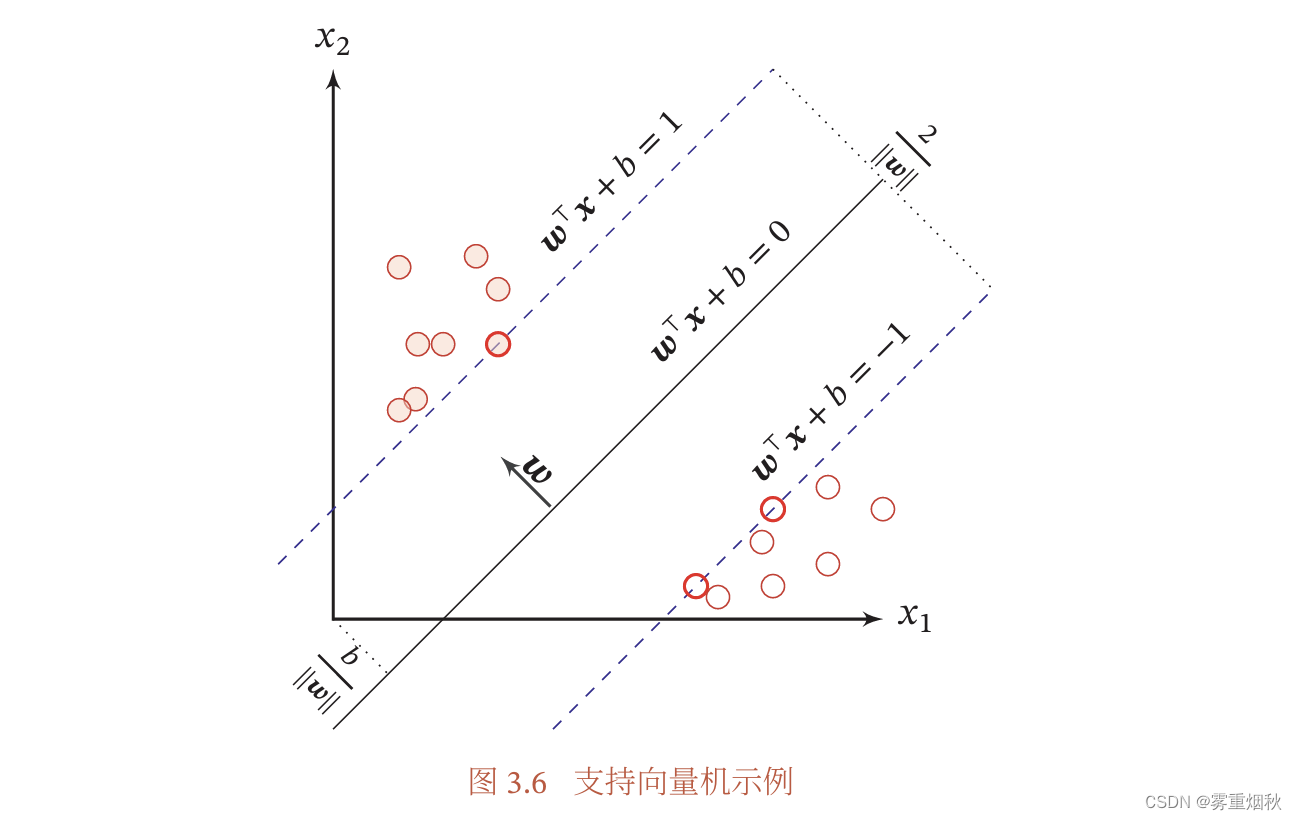
**支持向量机就是要找到一个超平面,让最短距离(间隔)最大,即数据集中所有样本到分割超平面的最短距离最大。**图中的两条虚线就是支持向量,上面的那个点到超平面的距离就是间隔,这就是最短距离,决策边界是由支持向量决定的。
参数学习



核函数

软间隔
支持向量原始定义必须让样本在特征空间线性可分,对于不满足线性可分约束的样本,需要引入松弛变量


损失函数对比

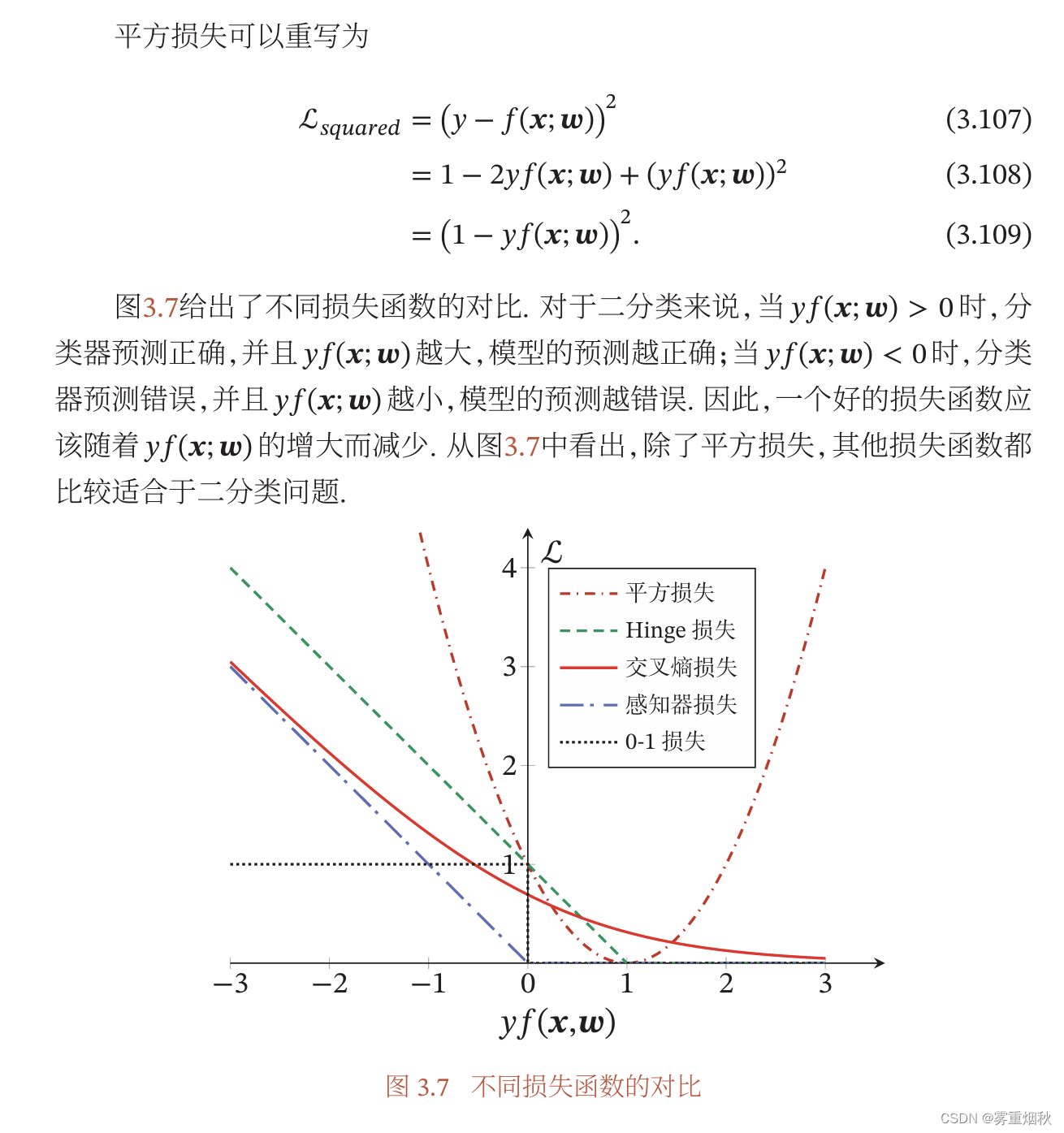
这里给出解释,这个图给出了平方损失、Hinge损失、交叉熵损失、感知器损失和0-1损失在二分类上的对比,横坐标 y f ( x , ω ) yf(\bm x,\bm \omega) yf(x,ω)小于0代表分类错误,大于0是分类正确,可以看到,平方损失 L s q u a r e d = ( y − f ( x ; ω ) ) 2 = 1 − 2 y f ( x ; ω ) + ( y f ( x ; ω ) ) 2 = ( 1 − y f ( x ; ω ) ) 2 L_squared=(y-f(\bm x;\bm \omega))^2=1-2yf(\bm x;\bm \omega)+(yf(\bm x; \bm \omega))^2=(1-yf(\bm x; \bm \omega))^2 Lsquared=(y−f(x;ω))2=1−2yf(x;ω)+(yf(x;ω))2=(1−yf(x;ω))2在1左边是下降趋势,是合理的,但在1右边,命名已经分类正确并且离决策边界越来越远,但是损失函数反而上升,说明平方损失不适合二分类问题。Logistic回归的交叉熵损失求出来是公式3.104的形式,可以看出随着分类越正确,损失降低,但是即时已经划分正确了,它还是会有一部分损失,会进行参数更新。感知器损失是专门为二分类服务的,只有分错的情况才会有损失,软间隔支持向量机的损失函数相当于感知器损失函数向右平移一个单位。一个好的损失函数应该随着 y f ( x , ω ) yf(\bm x,\bm \omega) yf(x,ω)的增大而减少。
总结和深入阅读


习题

证明:设决策平面是 f ( x , ω ) = ω T x + b = 0 f(\bm x,\bm \omega)=\bm \omega^T \bm x+b=0
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1258
1258

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









