









 超级会员免费看
超级会员免费看

1、这篇文章做了什么?
这篇文章要解决的问题是如何在视觉配音中保持和突出说话者的个性,包括说话风格和面部细节。现有的方法在生成高保真结果方面表现出色,但在捕捉说话者独特的说话风格或保留面部细节方面存在不足。该问题的研究难点包括:在音频驱动的视觉配音中,既要保持准确的口型同步,又要突出说话者的个性特征,这是一个相当具有挑战性的任务。现有方法在生成高质量的口型同步效果时,往往会忽略说话者的个性特征,导致生成的视频缺乏个性化表达。
论文题目:PersonaTalk: Bring Attention to Your Persona in Visual Dubbing
项目主页:https://grisoon.github.io/PersonaTalk/
2、这篇文章提出了什么方法?
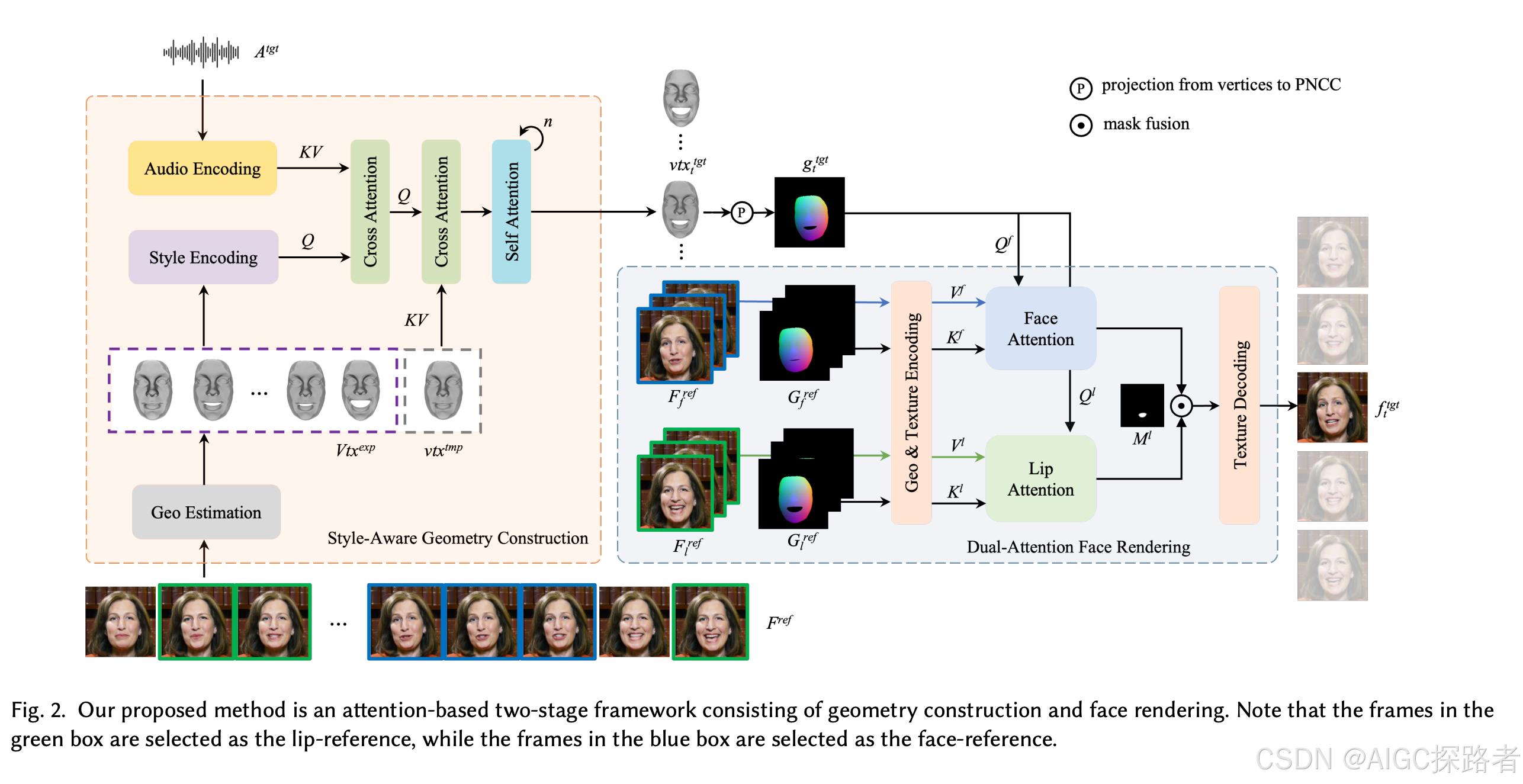
这篇论文提出了一种基于注意力机制的两阶段框架,用于解决视觉配音中保持和突出说话者个性的问题。具体来说,
1、几何构建阶段:首先,提出了一种风格感知的音频编码模块,通过交叉注意力层将说话风格注入到音频特征中。然后,

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 2842
2842

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











