







目录
前言:项目中需要使用批量文件导入的功能,调研了Spring Batch对应的用法。本文介绍了Spring Batch的基本概念和示例用法,读取平面文件,对数据进行处理后保存至数据库中。更多Spring Batch的介绍和用法请参考官网:
https://spring.io/projects/spring-batch
https://docs.spring.io/spring-batch/docs/4.2.1.RELEASE/api
一、Spring Batch简介
Spring Batch是一个轻量级、全面的批处理框架,旨在支持开发健壮的批处理成用程序。Spring Batch建在Spring Framework特性的基础上,使开发人员能够轻松使用更高级的企业服务。
与调度框架不同,Spring Batch不是一个独立的调度程序。但Spring Batch旨在与调度程序结合使用,以实现批处理作业的处理和调度。通过结合使用Spring Batch和企业调度程序,可以创建功能强大的批处理系统,可以可靠地处理大量的数据和业务操作,提高系统的可靠性和稳定性。
二、业务场景
在当前的系统开发中存在一种场景:
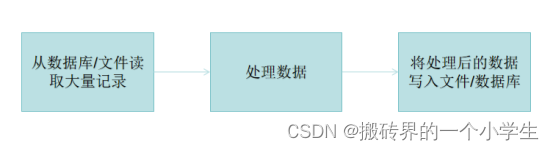
SpringBatch支持以下业务场景:
定期提交批处理、并发处理作业、分阶段的企业消息驱动处理、大规模并行批处理、失败后手动或计划重启、相关步骤的顺序处理、部分处理(例如在回滚时跳过记录)和整批交易(适用于批量较小的情况)等场景。与调度程序结合使用,而不是替代调度程序。
三、基础知识
3.1 基础架构
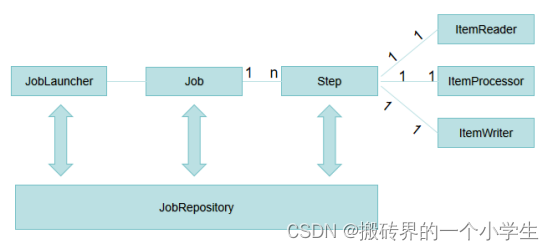
| 名称 | 作用 |
| JobRepository | 为所有的原型(Job、Joblnstance、Step)提供持久化的支持 |
| JobLauncher | 表示一个简单的接口,用于启动一个Job给定的集合JobParameters |
| Job | 封装了整个批处理处理过程的实体 |
| Step | 一个域对象,封装了批处理作业的一个独立的顺序阶段 |
3.2 核心接口
- ItemReader:表示一个Step的输入,一次批处理或一块条目。
- ltemProcessor:表示一个条目的业务处理。
- Itemwriter:表示一个Step的输出,一次批处理或一块条目。
大体流程为输入-->数据加工-->输出,一个Job包含一个或多个Step及处理流程,一个Step
通常涵盖 ltemReader、ltemProcessor和ltemWriter。
四、代码示例
以批处理文件,将数据处理后,写入数据库,以Student学生信息为例:
4.1 引入POM依赖
<!--spring batch 批处理-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-batch</artifactId>
<version>2.3.12.RELEASE</version>
</dependency>4.2 读取和写入实体类
4.2.1 文件读取实体类
在文件读取时,将字段值映射到实体类StudentFile中
@Data
@AllArgsConstructor
@NoArgsConstructor
public class StudentFile {
/**
* id 20
*/
private String id;
/**
* 姓名 50
*/
private String name;
/**
* 年龄 5
*/
private int age;
/**
* 性别 5
*/
private String sex;
/**
* 地址 100
*/
private String address;
/**
* 联系电话 20
*/
private String phone;
}4.2.2 文件写入实体类
在数据处理完成之后,进行数据库写入时的实体类StudentEntity
@Data
@AllArgsConstructor
@NoArgsConstructor
public class StudentEntity {
private static final long serialVersionUID = 1L;
/**
* id 20
*/
private String id;
/**
* 姓名 50
*/
private String name;
/**
* 年龄 5
*/
private int age;
/**
* 性别 5
*/
private String sex;
/**
* 地址 100
*/
private String address;
/**
* 联系电话 20
*/
private String phone;
/**
* 创建时间 20
*/
private String createTime;
}4.2.3 二者区别
根据ItemProcessor<I, O>的接口定义,文件数据处理时,映射泛型为I的实体,处理后,返回一个O类型的实体供写入操作。写入实体类与读取实体类也可以相同,具体看业务需求。
package org.springframework.batch.item;
import org.springframework.lang.NonNull;
import org.springframework.lang.Nullable;
public interface ItemProcessor<I, O> {
@Nullable
O process(@NonNull I var1) throws Exception;
}4.3 数据处理Processor
数据处理类,将读取的数据进行转换、筛选等操作。
@Slf4j
@Component
public class StudentFileProcessor implements ItemProcessor<StudentFile, StudentEntity> {
private JobParameters jobParameters;
@BeforeStep
public void beforeStep(final StepExecution stepExecution) {
jobParameters = stepExecution.getJobParameters();
}
//通过jobParameters接收参数
public String getHandleDate() {
return jobParameters.getString("createTime");
}
@Override
public StudentEntity process(StudentFile student) throws Exception {
if (Objects.isNull(student)) {
//跳过空行
return null;
}
//数据处理 此处简单赋值
StudentEntity studentEntity = new StudentEntity();
studentEntity.setId(UUID.randomUUID().toString().replace("-","").substring(0,20));
studentEntity.setName(student.getName());
studentEntity.setAge(student.getAge());
studentEntity.setSex(student.getSex());
studentEntity.setAddress(student.getAddress());
studentEntity.setPhone(student.getPhone());
studentEntity.setCreateTime(getHandleDate());
return studentEntity;
}
}4.4 配置Job
4.4.1 新建配置类
新建配置类StudentFileStepConfig,配置Job、Step、ItemReader、ItemWriter等。
@Slf4j
@Configuration
public class StudentFileStepConfig {
@Resource
private JobBuilderFactory jobBuilderFactory;
@Resource
private StepBuilderFactory stepBuilderFactory;
@Resource
private StudentFileProcessor studentFileProcessor;
@Resource
private DataSource dataSource;
}以下小节中的配置均在此配置类中。
4.4.2 配置ItemWriter
配置ItemWriter,通过JDBC将数据写入到数据库中。
/**
* 配置ItemWriter
*
* @return ItemWriter
*/
@Bean
public JdbcBatchItemWriter studentJdbcBatchItemWriter() {
//便用JdbcBatchItemWriter通过JDBC将数据写到数据库中
JdbcBatchItemWriter writer = new JdbcBatchItemWriter();
//设置数据源
writer.setDataSource(dataSource);
//设置插入更新的SQL,注意占位符的写法 :"属性名"
writer.setSql("insert into student(id, name, age, sex, address, phone, createTime) values (:id, :name, :age, :sex, :address, :phone, :createTime)");
writer.setItemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider());
return writer;
}4.4.3 配置ItemReader
1、配置ItemReader,读取文件时,通常以FlatFileItemReader实现。
/**
* 配置ItemReader
*
* @return ItemReader
*/
@Bean
@StepScope
public FlatFileItemReader<StudentFile> studentFileReader() {
//FlatFileItemReader 是一个加载普通文件的 ItemReader
FlatFileItemReader<StudentFile> reader = new FlatFileItemReader<>();
//第一行为标题跳过,若没有标题,注释掉即可
// reader.setLinesToSkip(1);
String fileName = "studentinfo";
String filePath = "C:\\test";
String fullName = filePath + File.separator + fileName;
FileSystemResource fileResource = new FileSystemResource(fullName);
reader.setEncoding("GBK");
reader.setResource(fileResource);
reader.setLineMapper(new DefaultLineMapper<StudentFile>() {
{
setLineTokenizer(
//固定长度分割
studentFixedLengthTokenizer()
);
setFieldSetMapper(new BeanWrapperFieldSetMapper() {
{
setTargetType(StudentFile.class);
}
});
}
});
return reader;
}2、配置tokenizer,文件格式为定长,使用FixedLengthTokenizer 。
(1)Range的范围截取需要按照文件的格式,从1开始计算,截取相应的值。Range数组顺序与Names的列一一对应。
(2)此处没有读取文件的全部列,只是截取了部分,所以需要设置tokenizer.setStrict(false)。
/**
* 定长分割,文件一行长度固定,每个字段固定长度,长度不足的,数字前补0,字符串后补空格
*
* @return
*/
@Bean
public FixedLengthTokenizer studentFixedLengthTokenizer() {
FixedLengthTokenizer tokenizer = new FixedLengthTokenizer();
//设置文件中一共有多少列,分别是哪些列
//需要读取的列
tokenizer.setNames("name", "age", "sex", "address", "phone");
tokenizer.setColumns(
// new Range(1, 20),//id 20
new Range(21, 70),//姓名 50
new Range(71, 75),//年龄 5
new Range(76, 80),//性别 5
new Range(81, 180),//地址 100
new Range(181, 200)//联系电话 20
);
/*
是否严格匹配。设置读取一行的部分列时,必须设置为false。
例如一行里有30个字段,但是只读取其中10个字段,其他字段忽略不需要读取。
可以容忍标记比较少的行,并用空列填充,标记较多的行将被简单地截断。默认为true
*/
tokenizer.setStrict(false);
return tokenizer;
}3、若文件格式为分隔符分割,则配置tokenizer时,需要使用DelimitedLineTokenizer ,并将全部的列一一列出。
4、按照文件格式的需要与第2步二选一即可。
/**
* 分割符分割,文件一行长度不固定,字段之间使用指定的分隔符进行分割
*
* @return
*/
@Bean
public DelimitedLineTokenizer studentDelimitedLineTokenizer() {
DelimitedLineTokenizer tokenizer = new DelimitedLineTokenizer();
tokenizer.setNames("id", "name", "age", "sex", "address", "phone");
tokenizer.setDelimiter(" ");
return tokenizer;
}4.4.4 配置Processor
在4.3数据处理中已经单独实现,此处通过注入的形式配置。
@Resource
private StudentFileProcessor studentFileProcessor;4.4.5 配置Step
/**
* 配置Step
*
* @return Step
*/
@Bean
public Step studentStep() {
return stepBuilderFactory.get("studentStep")//通过get获取一个stepBuilder,参数为step的name
.<StudentFile, StudentEntity>chunk(5000)//配置chunk,每读取5000条,就执行一次writer操作
.reader(studentFileReader())//配置reader
.processor(studentFileProcessor)//配置processor,进行数据的预处理
.writer(studentJdbcBatchItemWriter())//配置writer
.taskExecutor(new SimpleAsyncTaskExecutor())
.build();
}4.4.6 配置Job
一个Job可以包含多个Step。至此,一个完整的Job配置完成。
/**
* 配置Job
*
* @return Job
*/
@Bean
public Job studentBatchJob() {
return jobBuilderFactory.get("studentJob")//通过 jobBuilderFactory 构建一个 Job. get参数为 Job 的name
.start(studentStep())//配置该Job的Step
//.next(studentStep2())//多个Step时,通过next()进行配置
.build();
}4.5 调用Job
在Service的实现类中,使用jobLauncher.run(),通过Job的名称“studentBatchJob”调用指定的Job。
@Slf4j
@Service
public class StudentServiceImpl implements StudentService {
@Resource
private JobLauncher jobLauncher;
@Resource
private Job studentBatchJob;
@Override
public String importStudentFile() {
log.info("导入学生信息开始...");
try {
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd hh:mm:ss");
String createTime = sdf.format(new Date());
JobParameters jobParameters = new JobParametersBuilder()
.addString("createTime", createTime)
.toJobParameters();
jobLauncher.run(studentBatchJob, jobParameters);
} catch (Exception e) {
log.error("导入学生信息异常", e);
}
log.info("导入学生信息结束...");
return "success";
}
}五、接口测试
5.1 接口测试
@Controller
@RequestMapping("/student")
public class StudentController {
@Resource
private StudentService studentService;
@PostMapping("import")
@ResponseBody
public String importStudentFile() {
return studentService.importStudentFile();
}
}
5.2 通过postman测试
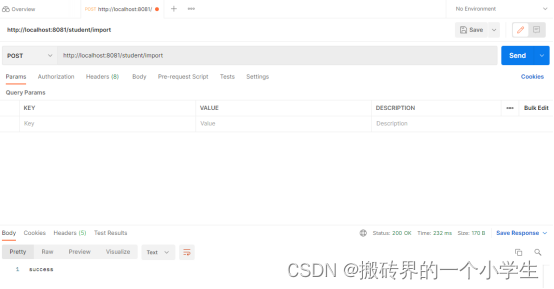
5.3 查看控制台日志

5.4 查看数据库记录

六、问题记录
1、在processor中,如果要使用调用时传进来的参数,例如“createTime”,需要通过JobParameters 来传值和获取。详细见4.3数据处理Processor和4.5调用Job
2、如果文件中出现空行,在processor中进行判断,如果读取的对象属性全为null,直接return null即可。
3、在ItemWriter中,注意sql的写法,以及参数的占位符,需要用“:属性名”。
4、在配置tokenizer时,文件有定长和分隔符的区分,如果是定长文件,需要计算每个列的区间Range,字段较多时,可以使用Excel表格辅助计算。
5、定长文件的tokenizer,如果字段较多,但是只需要读取其中部分,例如一行里有30个字段,但是只读取其中10个字段,其他字段忽略不需要读取,需要设置 tokenizer.setStrict(false)。(一个小坑,最后通过官网的api解决)
七、示例代码地址
github:https://github.com/wgt7/spring-batch-file
gitee:https://gitee.com/no-one7/spring-batch-file















 2627
2627











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









