





🏆 作者简介,愚公搬代码
🏆《头衔》:华为云特约编辑,华为云云享专家,华为开发者专家,华为产品云测专家,CSDN博客专家,CSDN商业化专家,阿里云专家博主,阿里云签约作者,腾讯云优秀博主,腾讯云内容共创官,掘金优秀博主,51CTO博客专家等。
🏆《近期荣誉》:2022年度博客之星TOP2,2023年度博客之星TOP2,2022年华为云十佳博主,2023年华为云十佳博主等。
🏆《博客内容》:.NET、Java、Python、Go、Node、前端、IOS、Android、鸿蒙、Linux、物联网、网络安全、大数据、人工智能、U3D游戏、小程序等相关领域知识。
🏆🎉欢迎 👍点赞✍评论⭐收藏
🚀前言
在安装Hadoop之前,需要进行以下准备工作:
-
确认操作系统:Hadoop可以运行在多种操作系统上,包括Linux、Windows和Mac OS等。选择适合你的操作系统,并确保操作系统版本符合Hadoop的要求。
-
安装Java环境:Hadoop是基于Java开发的,因此需要先安装和配置Java环境。确保已经安装了符合Hadoop版本要求的Java Development Kit (JDK),并设置好JAVA_HOME环境变量。
-
确认硬件要求:Hadoop是一个分布式系统,因此需要多台计算机组成集群。每台计算机至少需要具备一定的处理能力(如多核处理器)、足够的内存和硬盘空间等。根据Hadoop版本和集群规模,确认硬件要求并准备相应的计算机。
-
确认网络连接:Hadoop集群中的各个节点需要能够互相通信,因此需要保证网络连接正常。确保集群中的计算机之间可以通过局域网或云服务商的虚拟网络互相访问。
-
下载Hadoop软件包:从Hadoop官方网站下载适合你的操作系统和Hadoop版本的软件包。也可以考虑使用一些Hadoop发行版(如Cloudera、Hortonworks和Apache Bigtop等),它们提供了预配置的Hadoop环境和管理工具,简化安装和配置的过程。
-
配置Hadoop:在安装Hadoop之前,需要对Hadoop的相关配置文件进行调整和设置,包括Hadoop的核心配置文件(如hadoop-env.sh、core-site.xml等)和HDFS配置文件(如hdfs-site.xml)等。根据自己的需求和集群规模,进行相应的配置。
准备工作完成后,可以按照官方文档或相关教程的指引,进行Hadoop的安装和配置。安装完成后,可以启动Hadoop集群并验证其正常运行。
本文主要讲解Hadoop的安装
🚀一、appache版本hadoop重新编译
🔎1.appache版本hadoop重新编译
🦋1.1 为什么要编译hadoop
由于appache给出的hadoop的安装包没有提供带C程序访问的接口,所以我们在使用本地库(本地库可以用来做压缩,以及支持C程序等等)的时候就会出问题,需要对Hadoop源码包进行重新编译.
🦋1.2 编译环境的准备
☀️1.2.1 准备linux环境
准备一台linux环境,内存4G或以上,硬盘40G或以上,我这里使用的是Centos6.9 64位的操作系统(注意:一定要使用64位的操作系统)
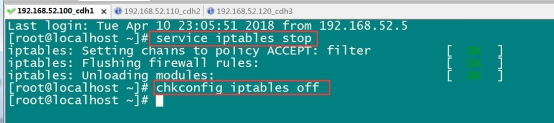
☀️1.2.2 虚拟机联网,关闭防火墙,关闭selinux
关闭防火墙命令:
service iptables stop
chkconfig iptables off
关闭selinux
vim /etc/selinux/config

☀️1.2.3 安装jdk1.7
注意hadoop-2.7.5 这个版本的编译,只能使用jdk1.7,如果使用jdk1.8那么就会报错
查看centos6.9自带的openjdk
rpm -qa | grep java
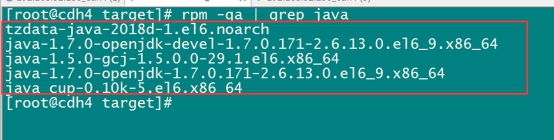
将所有这些openjdk全部卸载掉
rpm -e java-1.6.0-openjdk-1.6.0.41-1.13.13.1.el6_8.x86_64 tzdata-java-2016j-1.el6.noarch java-1.7.0-openjdk-1.7.0.131-2.6.9.0.el6_8.x86_64
注意:这里一定不要使用jdk1.8,亲测jdk1.8会出现错误
将我们jdk的安装包上传到/export/softwares(我这里使用的是jdk1.7.0_71这个版本)
解压我们的jdk压缩包
统一两个路径
mkdir -p /export/servers
mkdir -p /export/softwares
cd /export/softwares
tar -zxvf jdk-7u71-linux-x64.tar.gz -C ../servers/
配置环境变量
vim /etc/profile
export JAVA_HOME=/export/servers/jdk1.7.0_71
export PATH=:$JAVA_HOME/bin:$PATH

让修改立即生效
source /etc/profile
☀️1.2.4 安装maven
这里使用maven3.x以上的版本应该都可以,不建议使用太高的版本,强烈建议使用3.0.5的版本即可
将maven的安装包上传到/export/softwares
然后解压maven的安装包到/export/servers
cd /export/softwares/
tar -zxvf apache-maven-3.0.5-bin.tar.gz -C ../servers/
配置maven的环境变量
vim /etc/profile
export MAVEN_HOME=/export/servers/apache-maven-3.0.5
export MAVEN_OPTS="-Xms4096m -Xmx4096m"
export PATH=:$MAVEN_HOME/bin:$PATH

让修改立即生效
source /etc/profile
解压maven的仓库
tar -zxvf mvnrepository.tar.gz -C /export/servers/
修改maven的配置文件
cd /export/servers/apache-maven-3.0.5/conf
vim settings.xml
指定我们本地仓库存放的路径
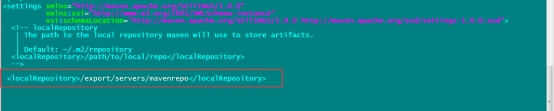
添加一个我们阿里云的镜像地址,会让我们下载jar包更快
<mirror>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>

☀️1.2.5 安装findbugs
解压findbugs
tar -zxvf findbugs-1.3.9.tar.gz -C ../servers/
配置findbugs的环境变量
vim /etc/profile
export JAVA_HOME=/export/servers/jdk1.7.0_75
export PATH=:$JAVA_HOME/bin:$PATH
export MAVEN_HOME=/export/servers/apache-maven-3.0.5
export PATH=:$MAVEN_HOME/bin:$PATH
export FINDBUGS_HOME=/export/servers/findbugs-1.3.9
export PATH=:$FINDBUGS_HOME/bin:$PATH

让修改立即生效
source /etc/profile
☀️1.2.6 在线安装一些依赖包
yum install autoconf automake libtool cmake
yum install ncurses-devel
yum install openssl-devel
yum install lzo-devel zlib-devel gcc gcc-c++
bzip2压缩需要的依赖包
yum install -y bzip2-devel
☀️1.2.7 安装protobuf
解压protobuf并进行编译
cd /export/softwares
tar -zxvf protobuf-2.5.0.tar.gz -C ../servers/
cd /export/servers/protobuf-2.5.0
./configure
make && make install
☀️1.2.8 安装snappy
cd /export/softwares/
tar -zxf snappy-1.1.1.tar.gz -C ../servers/
cd ../servers/snappy-1.1.1/
./configure
make && make install
☀️1.2.9 编译hadoop源码
对源码进行编译
cd /export/softwares
tar -zxvf hadoop-2.7.5-src.tar.gz -C ../servers/
cd /export/servers/hadoop-2.7.5
编译支持snappy压缩:
mvn package -DskipTests -Pdist,native -Dtar -Drequire.snappy -e -X
编译完成之后我们需要的压缩包就在下面这个路径里面
/export/servers/hadoop-2.7.5/hadoop-dist/target
🚀二、Hadoop的安装
集群规划
| 服务器IP | 192.168.174.100 | 192.168.174.110 | 192.168.174.120 |
|---|---|---|---|
| 主机名 | node01 | node02 | node03 |
| NameNode | 是 | 否 | 否 |
| SecondaryNameNode | 是 | 否 | 否 |
| dataNode | 是 | 是 | 是 |
| ResourceManager | 是 | 否 | 否 |
| NodeManager | 是 | 是 | 是 |
🔎1.上传apache hadoop包并解压
解压命令
cd /export/softwares
tar -zxvf hadoop-2.7.5.tar.gz -C ../servers/
🔎2.修改配置文件
🦋2.1 修改core-site.xml
第一台机器执行以下命令
cd /export/servers/hadoop-2.7.5/etc/hadoop
vim core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://node01:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/export/servers/hadoop-2.7.5/hadoopDatas/tempDatas</value>
</property>
<!-- 缓冲区大小,实际工作中根据服务器性能动态调整 -->
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!-- 开启hdfs的垃圾桶机制,删除掉的数据可以从垃圾桶中回收,单位分钟 -->
<property>
<name>fs.trash.interval</name>
<value>10080</value>
</property>
</configuration>
🦋2.2 修改hdfs-site.xml
第一台机器执行以下命令
cd /export/servers/hadoop-2.7.5/etc/hadoop
vim hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node01:50090</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>node01:50070</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///export/servers/hadoop-2.7.5/hadoopDatas/namenodeDatas,file:///export/servers/hadoop-2.7.5/hadoopDatas/namenodeDatas2</value>
</property>
<!-- 定义dataNode数据存储的节点位置,实际工作中,一般先确定磁盘的挂载目录,然后多个目录用,进行分割 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///export/servers/hadoop-2.7.5/hadoopDatas/datanodeDatas,file:///export/servers/hadoop-2.7.5/hadoopDatas/datanodeDatas2</value>
</property>
<property>
<name>dfs.namenode.edits.dir</name>
<value>file:///export/servers/hadoop-2.7.5/hadoopDatas/nn/edits</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:///export/servers/hadoop-2.7.5/hadoopDatas/snn/name</value>
</property>
<property>
<name>dfs.namenode.checkpoint.edits.dir</name>
<value>file:///export/servers/hadoop-2.7.5/hadoopDatas/dfs/snn/edits</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
</configuration>
🦋2.3 修改hadoop-env.sh
第一台机器执行以下命令
cd /export/servers/hadoop-2.7.5/etc/hadoop
vim hadoop-env.sh
export JAVA_HOME=/export/servers/jdk1.8.0_141
🦋2.4 修改mapred-site.xml
第一台机器执行以下命令
cd /export/servers/hadoop-2.7.5/etc/hadoop
vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>node01:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node01:19888</value>
</property>
</configuration>
🦋2.5 修改yarn-site.xml
第一台机器执行以下命令
cd /export/servers/hadoop-2.7.5/etc/hadoop
vim yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>20480</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
</configuration>
🦋2.6 修改mapred-env.sh
第一台机器执行以下命令
cd /export/servers/hadoop-2.7.5/etc/hadoop
vim mapred-env.sh
export JAVA_HOME=/export/servers/jdk1.8.0_141
🦋2.7 修改slaves
修改slaves文件,然后将安装包发送到其他机器,重新启动集群即可
第一台机器执行以下命令
cd /export/servers/hadoop-2.7.5/etc/hadoop
vim slaves
node01
node02
node03
第一台机器执行以下命令
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/tempDatas
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/namenodeDatas
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/namenodeDatas2
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/datanodeDatas
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/datanodeDatas2
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/nn/edits
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/snn/name
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/dfs/snn/edits
安装包的分发
第一台机器执行以下命令
cd /export/servers/
scp -r hadoop-2.7.5 node02:$PWD
scp -r hadoop-2.7.5 node03:$PWD
🔎3.配置hadoop的环境变量
三台机器都要进行配置hadoop的环境变量
三台机器执行以下命令
vim /etc/profile
export HADOOP_HOME=/export/servers/hadoop-2.7.5
export PATH=:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
配置完成之后生效
source /etc/profile
🔎4.启动集群
要启动 Hadoop 集群,需要启动 HDFS 和 YARN 两个模块。
注意: 首次启动 HDFS 时,必须对其进行格式化操作。 本质上是一些清理和
准备工作,因为此时的 HDFS 在物理上还是不存在的。
hdfs namenode -format 或者 hadoop namenode –format
准备启动
第一台机器执行以下命令
cd /export/servers/hadoop-2.7.5/
bin/hdfs namenode -format
sbin/start-dfs.sh
sbin/start-yarn.sh
sbin/mr-jobhistory-daemon.sh start historyserver
三个端口查看界面
http://node01:50070/explorer.html#/ 查看hdfs
http://node01:8088/cluster 查看yarn集群
http://node01:19888/jobhistory 查看历史完成的任务
🚀感谢:给读者的一封信
亲爱的读者,
我在这篇文章中投入了大量的心血和时间,希望为您提供有价值的内容。这篇文章包含了深入的研究和个人经验,我相信这些信息对您非常有帮助。
如果您觉得这篇文章对您有所帮助,我诚恳地请求您考虑赞赏1元钱的支持。这个金额不会对您的财务状况造成负担,但它会对我继续创作高质量的内容产生积极的影响。
我之所以写这篇文章,是因为我热爱分享有用的知识和见解。您的支持将帮助我继续这个使命,也鼓励我花更多的时间和精力创作更多有价值的内容。
如果您愿意支持我的创作,请扫描下面二维码,您的支持将不胜感激。同时,如果您有任何反馈或建议,也欢迎与我分享。

再次感谢您的阅读和支持!
最诚挚的问候, “愚公搬代码”



















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











