







单链表专题
1.链表的概念及结构
概念:链表是⼀种物理存储结构上⾮连续、⾮顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的 。
注意: 链表也是线性表的一种
线性表的概念:
线性表 (linear list)是n个具有相同特性的数据元素的有限序列。 线性表是一种在实际中广泛使用的数据结构,常见的线性表: 顺序表、链表、栈、队列、字符串…线性表在逻辑上是线性结构,也就说是连续的一条直线。但是在物理结构上并不一定是连续的线性表.
前面我们学过顺序表
顺序表的物理结构和逻辑结构都是线性的
但是链表 逻辑结构是线性的 物理结构不是线性的
其实可以通过火车车厢去理解
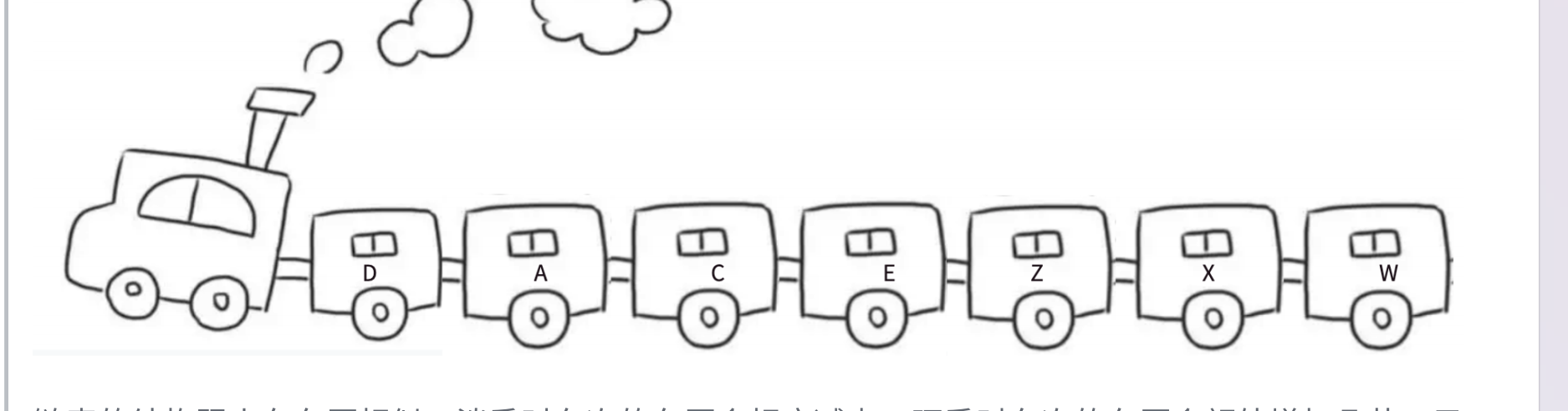
链表的结构跟火车车厢是相似的。有时候根据人流量的需求,我们会不断的去调整车厢的数量。有时候我们在中间增加一个车厢或者减少一个车厢,都不会影响其他车厢,每节车厢都是独立存在的。
而火车是用一种钩子的结构去链接在一起的.
对于链表来说 这个钩子就是指针。
注意了:
- 链表是由一个一个节点组成的(节点也叫结点)
- 链表的每一个节点都放着访问到下一个节点的指针
- 节点是由存储的数据和指向下一个节点的指针组成的
- 最后一个节点的指针要置为NULL
那我们如何去弄出一个链表呢?
- 其实我们只需要定义链表的节点的结构
- 再用指针去把他们链接起来
- 这样一个链表就形成了
那我们如何去定义链表的节点的结构呢?
struct SListNode
{
int data; // 节点所存储的数据
struct SListNode* next;// 指向下一个节点的指针
}
现在我们已经大概的了解了链表的概念和结构
我们之前说顺序表有三个问题,其实这三个问题总结下来就是:
- 中间/头部的插入效率地下
- 增容降低运行效率
- 增容造成空间浪费
那么对于链表来说,这三个问题就能得到解决
注意!:
本文章中的所有头节点的说法 其实都是不太正确,不太严谨的,在本文章中为了便于理解,我将使用头节点作为链表的第一个节点的说法。
实际上头节点(放哨位)是带头链表中的的一个说法
2.单链表的实现
# pragma once
#define _CRT_SECURE_NO_WARNINGS 1
# include<stdio.h>
# include<assert.h>
# include<stdlib.h>
// 定义节点的结构 【数据 + 指向下一个节点的指针】
typedef int SLTDataType;
typedef struct SListNode
{
SLTDataType data;
struct SListNode* next;
}SLTNode;
// 链表的打印
void SLTPrint(SLTNode* phead);
//头部插⼊删除/尾部插⼊删除
void SLTPushBack(SLTNode** pphead, SLTDataType x);
void SLTPushFront(SLTNode** pphead, SLTDataType x);
void SLTPopBack(SLTNode** pphead);
void SLTPopFront(SLTNode** pphead);
//查找
SLTNode* SLTFind(SLTNode* phead, SLTDataType x);
//在指定位置之前插⼊数据
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x);
链表的打印:
// 链表的打印
void SLTPrint(SLTNode* phead)
{
SLTNode* pcur = phead; // 创建一个临时指针 指向phead
// 首先判断传进来的地址是否是NULL
while (pcur)// pcur != NULL
{
printf("%d->", pcur->data);
pcur = pcur->next; // 让指针指向下一个节点 (这就是打印链表数据的关键)
}
printf("NULL\n");
}
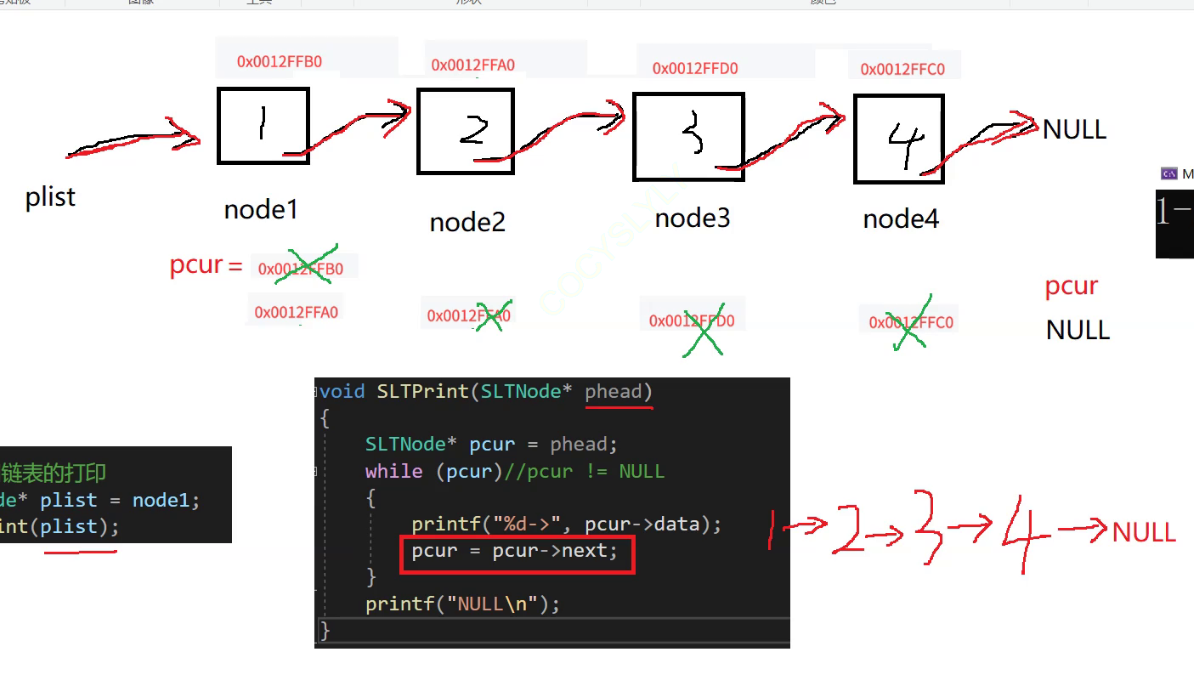
思考:
为什么顺序表可以用++的方式去访问下一个数据 链表不可以呢
因为链表的节点在内存的存储中是不连续的,这就是为什么说链表的物理结构不是线性的原因!
因此只能采用指针的方式,去找到下一个节点.
链表的尾插:
尾插的代码:
// 链表的尾插
void SLTPushBack(SLTNode** pphead, SLTDataType x)
{
// 对pphead进行断言 pphead不能为NULL 不然无法解引用
assert(pphead);
// 想要插入一个节点 那我们就得申请一个节点
SLTNode* newnode = SLTBuyNode(x);
// 对于链表的尾插 我们要分为 空链表和非空链表这两种情况
if (*pphead == NULL) // 空链表
{
*pphead = newnode;
}
else // 非空链表
{
// 想要尾插,先要找尾 也就是最后一个节点
// 让ptail从链表的第一个节点开始找 直至找到NULL
SLTNode* ptail = *pphead;
while (ptail->next != NULL)
// ptail->next是一个对结构体的解引用 我们不能对一个空指针NULL解引用 因此空链表的情况无法处理
{
ptail = ptail->next;
}
// 此时的ptail指向的就是尾节点
// 让尾节点指向我们的新节点 这样就完成了尾插
ptail->next = newnode;
}
}
这是尾插的测试代码:

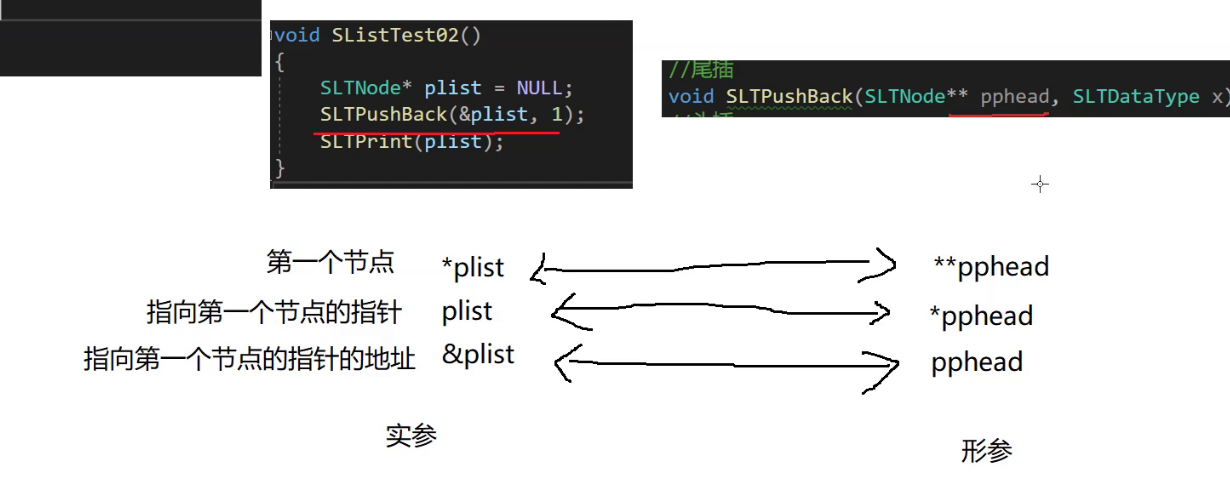
我们会发现 我们传给尾插函数SLTPushBack的实参是&plist,也就是一个二级指针, 而这是为什么呢?
因为我们需要在函数当中通过形参改变我们实参的值 让函数中赋予形参的值能够赋予我们的实参,而想要实现这个就需要——传址调用
如图所示:
到这里我们再来测试一次:
void SListTest02()
{
SLTNode* plist = NULL;
SLTPushBack(&plist, 1);
SLTPushBack(&plist, 2);
SLTPushBack(&plist, 3);
SLTPushBack(&plist, 4);
SLTPrint(plist); // 1->2->3->4->NULL
}
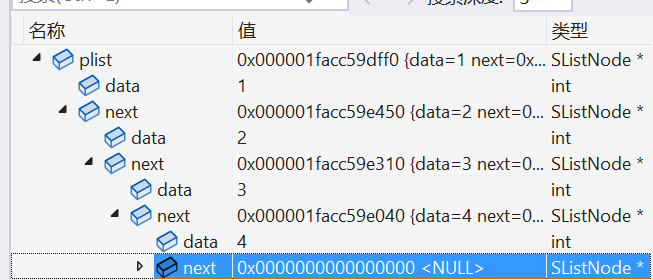
可以看我们调试的图片。
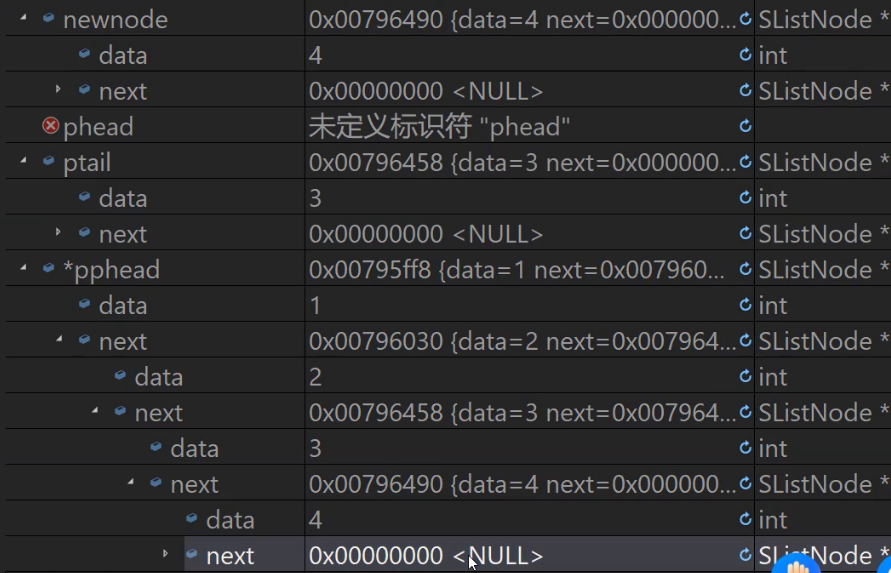
注意了:
我们可以通过调试代码 去走一遍函数的运行思路,能懂调试的思路,过程,才能更好的理解函数!!!
链表的头插:
头插的思路:
- 首先创建一个新的节点 去指向原来的第一个节点 ,取而代之成为新的第一个节点。
- 与此同时还要让 原来指向第一个节点的指针去指向新节点的地址
- 不然即使存在新的头节点,后面访问链表也不回访问到新的头节点
- 也就是如下图所示,让*pphead去指向新的节点,再让新的节点指向原来的头节点
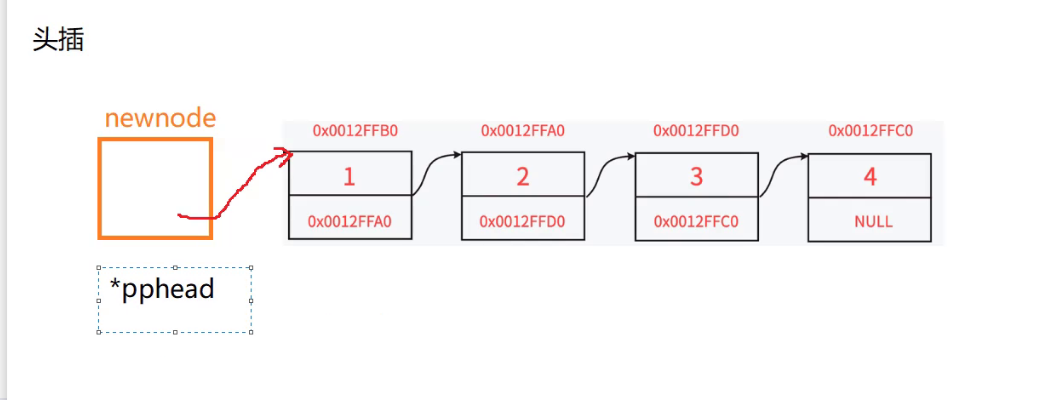
头插的代码:
// 链表的头插
void SLTPushFront(SLTNode** pphead, SLTDataType x)
{
assert(pphead);
// 创建一个要插入链表的新节点
SLTNode* newnode = SLTBuyNode(x);
//让新节点的指针指向原来的头节点
newnode->next = *pphead;
// 再让指向链表头节点的指针 指向新的头节点
*pphead = newnode;
// 无论是空链表还是 非空链表 上面的代码都能完成任务 无需分类讨论了
}
头插的测试代码:
// 测试头插
SLTPushFront(&plist, 6);
SLTPushFront(&plist, 7);
SLTPrint(plist);// 7->6->1->2->3->4->NULL
学完尾插之后 ,再来编写头插就不再难以理解
链表的尾删:
尾删的思路:
- 首先我们要先找到最后一个节点并将其删除
- 这个时候倒数第二个节点prev的指向尾节点的的指针就为野指针
- 我们要将倒数第二个节点的指针置为NULL
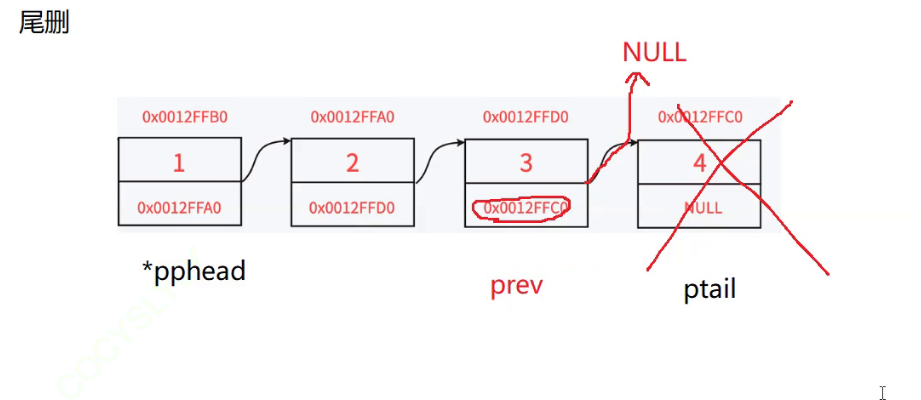
尾删的代码:
// 链表的尾删
void SLTPopBack(SLTNode** pphead)
{
assert(pphead);
// 判断链表是否为空 (空链表还怎么删节点)
assert(*pphead);
// assert(pphead && *pphead); 可以两个断言合并起来
// 找到尾节点并进行删除
// 要分链表有一个节点和有多个节点分类讨论
if ((*pphead)->next == NULL) // 一个节点
{
free(*pphead);
*pphead = NULL;
}
else // 多个节点
{
SLTNode* prev = *pphead;
SLTNode* ptail = *pphead;
// 先找尾节点
while (ptail->next)
{
prev = ptail; // 找到最后一个尾节点的时候 这个此时的prev指向的是倒数第二个节点
ptail = ptail->next;
}
// 删除尾节点
free(ptail);
ptail = NULL;
prev->next = NULL; //让新的尾节点存储的指针为NULL 这样才是新的尾节点
// 如果只有一个节点的话 这里的解引用就会失败 因为prev和ptail指向的是一个节点
// 当把节点空间释放掉的时候 这里的prev指向的就是NULL 对NULL进行结构体访问成员的 -> 当然会报错
}
}
尾删的测试:
//测试尾删
SLTPopBack(&plist);
SLTPrint(plist);
SLTPopBack(&plist);
SLTPrint(plist);
SLTPopBack(&plist);
SLTPrint(plist);
SLTPopBack(&plist);
SLTPrint(plist);
SLTPopBack(&plist);
SLTPrint(plist);
SLTPopBack(&plist);
SLTPrint(plist);
SLTPopBack(&plist);
SLTPrint(plist);
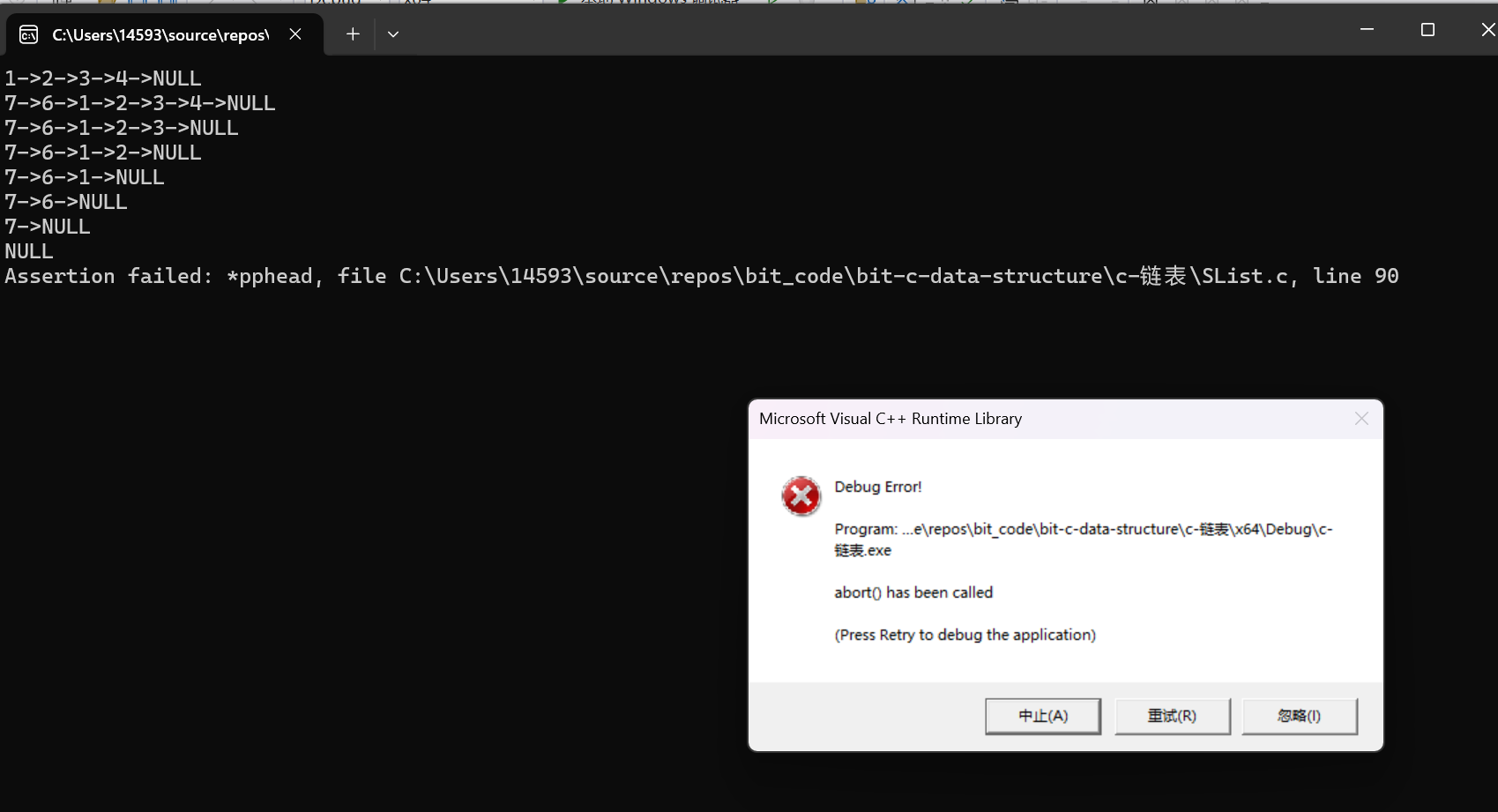
可以看到我们的代码是可以正常运行的
说明我们的尾删函数是可以正常工作的
链表的头删:
头删的思路:
1.首先是多个节点的思路:
- 首先就是要找到头节点
- 找到头节点不能着急去释放掉其空间,应该就把下一个节点的地址保存下来
- 并且让访问链表头节点的指针指向下一个节点的地址 让其成为新的头节点
- 最后才是把第一个节点给删掉,也就是释放掉其空间
如图所示:
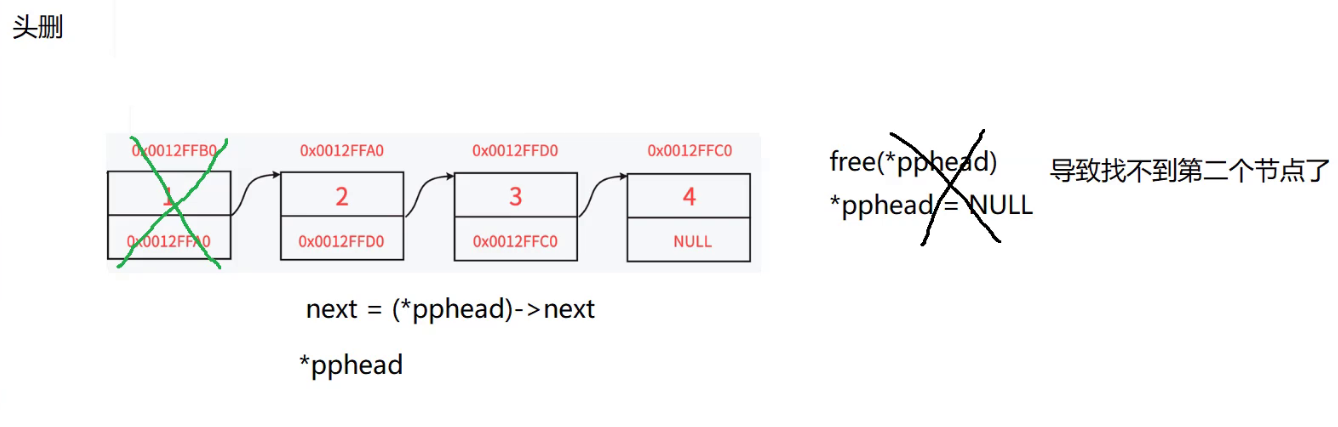
先将第二个节点的地址保存用next保存下来
然后再用*pphead去指向第二个节点的地址 这样以后访问这个链表的时候,就是从第二个节点开始访问,这个节点就变成了新的头节点
2.只有一个节点的思路 :
- 当只有一个节点的时候就不需要去考虑那么多了
- 只需要将其空间释放掉,并将访问链表的指针置为空。
头删的代码:
// 链表的头删
void SLTPopFront(SLTNode** pphead)
{
assert(pphead);
// 判断是否为空链表
assert(*pphead);
// 首先保存下第二个节点的地址
SLTNode* next = (*pphead)->next;
// 删除第一个节点
free(*pphead);
// 让访问链表的指针指向第二个节点的地址
*pphead = next;
// 这个可以处理1个节点和多个节点的情况
}
头删的测试:
// 测试头删
// 7->6->1->NULL
SLTPopFront(&plist);
SLTPopFront(&plist);
//SLTPopFront(&plist);
//SLTPopFront(&plist); // Assertion failed: *pphead
SLTPrint(plist);// 1->NULL
我们现在再来复习一下各个形参和实参的关系:
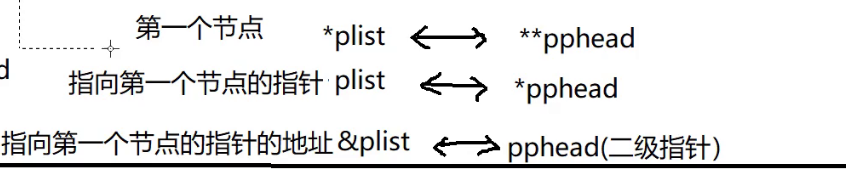
链表的查找:
查找的思路:
- 首先是让一个新的指针去指向链表的头节点
- 然后遍历所有节点 查找是否有数据和要找的相同
- 找到了就返回节点
- 没找到就返回NULL
查找的代码:
// 链表的查找
SLTNode* SLTFind(SLTNode* phead, SLTDataType x)
{
// 让pcur来取代访问链表的头节点的指针
//【这样子如果我们后面还想用指向头节点的指针,phead就还是指向头节点】
SLTNode* pcur = phead;
// 遍历链表所有的节点
while (pcur)
{
if (pcur->data == x)
{
return pcur; // 返回pcur此时指向的节点
}
pcur = pcur->next; // 一次找不到就继续找下一个节点
}
// 走到这里说明没找到
return NULL;
}
查找的测试:
// 测试 查找
SLTNode* find = SLTFind(plist, 3);
if (find == NULL)
{
printf("没有找到\n");
}
else
{
printf("找到了");
}
链表的指定位置之前插入数据:
思路:
- 首先我们要遍历整个链表查看是否有pos这个位置的节点
- 让prev指向第一个节点,不停的向后查找,直至prev指向的节点所存储的指针指向的是pos位置的节点,这个时候就停下来
- 然后找到了pos位置之后 我们要申请一个新的节点newnode
- 然后再将新的节点的存储的指针指向pos位置的节点
- 然后再让pos前一个位置的指针prev节点中存储的指针去指向newnode
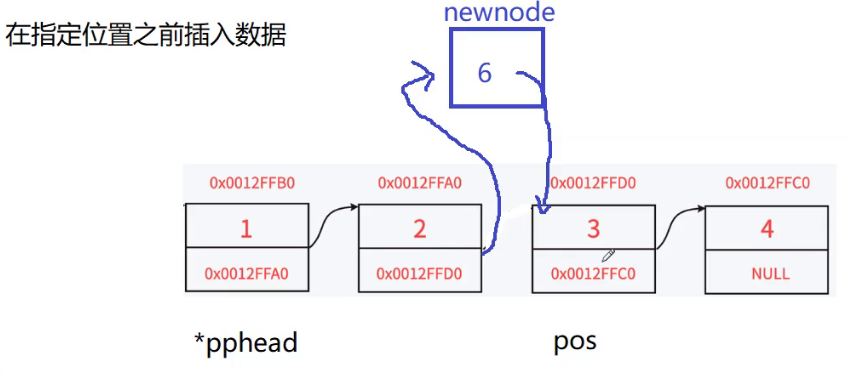
但是这里有一个问题:
- 那就是当pos == *pphead 的时候, 也就是头插的时候,这个时候prev和pos都指向 第一个节点
- 那我们再遍历链表的时候,prev直至找完整个链表都找不到pos位置的节点
- 这个时候我们就要分类讨论了
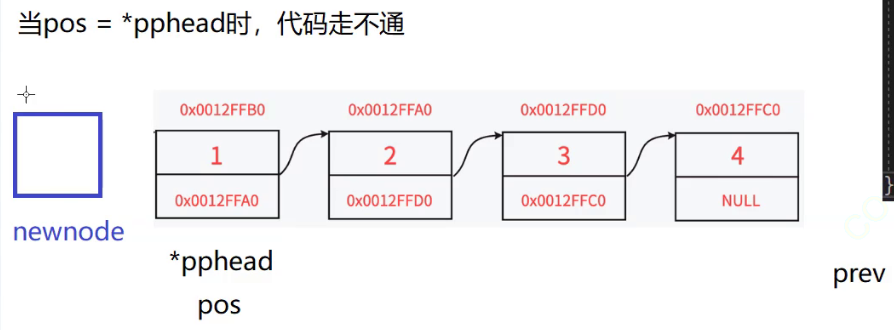
这个时候还有一个问题:
- 如果传进来的pos既不是NULL 也不是链表当中节点的地址
- 是一个不知道哪里的野指针,那我们要针对这个情况进行处理
- 不然代码就会陷入死循环无法逃脱
思路清晰了之后,我们就来看看代码是如何实现的:
// 在链表的指定位置之前插入节点
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x)
{
assert(pphead);
// 链表也不能为空 因为如果为空 都没有位置了,还怎么在指定位置之前插入节点
assert(*pphead);
// 你要所选择的位置也不能是NULL
assert(pos);
// 分类 讨论 头插和 其他情况
if (pos == *pphead) // 头插
{
SLTPushFront(pphead, x); // 引用头插函数
}
else // 其他情况
{
// 首先创建要插入的节点
SLTNode* newnode = SLTBuyNode(x);
// 接着我们需要 去遍历整个链表 去找到pos位置
SLTNode* prev = *pphead;
while (prev->next != pos)
{
if (prev->next == NULL)
{
printf("没有找到pos位置的节点!,请输入合法的pos值\n");
return;
}
prev = prev->next;
}
// 走到这里就是找到了pos位置的节点
// 这个时候我们就让三个节点手牵手 prev -> newnode -> pos
prev->next = newnode;
newnode->next = pos;
}
}
测试代码:
// 测试 查找
SLTNode* find = SLTFind(plist, 3); // find 就是查找函数返回的这个节点的地址
// 测试 在指定位置之前插入数据
//SLTInsert(&plist, plist, 0); // 相当于头插 也可以让find查找头节点 然后返回的就是头节点的地址
SLTInsert(&plist, find, 9);
//SLTInsert(&plist, 0x11111111, 9);
SLTPrint(plist);// 1->2->9->3->4->NULL
在链表的指定位置之后插入数据:
思路:
- 首先遍历整个链表找到pos指定的位置的节点
- 如果找到了就申请一个新的节点 出来
- 让pos位置的节点所存储的指针指向新的节点
- 再让新的节点存储的指针指向pos位置的下一个节点
- 完成三个节点的链接
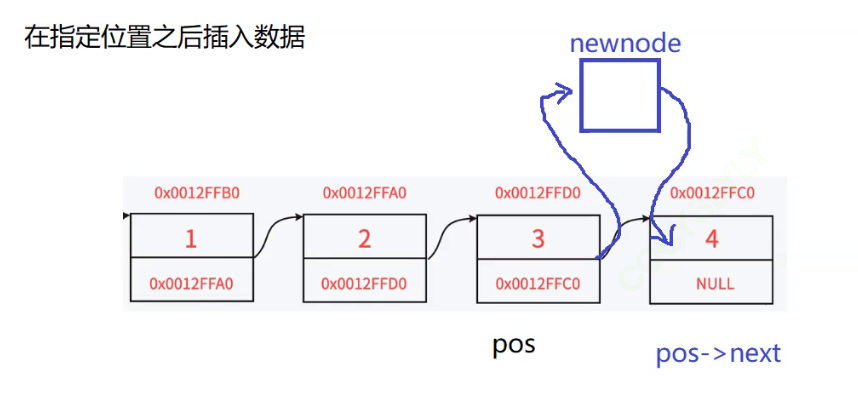
即便pos是在头节点,这个逻辑也是走的通过的,因为是在后面插入,不是在前面插入,因此我们不再需要把指向头节点的指针传给函数了
我们来看看代码是如何是实现的:
// 在链表指定位置之后插入数据
void SLTInsertAfter(SLTNode* pos, SLTDataType x)
{
assert(pos);
// 申请要出插入的节点
SLTNode* newnode = SLTBuyNode(x);
// 插入
newnode->next = pos->next;
pos->next = newnode; // 注意了这个代码不能和上面的代码顺序相反
}
测试代码:
// 测试 在在指定位置之后插入数据
// 1->2->9->3->4->NULL
SLTInsertAfter(plist, 11);// 在头节点之后插入数据 头插
SLTInsertAfter(find, 11); // 在尾节点之后插入数据 尾插
SLTPrint(plist);// 1->11->2->3->9->4->11->NULL
在链表的指定位置删除节点:
思路:
- 首先遍历整个链表找到pos节点
- 然后我们的目标是删除pos节点 并将prev节点和pos->next节点链接起来
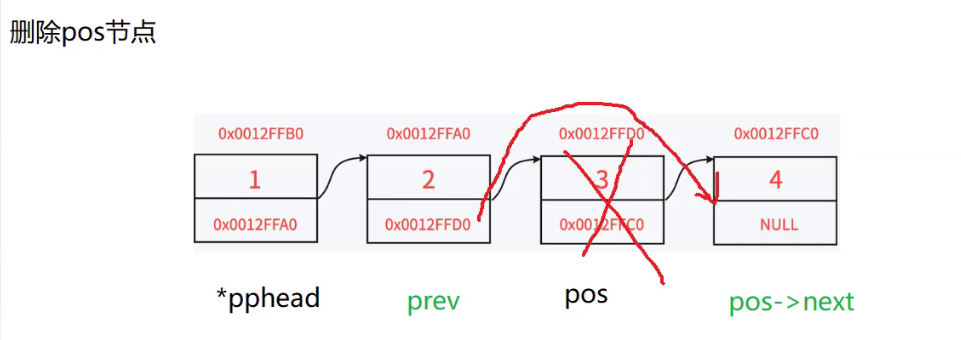
那我们还得注意一个问题:
这个问题在我们之前也遇到过
那就是pos == *pphead的时候,prev找不到pos
这个时候就要分类讨论。我们来看看代码是怎么实现的:
//删除pos节点
void SLTErase(SLTNode** pphead, SLTNode* pos)
{
assert(pphead);
// 链表也不能为空
assert(*pphead);
// 你也不能传个空节点让我删除
assert(pos);
// 分类讨论, pos是头节点和pos不是头节点
if (pos == *pphead)
{
// 删除头节点
/*
*pphead = pos->next; // 让访问链表的指针指向新的头节点
free(pos);
pos = NULL;
*/
// 这里其实就是头删的操作,直接调用头删就行
SLTPopFront(pphead);
}
else
{
// 遍历链表找到pos节点
// 并用prev来找到pos节点的前一个节点
SLTNode* prev = *pphead;
while (prev->next != pos)
{
if (prev->next == NULL)
{
printf("没找到pos节点,请输入合法的pos\n");
return;
}
prev = prev->next;
}
// 走到这里说明找到了
// 删除pos节点 并完成链接
prev->next = pos->next;
free(pos); // 要放到上面代码的后面,不然pos节点存储的数据和指针会丢失
pos = NULL;
}
}
测试代码:
// 测试 删除pos位置节点
// 1->2->3->9->4->11->NULL
find = SLTFind(plist, 11);
SLTErase(&plist, plist); //头删
SLTErase(&plist, find); // 尾删
SLTPrint(plist);// 2->3->9->4->NULL
删除链表指定位置之后的节点:
思路:
- 首先遍历链表找到pos节点
- 然后我们要找到pos下下个节点
- 并完成链接和删除pos节点
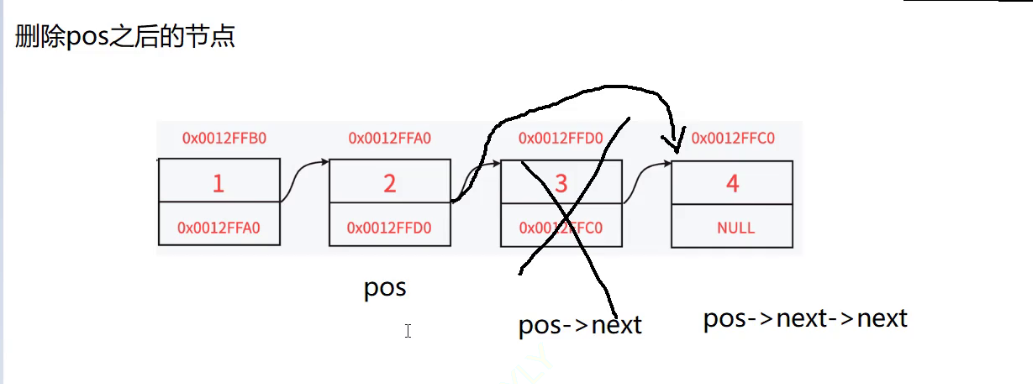
这里的思路即便是pos == *pphead的时候也是走的通的
无需分类讨论
我们来看代码如何实现:
//删除pos之后的节点
void SLTEraseAfter(SLTNode* pos)
{
assert(pos);
// pos下一个节点也不能是空的 不然怎么删除
assert(pos->next);
// 开始删除
// 这样删除是错误的
/*pos->next = pos->next->next;
free(pos->next); // 此时释放掉的是pos节点的下下个节点
pos->next = NULL;*/
// 来看正确的代码
SLTNode* del = pos->next;
pos->next = del->next; // del->next == pos->next->next
free(del);
del = NULL;
// 下面这段代码 也可以实现删除pos之后的节点的功能
//SLTNode* next = pos->next->next;
//free(pos->next);
//pos->next = NULL;
//pos->next = next;
}
测试代码:
// 测试删除pos位置之后的节点
find = SLTFind(plist, 9);
SLTEraseAfter(plist);
SLTEraseAfter(find);
SLTPrint(plist); // 2->9->NULL
链表的销毁:
思路:
- 首先通过遍历链表 把每一个链表的节点都给删除
- 要注意先把下一个节点的地址存储起来,不然节点空间释放之后
- 在想去找到下一个节点的地址就找不到了
我们来看代码的实现:
//销毁链表
void SListDesTroy(SLTNode** pphead)
{
assert(pphead);
assert(*pphead);// 链表为空怎么销毁
// 开始销毁
SLTNode* pcur = *pphead;
SLTNode* next = NULL;
while (pcur)
{
next = pcur->next;
free(pcur);
pcur = next;
}
// pcur 此时为 NULL
*pphead = NULL;
}
我们来看测试代码:
//测试链表的销毁
SListDesTroy(&plist);
SLTPrint(plist);// NULL
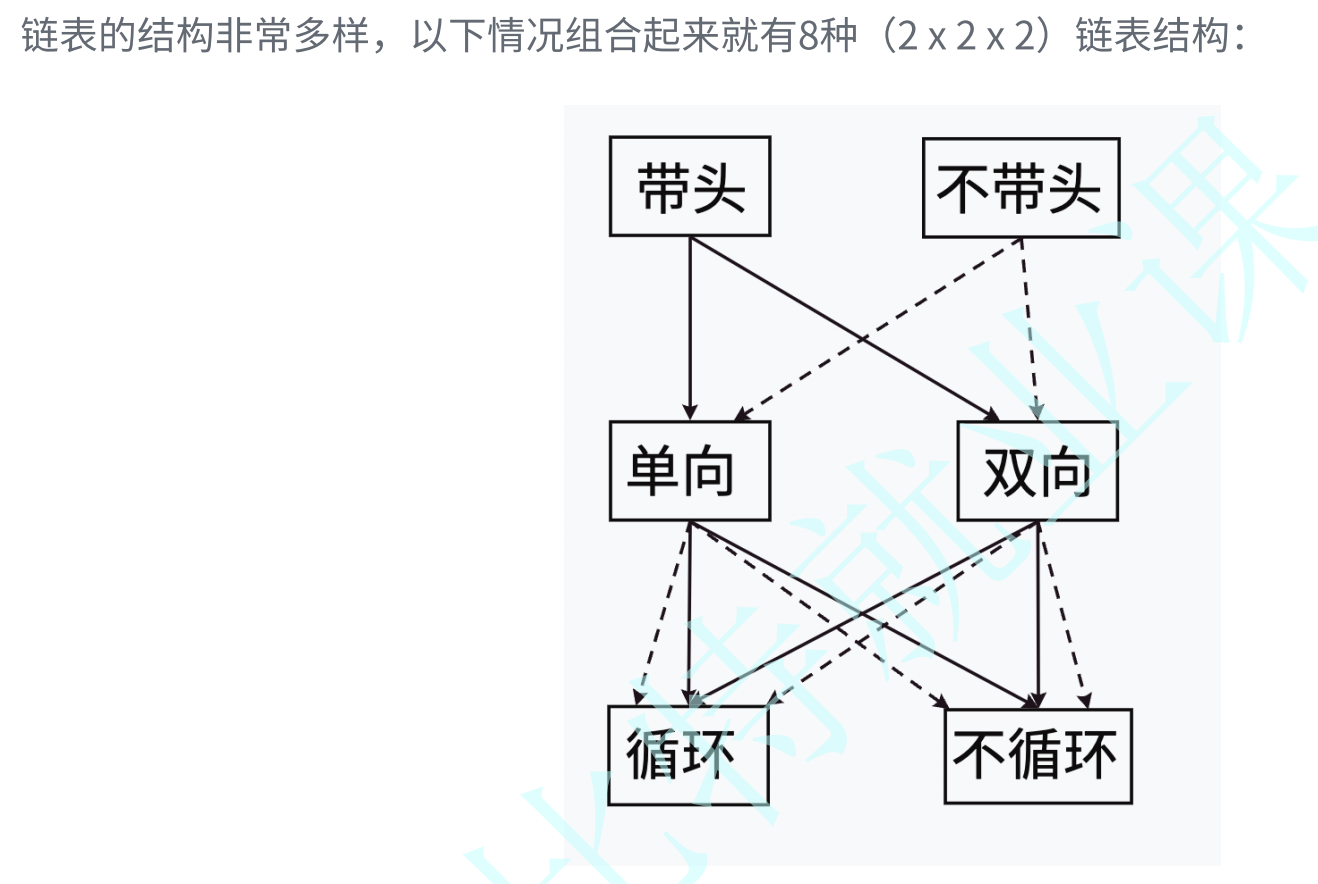
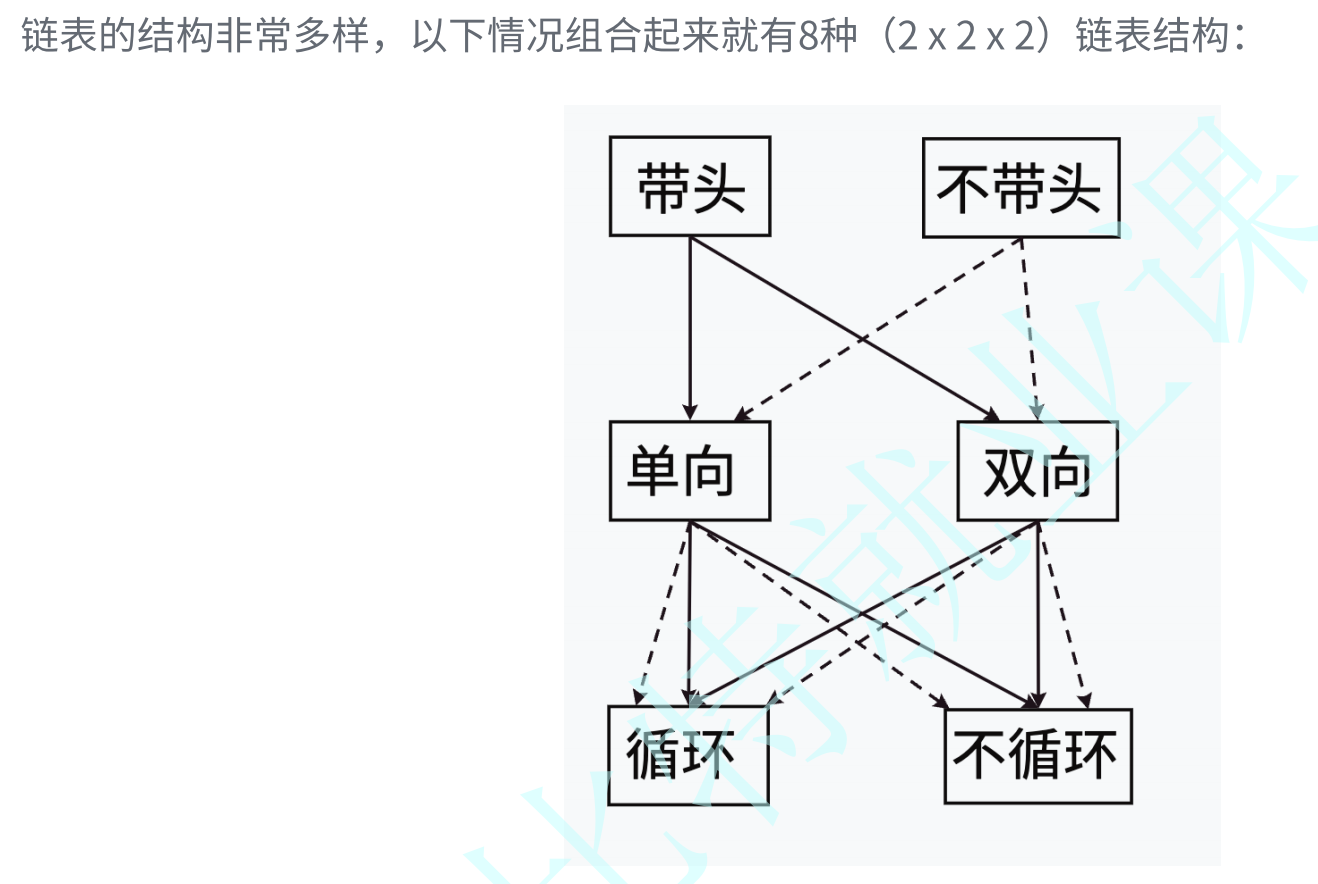
3.链表的分类
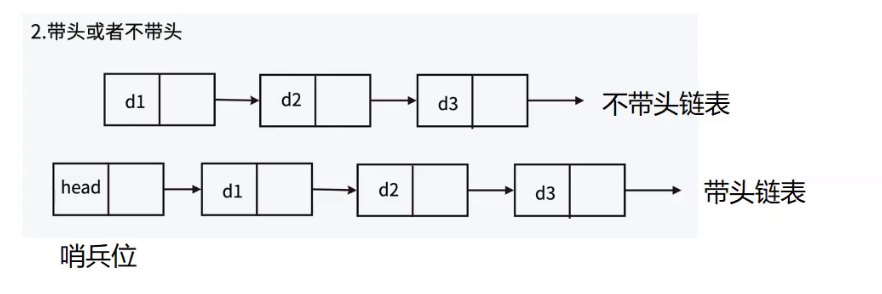
在前面实现链表中,口头上提到的头结点实际上指的是第一个有效节点,这不是正确的称呼~但是为了好理解才这样错误的称呼为头结点,实际在链表中,头结点指的是哨兵位!
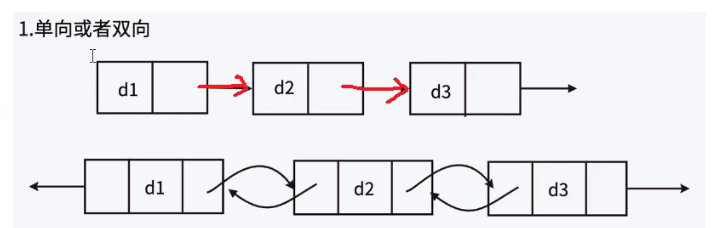
单向链表已经学习了,双向链表就是可以通过一个节点找到下一个节点,也可以找到上一个节点.
单向链表只能从单方向遍历
双线链表可以从两个方向遍历
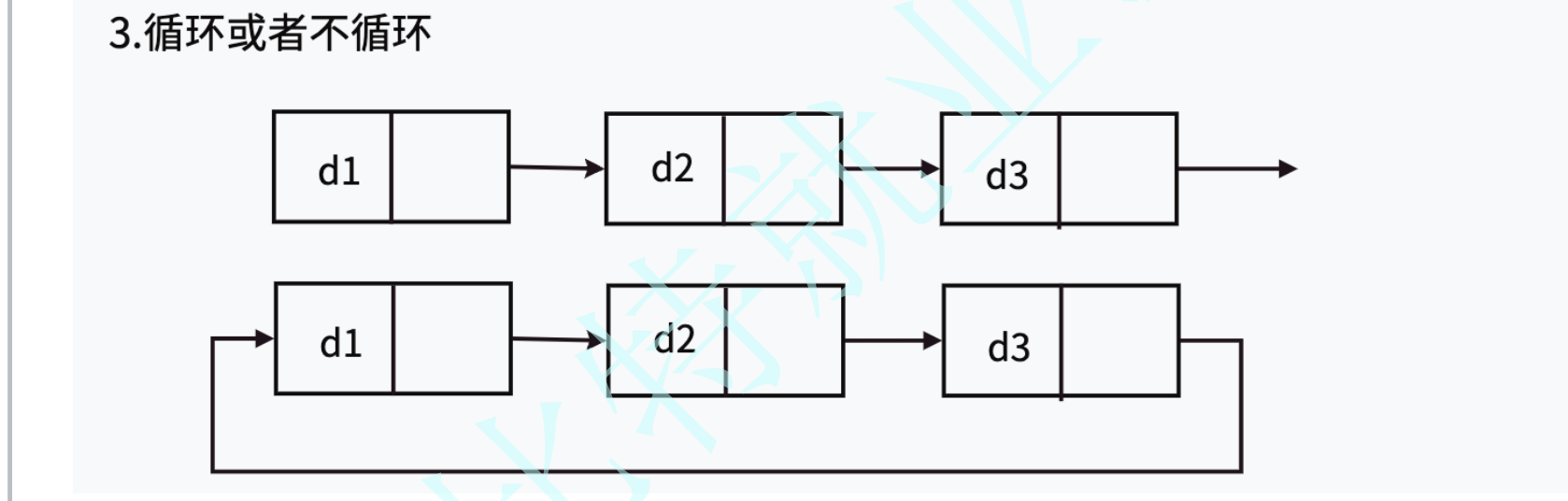
本章节我们学习的是: 不带头单项不循环链表
虽然有这么多的链表的结构,但是我们实际中最常⽤还是两种结构: 单链表 和 双向带头循环链表
- ⽆头单向⾮循环链表:结构简单,⼀般不会单独⽤来存数据。实际中更多是作为其他数据结
构的⼦结构,如哈希桶、图的邻接表等等。另外这种结构在笔试⾯试中出现很多。
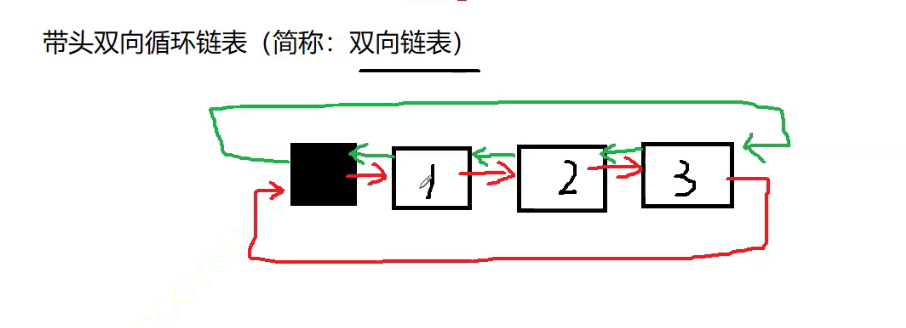
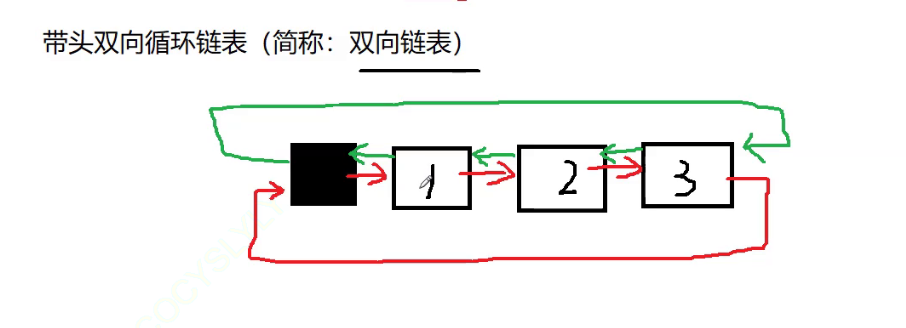
- 带头双向循环链表:结构最复杂,⼀般⽤在单独存储数据。实际中使⽤的链表数据结构,都是带头双向循环链表。另外这个结构虽然结构复杂,但是使⽤代码实现以后会发现结构会带来很多优势,实现反⽽简单了,后⾯我们代码实现了就知道了。
看测试代码:**
//测试链表的销毁
SListDesTroy(&plist);
SLTPrint(plist);// NULL
3.链表的分类
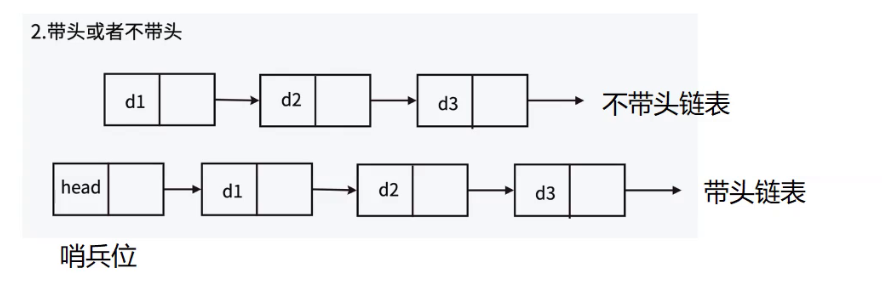
在前面实现链表中,口头上提到的头结点实际上指的是第一个有效节点,这不是正确的称呼~但是为了好理解才这样错误的称呼为头结点,实际在链表中,头结点指的是哨兵位!
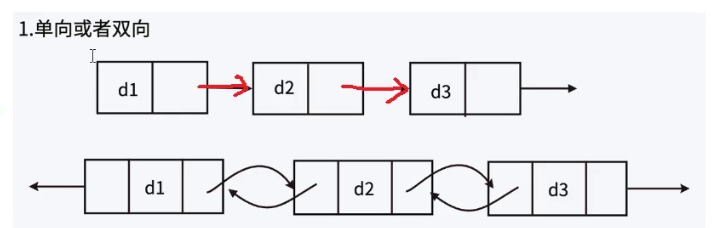
单向链表已经学习了,双向链表就是可以通过一个节点找到下一个节点,也可以找到上一个节点.
单向链表只能从单方向遍历
双线链表可以从两个方向遍历
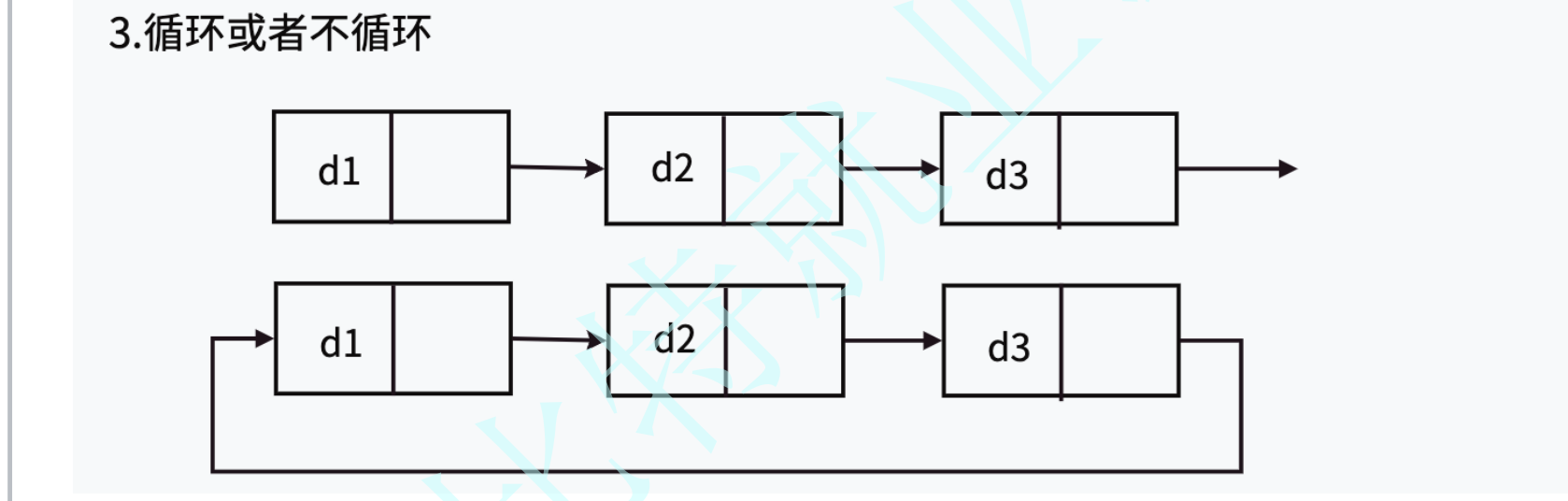
本章节我们学习的是: 不带头单项不循环链表
虽然有这么多的链表的结构,但是我们实际中最常⽤还是两种结构: 单链表 和 双向带头循环链表
- ⽆头单向⾮循环链表:结构简单,⼀般不会单独⽤来存数据。实际中更多是作为其他数据结
构的⼦结构,如哈希桶、图的邻接表等等。另外这种结构在笔试⾯试中出现很多。
- 带头双向循环链表:结构最复杂,⼀般⽤在单独存储数据。实际中使⽤的链表数据结构,都是带头双向循环链表。另外这个结构虽然结构复杂,但是使⽤代码实现以后会发现结构会带来很多优势,实现反⽽简单了,后⾯我们代码实现了就知道了。















 758
758

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









