







STL—vector—模拟实现
经过了前面对于vector的初步了解,我们已经具备了使用vector的能力了,现在我们就来深度学习一下vector,并做到能模拟实现vector的基础功能。
1.vector深度解析
要想深度了解vector,我们就要去看它的源代码。
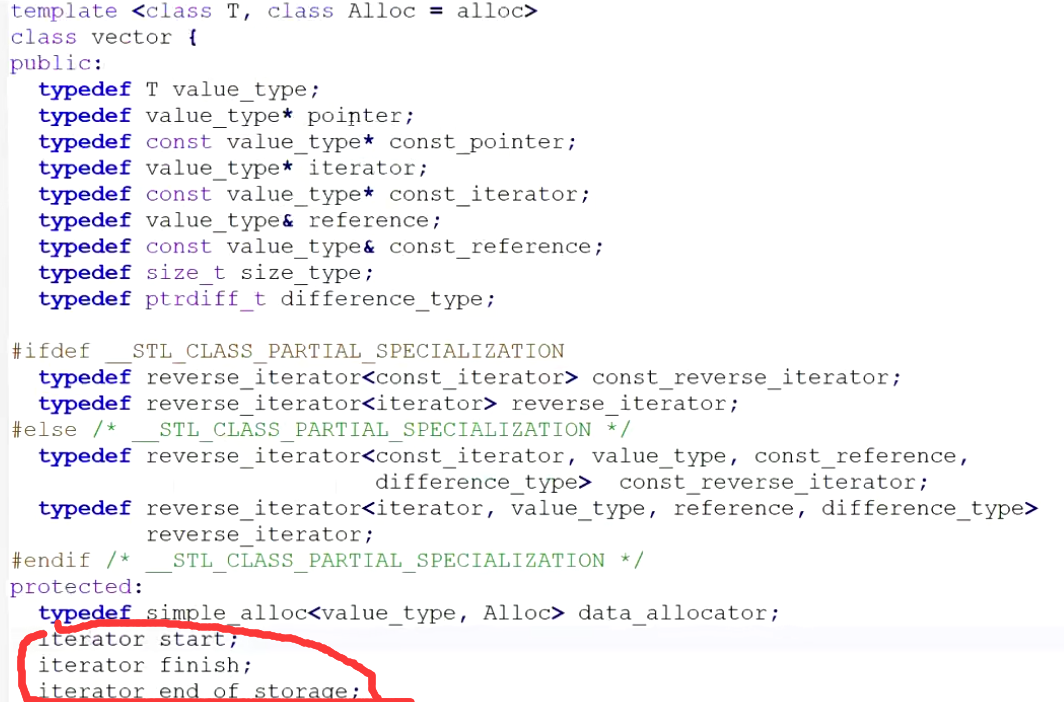
我们可以看到,它的成员变量给的是start finish storage而不是我们之前接触的,_a _size _capacity

其实这只是换汤不换药而已,源代码中的iterator就是typedef之前的value_type*,而value_type*就是T的typedef。因此,唯一有变化的就是start finish storage都是T*指针,但是这也没什么不一样,我们来看一个图片。

start指向第一个位置,finish指向最后一个位置的下一个位置。end_of_storage指向的位置就是start+capacity的位置并且start+size就是finish所指向的位置
因此后面对vector的模拟实现我们会尽量向源代码中的vector模拟实现
2.vector的模拟实现
跟string类的模拟实现相似,为了避免和库中的vector有冲突,我们要开个自己的命名空间,名字随意
namespace wzf
{
template<class T>
class vector
{
public:
typedef T* iterator;
private:
// 成员变量
iterator _start;
iterator _finish;
iterator _end_of_storge;
};
}
vector需要加模版template<class T>根据T的类型去开辟对应的T*空间
这部分的知识可以回顾初阶模版那块模版初阶【泛型编程】【函数模版】【类模版】-CSDN博客
2.1迭代器
在vector中,迭代器就是其原生指针
iterator begin()
{
return _start;
}
iterator end()
{
return _finish;
}
- 带const的迭代器
需要在前面加上typedef const T* const_iterator;
const_iterator begin() const
{
return _start;
}
const_iterator end() const
{
return _finish;
}
2.2构造函数
- 无参构造函数
vector() // 无参构造函数
:_start(nullptr)
,_finish(nullptr)
,_end_of_storge(nullptr)
{}
- 带参构造函数
vector(size_t n, const T& val = T()) // 开辟n个空间并都填充val
:_start(nullptr)
,_finish(nullptr)
,_end_of_storge(nullptr)
{
reserve(n);
while (n--)
{
push_back(val);
}
}
- 迭代器做形参的构造函数
若使用iterator做迭代器,会导致初始化的迭代器区间[first,last)只能是vector的迭代器
vector(iterator first, iterator last)
{
while (first != last)
{
push_back(*first);
++first;
}
}
测试代码:
void test9()
{
// 测试两个特殊的构造函数
wzf::vector<int> v(2, 10);
print_vector(v);
wzf::vector<int> v1(v.begin(), v.end());
print_vector(v1);
wzf::vector<string> s;
s.push_back("111");
s.push_back("222");
wzf::vector<string> s1(s.begin(), s.end());
for (auto e : s1)
{
cout << e << " ";
}
cout << endl;
}
2.3拷贝构造
和string一样,vector的拷贝构造也涉及到深浅拷贝的问题。
在执行拷贝构造和赋值运算符重载等接口的时候,要用深拷贝。不用深拷贝会导致浅拷贝问题,程序会崩溃,因为会对同一个地址连续释放两次空间。具体解析可以复习之前的博客STL—string类—模拟实现-CSDN博客
深拷贝的流程就是,开辟新空间,数据拷贝到新空间
第一种写法:
vector(const vector<T>& v) // 拷贝构造
{
size_t n = v.capacity();
size_t sz = v.size();
T* tmp = new T[n];
if (v._start) // memcpy函数v._start不能为空
{
memcpy(tmp, v._start, sizeof(T) * sz);
}
_start = tmp;
_finish = _start + sz;
_end_of_storge = _start + n;
}
第二种写法:
这个写法复用了我们后面实现的接口。
思路就是一开始就对自身初始化,然后把你的数据插入到我身上来。
vector(const vector<T>& v)
:_start(nullptr)
,_finish(nullptr)
,_end_of_storge(nullptr)
{
reserve(v.capacity()); // 避免在push_back中频繁的增容
for (const auto& e : v)
{
push_back(e);
}
}
测试代码:
void print_vector(const wzf::vector<int>& v)
{
wzf::vector<int>::const_iterator cit = v.begin();
// 这里的v.begin()调用的是const的迭代器,因为v是带const的
while (cit != v.end())
{
cout << *cit << " ";
cit++;
}
cout << endl;
}
void test6()
{
// 测试拷贝构造
wzf::vector<int> v1;
v1.push_back(1);
v1.push_back(1);
wzf::vector<int> v2(v1);
print_vector(v2); // 1 1
}
2.4析构函数
~vector()
{
delete[] _start;
_start = nullptr;
_finish = nullptr;
_end_of_storge = nullptr;
}
2.5size()
由之前vector的深度解析我们可以知道size(),即有效元素个数,就是_finish - _start
size_t size() const
{
return _finish - _start;
}
2.6capacity()
这个也是同理,用_end_of_storge - _start即可得到空间容量
size_t capacity() const
{
return _end_of_storge - _start;
}
2.7[]重载
_start本身就是一个T*,返回_start[i]即可
T& operator[](size_t i)
{
assert(i >= 0 && i < size());
return _start[i]; // *(_start + i)也可以
}
还要提供一个带const[]的重载,这样才能给带const的vector对象提供[]接口。这里不能只有一个带const的[],因为[]要支持可读可写,需要有可以写的情况,但是size()和capacity()不一样,这个只需要一个带const的接口即可,因为不是带const的vector对象也可以调用它【涉及权限的放大和缩小问题】,并且这两个函数不需要再内部对vector对象进行修改。
const T& operator[](size_t i) const
{
assert(i >= 0 && i < size());
return _start[i]; // *(_start + i)也可以
}
2.8赋值运算符重载
赋值运算符重载也涉及到深浅拷贝,要用深拷贝——开新空间,拷贝数据到新空间,释放旧空间
// 赋值运算符重载
vector<T>& operator=(const vector<T>& v)
{
if (this != &v) // 判断是否是自己给自己赋值
{
delete[] _start; // 把之前的空间释放掉
size_t n = v.capacity();
size_t sz = v.size();
_start = new T[n]; // 开辟新空间
// 拷贝数据
memcpy(_start, v._start, sizeof(T) * sz);
//更新对应的成员变量
_finish = _start + sz;
_end_of_storge = _start + n;
}
return *this;
}
当然,如果觉得代码不够简洁,我们还可以用现代写法
// 赋值运算符重载——现代写法
vector<T>& operator=(vector<T> v)
{
//v由于拷贝构造,已经是我们要想的对象了。直接交换就行了
swap(_start, v._start);
swap(_finish, v._finish);
swap(_end_of_storge, v._end_of_storge);
return *this;
}
要注意:实现现代写法的前提是拷贝构造没有问题,v是通过拷贝构造去复制一个实参的。
但这里还有一点问题,那就是我们这里是调用的库里的swap函数,这样代价会相对大一些,因为库里的swap是通过三个深拷贝实现的。因为他会构造vector<int>这种自定义对象,交换时还会创造临时对象完成深拷贝。

因此我们最好自己实现一个swap接口,通过调用自己的swap接口去实现=的重载。
swap接口在后面增删查改的接口中有实现
// 赋值运算符重载——现代写法
vector<T>& operator=(vector<T> v)
{
//v由于拷贝构造,已经是我们要想的对象了。直接交换就行了
swap(v);
return *this;
}
测试代码:
void test7()
{
// 赋值运算符重载的测试
wzf::vector<int> v1;
v1.push_back(5);
wzf::vector<int> v2;
v2.push_back(1);
v2.push_back(1);
v1 = v2;
print_vector(v1); // 1 1
}
增删查改类的接口
1.reserve()
n要大于当前容量才做处理,小于n不做处理。这里的做法是传统做法,即reserve这个函数自己去开空间,拷贝数据到新空间,释放旧空间。
void reserve(size_t n)
{
if (n > capacity())
{
T* tmp = new T[n];
size_t sz = size();// 原来的数据有多少必须提前算好
if (_start) // 判断_start是否为空
{
memcpy(tmp, _start, sizeof(T) * sz); // start为空,memcpy会报错
delete[] _start;
}
_start = tmp;
_finish = _start + sz;
_end_of_storge = _start + n;
}
}
这里要注意,上述这个reserve是有问题的,正确的代码如下:
至于代码为什么有问题,这个在后面的更深层次的深拷贝问题有讲解。上面这个reserve在因对T内置类型的时候是没有问题的。
void reserve(size_t n)
{
if (n > capacity())
{
T* tmp = new T[n];
size_t sz = size();// 原来的数据有多少必须提前算好
if (_start) // 判断_start是否为空
{
for (size_t i = 0; i < sz; i++)
{
tmp[i] = _start[i];// 不通过memcpy函数进行数据转移
}
delete[] _start;
}
_start = tmp;
_finish = _start + sz;
_end_of_storge = _start + n;
}
}
2.push_back()
在没有实现insert之前,我们用下面这个
void push_back(const T& x) // 插入的数据类型取决于T是什么类型
{
// 判断是否需要增容
if (_finish == _end_of_storge)
{
// 判断该vector的空间是否是0
size_t newcapacity = capacity() == 0 ? 2 : capacity() * 2;
reserve(newcapacity);
}
// 空间足够就插入
*_finish = x;
_finish++;
}
实现了insert之后,我们知道insert的其中一个功能就是尾插。
那我们可以考虑直接函数复用了、
void push_back(const T& x) // 插入的数据类型取决于T是什么类型
{
insert(_finish, x);
}
3.pop_back()
这个就非常简单了,让_finish–即可
void pop_back()
{
assert(_start < _finish);
--_finish;
}
如果实现了erase,可以考虑函数复用
void pop_back()
{
assert(_start < _finish);
erase(_finish - 1);
}
4.insert()
insert就是在pos位置插入一个x元素。
- 首先就是判断pos是否合法
- 插入需要判断空间是否足够,不够就增容,增容要注意迭代器失效的问题
- 空间足够就插入,插入要注意数据是否会被覆盖。采用从后往前挪动数据
- 最后注意数据更新
void insert(iterator pos, const T& x)
{
// 判断pos位置是否合法
assert(pos <= _finish && pos >= _start);
// 判断空间是否足够
if (_finish == _end_of_storge)
{
size_t n = pos - _start; // 为了防止pos失效,我们要记载下pos到 _start的距离
size_t newcapacity = capacity() == 0 ? 2 : capacity() * 2;
reserve(newcapacity);
pos = _start + n; // 这里的_start是扩容后,新的位置的_start
}
// pos后的数据整体向后挪动一位
iterator end = _finish - 1;
while (end >= pos)
{
*(end + 1) = *end;
end--;
}
*pos = x;
++_finish;
}
5.erase()
erase就是在pos位置下删除一个元素
- 要注意pos位置是否合法
- 删除元素就是让pos位置之后的数据整体向前移动就行
- 为了防止迭代器失效的问题,erase的返回值是被删除的元素的下一个有效元素的迭代器
iterator erase(iterator pos)
{
assert(pos < _finish && pos >= _start);
// erase不需要判断空间是否足够
// 要把pos位置之后的位置往前面移动
iterator it = pos;
while (it != _finish)
{
*it = *(it + 1);
it++;
}
_finish--;
//此时的pos指向的是被删除元素的下一个元素
return pos;
}
6.resize()
void resize(size_t n, const T& val = T())
resize有三种情况
- 若n大于capacity 那么会增容并且将size()[有效元素的个数]之后的空间全部填充val
- 若n小于capacity但是大于size,那么就会把size到n之间的空间填充val
- 若n小于size,那么会直接将size减少到n。相当于删减
要注意val的缺省值不能直接像之前模拟实现string的resize一样,去给一个\0,这里不能给这种精确的类型的缺省值,因为你并不知道vector<T>中的T到底是什么类型,因此这里给个T类型的对应的缺省值T()
这里的这个T(),其实就是c++中的构造函数,就是一个类型的构造函数,没给参数调用的就是默认构造函数,都会有个缺省值、int等内置类型为了兼容c++,也是有了构造函数之类的用法
比如:
int i = int();
double db = double();
我们来看代码:
这个代码对三种情况分的很明白,但是有点重复和冗余。
void resize(size_t n, const T& val = T())
{
assert(n >= 0);
//对n的值进行判断,要分类讨论
if (n < size())
{
size_t time = size() - n;
for (size_t i = 0; i < time; i++)
{
_finish--;
}
}
else
{
if (n < capacity())
{
// 在size()~n之间要填充val
size_t time = n - size();
size_t begin = size();
for (size_t i = 0; i < time; i++)
{
_start[begin + i] = val;
}
// 更新_finish指针指向的地址
_finish += time;
}
else
{
// 先扩容
reserve(n);
// 在size()~capacity()之间填充val
size_t time = capacity() - size();
size_t begin = size();
for (size_t i = 0; i < time; i++)
{
_start[begin + i] = val;
}
// 更新_finish指针指向的地址
_finish += time;
}
}
}
我们再来优化后的代码:
void resize(size_t n, const T& val = T())
{
assert(n >= 0);
//对n的值进行判断,要分类讨论
if (n < size())
{
size_t time = size() - n;
for (size_t i = 0; i < time; i++)
{
_finish--;
}
}
else
{
if (n > capacity())
{
// 扩容
reserve(n);
}
// 只要n大于size(), 那就是在_finish ~ n之间填充val
while (_finish < _start + n)
{
*_finish = val;
_finish++;
}
}
}
注意:
这里一定要通过赋值_finish = val的形式去填充val,而不能通过memset等函数去处理。
因为memxxx之类的函数是按字节处理的,如果是char类型的数据,就没问题,因为char类型在c语言只占一个字节大小,但如果是int类型之类的,int类型一个对象是4个字节的大小,这就会导致出问题。
我们来看例子:
int arr2[5] = { 0 };
memset(arr2, 1, 20);// 20指的是20个字节
// 注意了memset函数在修改数据的时候是以字节为单位的 做不到以元素为单位 因此 这里让arr2里的五个元素都变成1是做不到的

resize的测试代码:
void test5()
{
// 测试resize
wzf::vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.resize(4);
cout << v.size() << endl; // 4
cout << v.capacity() << endl; // 4
print_vector(v); // 1 2 3 0
cout << endl << endl;
v.resize(5, 1);
cout << v.size() << endl; // 5
cout << v.capacity() << endl; // 5
print_vector(v); // 1 2 3 0 1
cout << endl << endl;
v.resize(8, 1);
cout << v.size() << endl; // 8
cout << v.capacity() << endl; // 8
print_vector(v); // 1 2 3 0 1 1 1 1
cout << endl << endl;
v.resize(10);
cout << v.size() << endl; // 10
cout << v.capacity() << endl; // 10
print_vector(v); // 1 2 3 0 1 1 1 1 0 0
cout << endl << endl;
v.resize(2);
cout << v.size() << endl; // 2
cout << v.capacity() << endl; // 10
print_vector(v); // 1 2
cout << endl << endl;
}
7.swap()
void swap(vector<T>& v)
{
::swap(_start, v._start);
::swap(_finish, v._finish);
::swap(_end_of_storge, v._end_of_storge);
}
3.更深层次的深拷贝问题
在上面我们模拟实现的vector中的reserve接口实际上是有问题的,并且问题出在memcpy上。
前面在实现resize接口的时候,我们说过mem***之类的函数都是逐个字节处理的。因此这就会出问题,我们来看看怎么出问题的。
先来看一段代码:
void test8()
{
wzf::vector<string> v;
v.push_back("111");
v.push_back("222");
v.push_back("333");
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
}
这个代码会崩溃,崩溃的现象根据编译器版本的不同会不太一样。
VS2022是在最后的析构函数崩溃
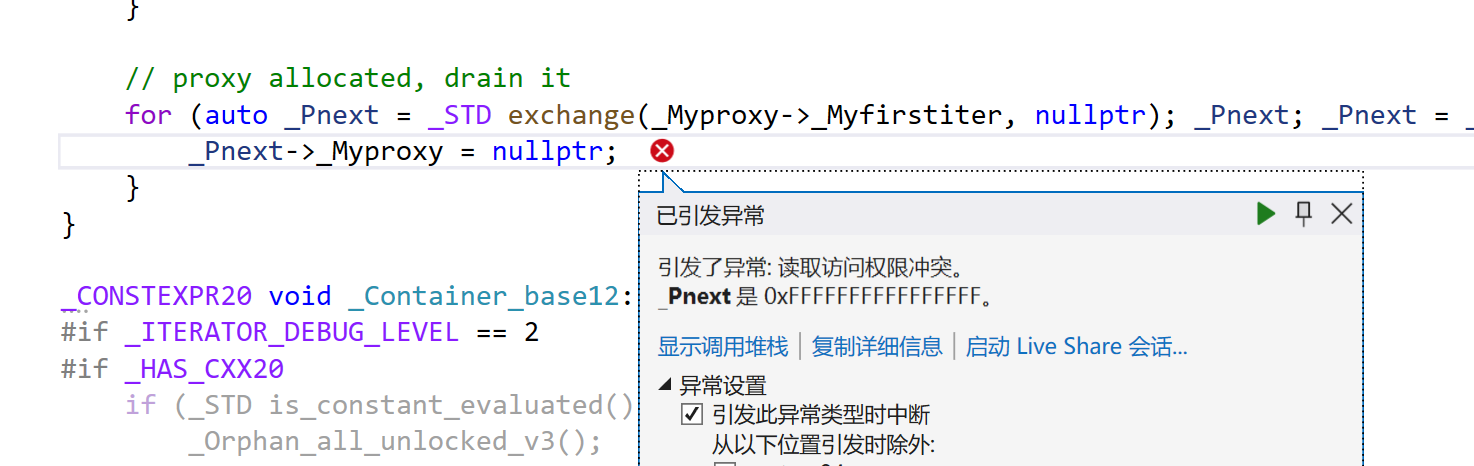
之前的版本是直接在reserve的delete[]就出现了问题

但是崩溃的原因都是同一个问题。
那为什么会崩溃呢?因为涉及到了增容操作,增容操作的memcpy是逐字节拷贝,造成了浅拷贝问题。
我们来详细分析一下。
首先这里的push_back是复用了insert函数的,insert函数中存在空间不够要扩容
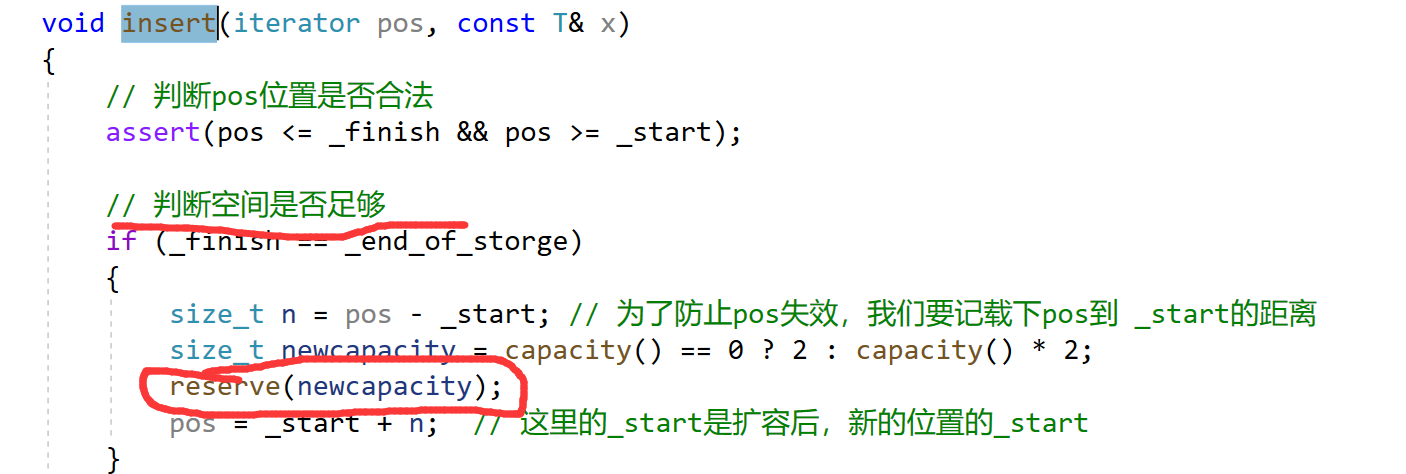
而扩容中的memcpy是将原来的_start上的数据逐个字节的拷贝到tmp上,这就导致了tmp上的string类的指针指向的是同一个空间的数据。而在析构函数的时候就会出问题。
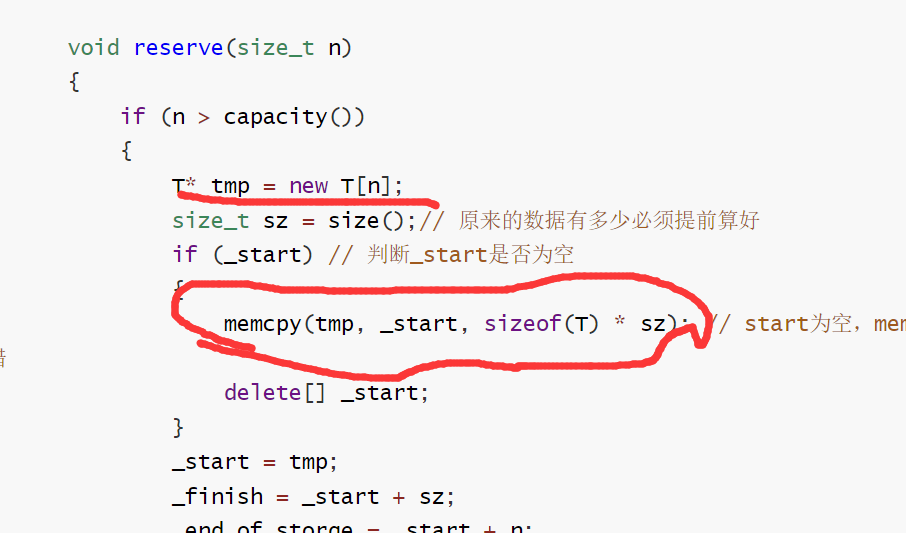
具体是这样的,tmp和每个元素都是一个string对象,string对象是从_start上的string对象通过memcpy逐字节拷贝过来的,就会导致str指针是一样的,这样两个指针都指向同一个数据,在析构的时候就会对同一个空间释放两次,因为string类的析构函数是需要释放空间的,而内置类型不用。
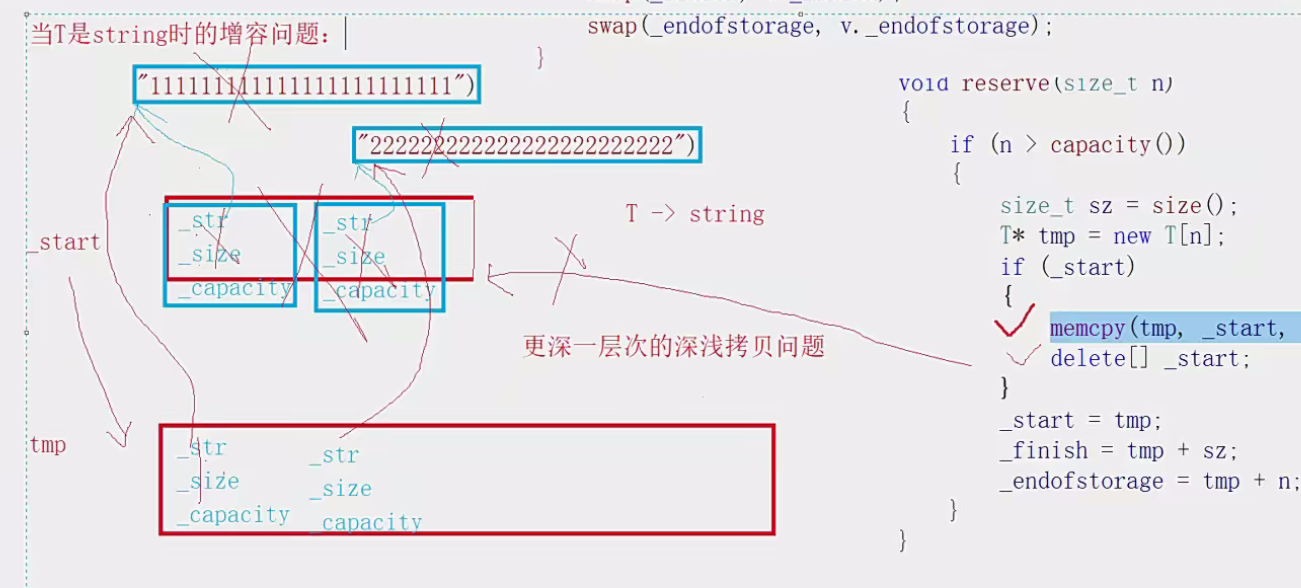
因此我们不能再使用memcpy函数去完成数据的拷贝,尽管它应对内置类型不存在问题,但是面对需要对空间资源进行管理的自定义类型,就会出现深浅拷贝问题。
因此我们需要对其进行修改,要进行深拷贝操作**,即不是单纯的拷贝,而是有自己独立的空间,将数据赋值到新空间上去**
很简单,代码修改如下:
void reserve(size_t n)
{
if (n > capacity())
{
T* tmp = new T[n];
size_t sz = size();// 原来的数据有多少必须提前算好
if (_start) // 判断_start是否为空
{
for (size_t i = 0; i < sz; i++)
{
tmp[i] = _start[i];// 不通过memcpy函数进行数据转移
}
delete[] _start;
}
_start = tmp;
_finish = _start + sz;
_end_of_storge = _start + n;
}
}
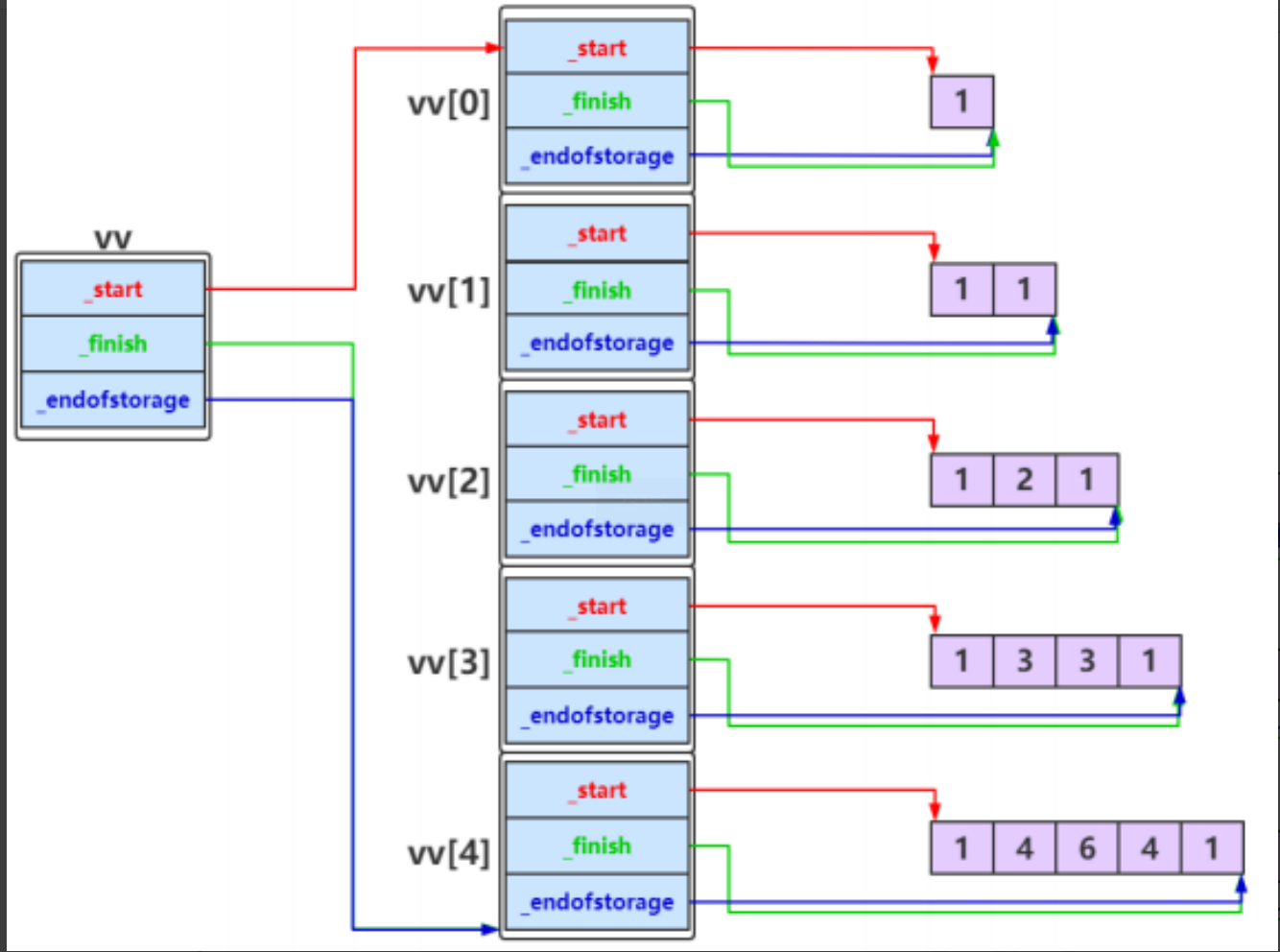
4.关于vector<vector<T>的理解
其实就是vector<T>中的T是vector<T>类型的,类似二维数组中每个元素都是一个一维数组一样。
可以根据下图更好的理解:
这个图片是关于vector<vector<int>的分析
5.vector的总结
下一个篇章要学习list。也就是之前数据结构学习的链表了,vector也就是顺序表,这两个数据结构的优缺点是面试会问的问题,我们需要能够总结上来
vector的缺点就是:
- 在中间和头部进行数据的插入或者删除的时候效率较低 O(N),因为是整体去挪动数据
- 在插入数据容量不够时,需要增容,增容要开辟空间,转移数据,释放旧空间。代价较大
vector的优点:
- 支持随机访问,vector中的任何一个元素都可以直接访问到,在查找数据的时候效率高,支持了二分查找/堆算法等算法
list(链表)的优点就是:
- 在插入数据的时候,不需要挪动数据,只需要新增一个节点就行,效率高,时间复杂度是O(1)
- list没有增容操作,是新增节点
list的缺点是:
- 不支持随机访问,list查询数据是遍历整个链表,直至找到,时间复杂度是O(N)
因此他两个相辅相成
















 2012
2012

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









