










来源书籍:
TENSORFLOW REINFORCEMENT LEARNING QUICK START GUIDE
《TensorFlow强化学习快速入门指南-使用Python动手搭建自学习的智能体》
著者:[美]考希克·巴拉克里希南(Kaushik Balakrishnan)
译者:赵卫东
出版社:Packt 机械工业出版社
1.深度Q网络
深度 Q 网络 (Deep Q-Networks, DQNs) 革新了强化学习领域。Google DeepMind 在 2014 年谷歌收购之前, 是一家名为 DeepMind Technologies 的英国公 司。DeepMind 在 2013 年发表了一篇论文,题目是用 Deep RL 玩 Atari 游戏,在强化学习的上下文中使用了 Deep Neural Networks (DNNs), 或者他们提到的 DQNs, 这是一个对该领域具有开创性意义的想法, 彻底改变了强化学习的研究领域。2015 年, 在 Nature 杂志上发表了第二篇论文, 题为 “通过 Deep RL 实现人类水平的控制 ( Human Level Control Through Deep RL)",这个想法更有趣,进一步改进了前一篇论文。这两篇论文共同推动了强化学习领域的发展, 一些新的算法改进了使用神经网络对,agent 的训练,也将强化学习应用于有趣的现实问题。
1.1学习DQN原理
本节研究DQN原理,包括其基础的数学知识,并学习使用神经网络来评估价值函数。
前文研究了 Q-Learning, 其中Q(s,a) 作为多维数组存储和计算, 每个状态 -动作对有一个条目。这对网格世界和悬崖徒步问题都很有效,这两个问题在状态空间和动作空间都是低维的。那么, 能把它应用到更高维的问题吗?答案是否定的,由于维度的限制、这使得存储大量的状态和动作变得不可能。此外, 在连续控制问题中,虽然可能存在无穷多个实数,但在有界的范围内,作用是以实数形式变化的,不能用表格式的 Q 数组表示。这就产生了强化学习中的函数逼近, 特别是 DNNs, 即 DQNs的使用。这里 Q(s,a) 表示为DNN, 它将输出 Q 的值。
DQN中包含的步骤如下:
1) 使用 Bellman 方程更新状态一动作价值函数,其中 (s,a) 是一次的状态和动作,s′ 和 a′ 分别是随后时间 t+1 的状态和动作, γ 是折扣系数:

2) 在回合步骤 中定义一个损失函数来训练 Q 网络:

前面的参数是以 θ 表示的神经网络参数, 因此 Q 值被写为 Q(s,a;θ) 。
3) 是迭代
的目标结果, 由以下方程给出:
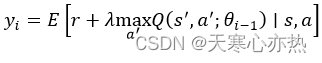
4)使用梯度下降、RMSprop 和 Adam等优化算法, 通过最小化损失函数 L(θ) ,在 DQN 上训练神经网络。
以前使用最小二次方误差作为 DQN 损失函数, 也称为 L2 损失。也可以考虑其他损失, 例如 Huber损失, 它结合了 L1 和 L2 损失, L2 损失在零附近, L1 损失在很远的区域。与 L2 损失相比, Huber 损失对异常值不太敏感。
下面介绍目标网络的使用。这是一个非常重要的概念, 需要稳定的训练。
1.2 理解目标网络
DQN的一个有趣的特性是在训练过程中利用第二个网络,成为目标网络。第二个网络用于生成 target- Q值, 该 target- Q 值用于在训练过程中计算损失函数。为 什么不使用一个网络来选择要采取的行动 a, 以及更新 Q 网络呢? 问题是, 在训练的每一步, Q 网络的值都会发生变化, 如果使用一组不断变化的值来更新网络, 那么估计值很容易变得不稳定一一网络会陷入目标值和估计 Q 值之间的反馈环。为了减轻这种不稳定性, 目标网络的权重是固定的, 也就是说, 缓慢地更新到主 Q 网络的值,这使训练更加稳定和实用。
而第二个神经网络,即目标网络,虽然神经网络参数值不同,但它在结构上与主 Q 网络相同。每 N 步一次, 参数从 Q 网络复制到目标网络, 使训练更加稳定。
例如, 可以使用 𝑁=10000 。另一种选择是缓慢更新目标网络的权重 (𝜃 是 Q 网络的权重, 是目标网络的权重):
![]()
这里, 𝜏 是一个很小的数, 例如 0.001 。后一种使用指数移动平均值的方法是 本书的首选。 下面介绍在异步策略算法中使用重放缓冲区的情况。
1.3 了解重放缓冲区
我们需要元组 (𝑠,𝑎,𝑟,𝑠′, done ) 来更新 DQN, 其中 𝑠 和 𝑎 分别是时间 𝑡 时的状态和行为; 𝑠′ 是时间 𝑡+1 时的新状态; done 是一个布尔值, 该值是 True 还 是 False 取决于事件是末完成还是已结束, 在文献中也称为终值。使用布尔 done 或 terminal 变量, 以便在 Bellman 更新中正确处理一个事件的最后一个终端状态 [ 因为不能对终端状态执行 𝑟+𝛾max𝑄(𝑠′,𝑎′) ]。DQNs 中的一个问题是使用 (𝑠,𝑎, 𝑟,𝑠′, done) 元组的连续样本, 它们是相关的, 因此训练可能会过拟合。
为了缓解这个问题,使用重放缓冲区,其中元组 (𝑠,𝑎,𝑟,𝑠′, done ) 存储于经验中, 并且从重放缓冲区中随机抽取一小批这样的经验样本用于训练。这样可以确保为每个小批量抽取的样本是独立同分布 (IID) 的。通常, 使用一个大容量的重放缓冲区, 例如 50 万到 100 万个样本。在训练开始时, 重放缓冲区被填充了足够数量的样本, 并填充新的经验。一旦将重放缓冲区填充到最大样本数, 旧的样本将被逐个丢弃。这是因为较旧的样本是由劣质策略生成的, agent 已经在学习中取得了进步,不希望在之后的阶段使用旧样本进行训练。
在最近的一篇论文中,DeepMind 提出了一个优先级重放缓冲区,其中时间差误差的绝对值用于赋予缓冲区中的样本重要性。误差较大的样本具有较高的优先级, 因此有更大的机会被采样。这种优先级重放缓冲区比普通重放缓冲区的学习速度更快。但是, 编写代码稍微困难一些, 因为它使用 SumTree 数据结构, 这是 一个二叉树, 其中每个父节点的值是其两个子节点的值之和。 优先级重放缓冲区基于 DeepMind 发表的论文: https://arxiv.org/abs/1511.05952
总结
本章介绍了第一个深度强化学习算法 DQN, 是当今较流行的强化学习算法之 一。同时学习了 DQN 背后的理论, 还研究了目标网络的概念和使用, 以稳定训练。目前发表的许多强化学习论文都将他们的算法应用于 Atari 的游戏中, 并报告了它们的回合奖励, 将它们与使用其他算法研究人员报告的相应值进行了比较。因此, Atari 环境是训练 RL agent 并进行比较以确定算法鲁棒性的一组自然的博亦。还研究了重放缓冲区的使用, 并了解了为什么在非策略算法中使用重放缓冲区。本章为深人研究深度强化学习奠定了基础。在下一章中, 我们将研究其他 DQN 扩展,例如 DDQN、竞争网络结构和 Rainbow 网络。
思考题
①为什么在DQN中使用重放缓冲区?
答:在DQN中使用重放缓冲区存储过去的经验,从中抽取一小批数据,并使用它来训练agent。
②为什么要使用目标网络?
答:目标网络有助于保持训练的稳定性。这是通过额外的神经网络来实现的,该神经网络的权重使用主神经网络权重的指数移动平均值来更新。另一种常用的方法是每几千步就将主神经网络的权重复制到目标网络一次。
③为什么将四个帧堆叠成一个状态?一帧就足以代表一种状态吗?
答:状态的一帧对 Atari Breakout 问题没有帮助。这是因为时态信息不能只从一帧中获得。例如,仅在一帧中不能获得球的运动方向,但是如果叠加多个帧,则可以确定球的速度和加速度。
④为什么有时需要 Huber 损失而不是 L2 损失?
答:由于L2损失过度拟合异常值。因此,Huber 损失是首选,因为它结合了L2和L1损耗。可以参考以下链接:https://en.wikipedia.org/wiki/Huber_loss
⑤将RGB输入图像装换为灰度,可以改为使用RGB图像作为网络的输入吗?使用RGB图像而不是灰度图像的利弊是什么?
答:也可以使用RGB图像。但是,需要为神经网络的第一个隐藏层增加额外的权重,因为现在状态堆栈中的四个帧中,每个帧都有三个通道。Atari 不需要这么精细的状态空间细节。然而,RGB图像可以在其他应用中发挥作用,例如自动驾驶或机器人。
















 448
448











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











