







Q-learning作为典型的value-based algorithm,训练出来的是critic(并不直接采取行为,评价现在的行为有多好),因此提出了state value function的概念,方便对每个状态进行评估
Policy-based是不断的增加reward高的行为发生的概率,而Q-learning是不断的寻找新的actor使得V增大,具体的分类见deeprl 基础
Q-learning要解决的最首要问题是如何估计state value function
如何估计每个状态的Value
目前主流有两种方法
MC:蒙特卡洛
完整的玩完一整局的游戏,然后对期间出现过的状态进行统计,从该状态开始计算在之后的所有时间里获得的reward,就是他的value 
缺点:必须将一个episode玩完才能得到结果,如果游戏非常长则不能得到多少有效数据。而且,采样不是无穷多的,很可能一些重要样本没采到,那么训练损失会很大。
TD:Temporal-difference (TD) approach
迅速更新value-function,无需等待整局游戏的结束,但是在state
s
t
s_t
st出现的时候,要估计在这之后他会获得的reward,因此可能会不准确。

compare MC VS TD

知道了如何估计value-function,现在可以正式介绍何为Q-function
Q-function
通常情况下,输入一个状态state,一个action,Q-function将他们映射到一个值上,表示当前情况的value
Q:在state s这里采取的action不一定就是a,但是我们强制采取action a得到的然后让他自由的玩下去看他会得到多少reward。
有两种写法
(1)左侧是标准写法输入s,a预测Q值
(2)右侧对于discrete action才能用,输出一堆值对应着每个可能的action。
Q-learning

其实并不存在新的π’,这个π’只是通过argmax运算Q-value得出来的一系列action组成的π。即有Q就能找到π’。而且理论上,一定可以找到找到一个新的π’,这个π’一定比原来的π更好 。
Tips 1:target network
本来是一个network,左侧的network参数变化,右侧网络参数同样会变化,这种target变化的情况不好训练,因此将右侧的网络进行固定。将左侧网络训练N次之后,再更新右侧的网络参数。也就是不要他们一起动。(一开始两个network其实是一样的)

Tip2:Exploration

利用这个action更新公式会有一个问题,一开始全都没有sample,Q值都是0,这时sample到了a2,之后a2会被一直select,其他的没有任何的机会。这时候用policy-gradient就没法更新,根本没有搜集到有效的数据。

sample到的数据多了后,actor就越来越有把握,也就可以变小(noise on action),这是一种随机的乱试,不是完全按照Q-function一直进行的,比较奇怪。

在一个episode的开始加上noise,中间保持不变,(noise on parameters),系统的进行尝试,explore in a consistant way
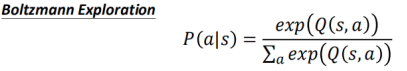
有点像policy-gradient,越厉害的action几率越高,Q-value有正有负,即使很差的我们也给他一个几率。保证采样比较全面
3.Tip3:Replay Buffer

1、不断的与环境进行互动,将经验存在buffer中,一般buffer会比一个episode中产生的所有数据大很多,也就是存着很多组数据。满的时候丢弃旧的。
2、在每一个interation中,sample很多data(包括很多过去的资料),更新Q。
3、(1)RL最费时的是与环境做互动,train的速度很快,这样可以将历史数据进行多次利用。(2)我们希望用来训练的数据diverse,而很和数据就很diverse。
4、问题:当前的π和历史的π显然都不一样,用历史数据训练当前数据?
是可以的,experience只是搜寻了某个场景采取的动作会收获的奖励,并不涉及具体的π,因此不必要和π保持统一,可以用来训练。
Algorithm
















 3964
3964











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









