






说明
本人不是什么爬虫大佬,只是最近在做一个项目的时候需要根据企业的名称把企业的信息爬取下来,例如营业执照、工商注册号等。在网上找了很多的信息与资源,都不是很符合我们的需求,是一种比较低频的爬虫需求,最开始是在企查查上面做的爬虫,但是这个平台经常需要登录,造成我们经常访问失败(其实也是楼主不会在爬虫的时候绕过登录😂)。
后来就在百度的爱企查平台进行爬虫,毕竟大平台,对我们这种低频的爬虫容忍很大,目前为止没有产生需要登陆的情况。刚开始参考了一篇CSDN博客,
这篇文章爬取到的是搜索到的企业列表,获取到的是列表里面的一些简单信息,并不能获取到企业的更详细的信息,例如工商注册号等,后来自己在这个基础上进行了改进,可以爬取到所有的信息了
以苏宁为例,文章爬取的列表信息:
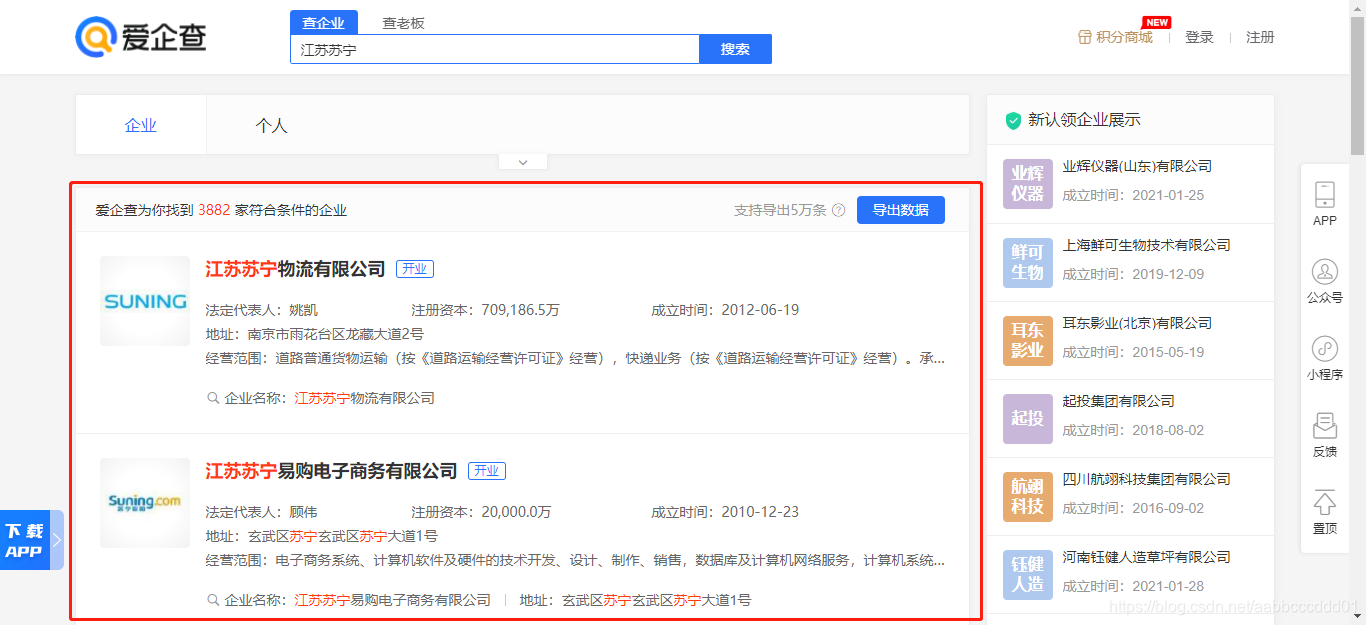
点进列表的第一条之后获取到的详细信息:
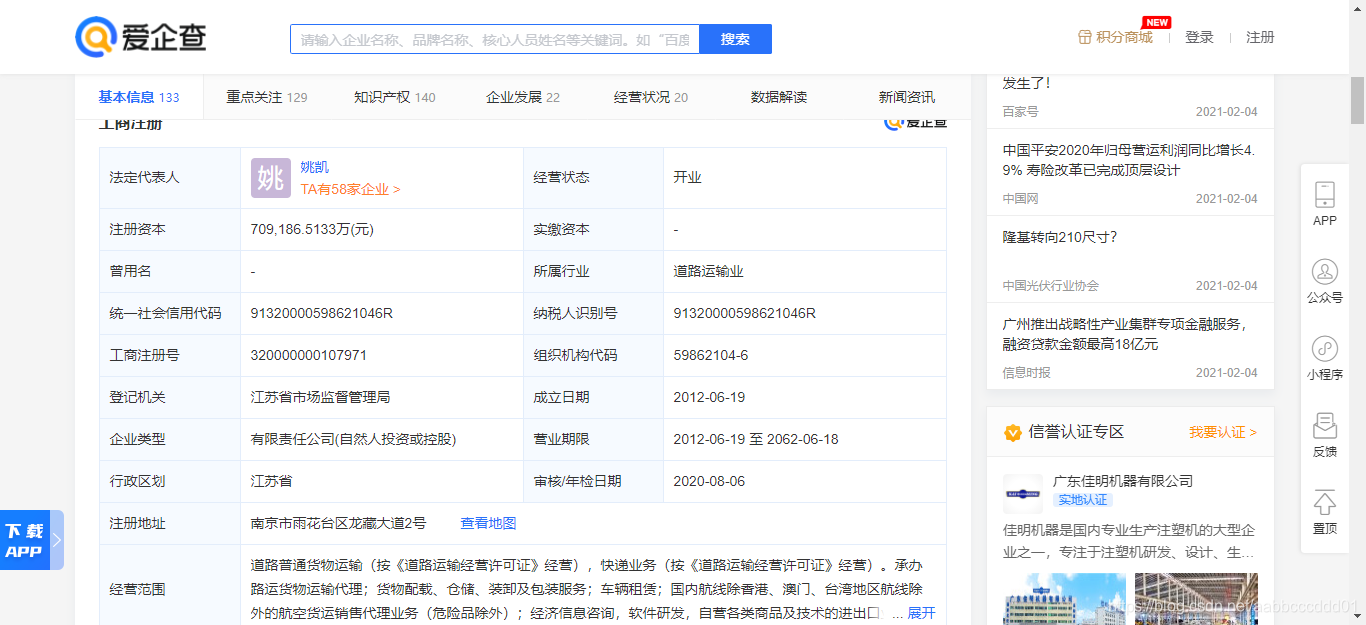
而我们需要的也是工商注册这一块的详细信息,下面讲解怎么获取到这些信息。
企查查网页构成方式
网页链接方式:
大家可以去查看一下上面csdn博客的内容,公司的列表信息里每一项都带着一个pid参数,表示当前公司的访问id
https://aiqicha.baidu.com/company_detail_65922533325239
后面的65922533325239就是搜索列表第一条所对应的访问链接。通过这样的方式构建链接查看企业信息详情。
打开页面之后,我们可以看到在谷歌浏览器的源码页面对应的信息是查看不到的,也就是说网页时通过js动态生成的,网页源码里不包含界面的主要信息,因此通过简单的解析源码不能获取得到数据。
网页sources源码:
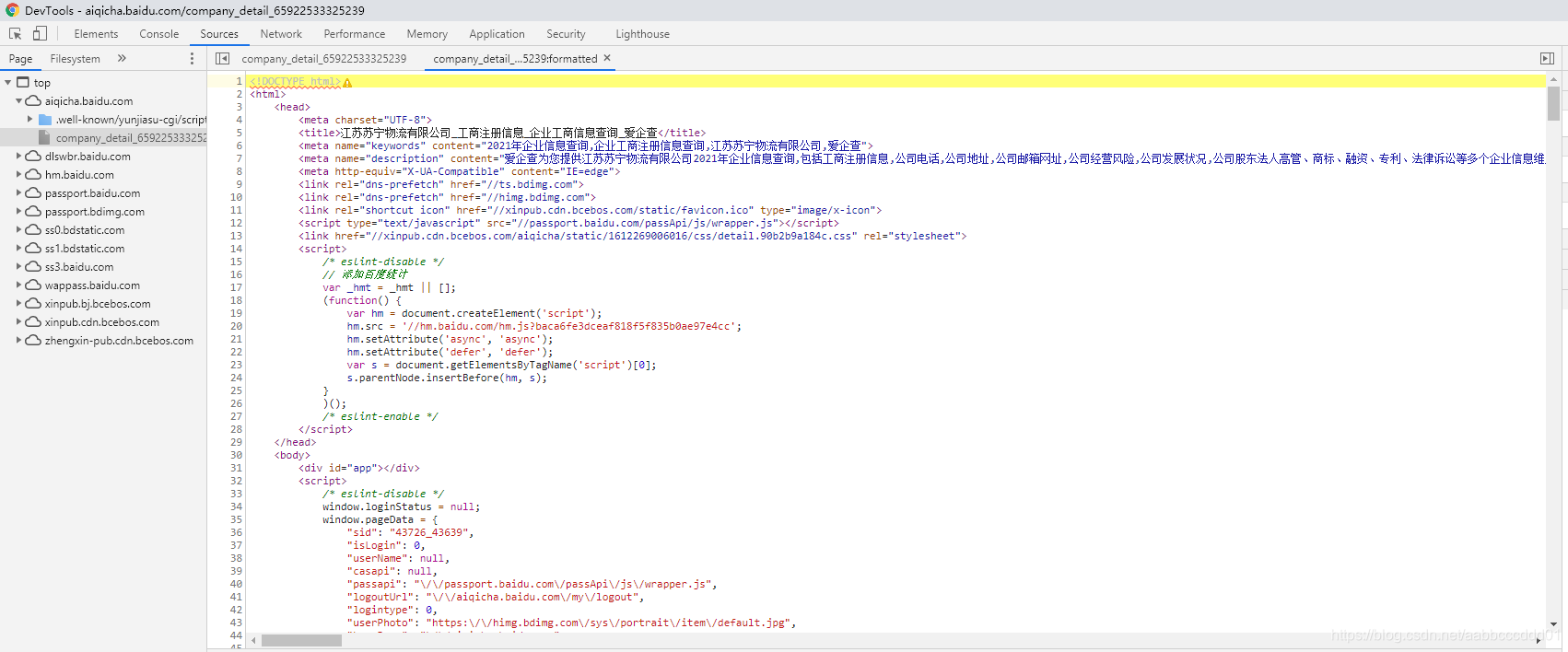
但是通过谷歌浏览器的Elements发现,对应的元素与值又显示出来了:
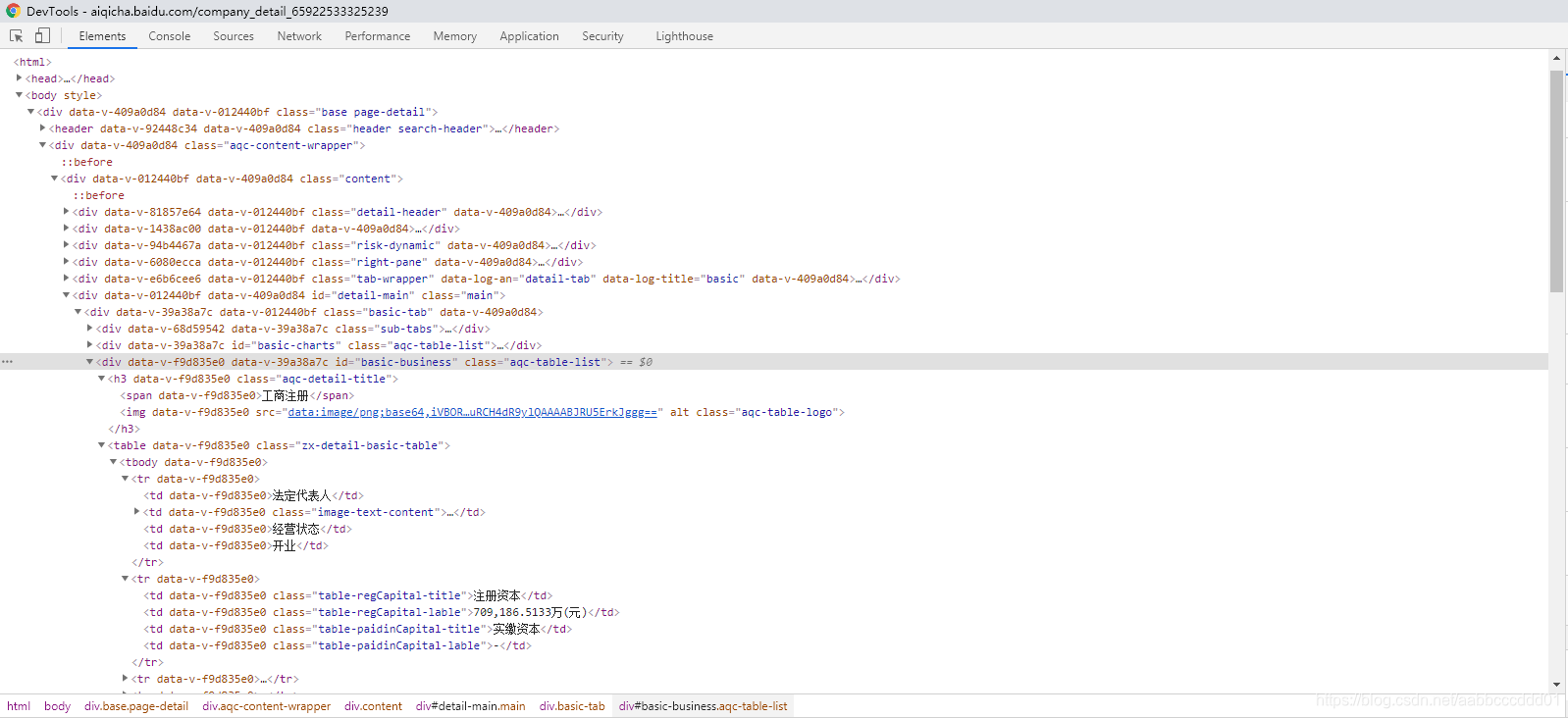
通过Python常规的网页访问方式如requets是不能获取到Elements对象的信息的,其实我也不太懂这里是什么意思,好像是由于没有加载网页?为了模拟浏览器登录获取到同样的信息,百去网上搜索之后采用PhantomJS模拟浏览器登录,这样就可以获取到我们需要的信息了,话不多说,直接看代码吧。
代码与详解
总结一下爬爬取企业信息的流程
1.先在企查查的主页搜索公司信息,获得搜索结果列表(公司名称可能相近,因此会得到很多相似的公司名搜索结果),这里我只取了搜索的第一个结果,在代码里也会注明。
2.根据搜索列表的pid参数构建点进去的得到公司的详情页面的链接
3.使用PhantomJS模拟浏览器直接访问详情页面
4,解析详情页面的标签,获取到需要爬取得数据
# -*- coding:utf-8 -*-
#爬虫获取企业工商注册信息
from selenium import webdriver
import requests
import re
import json
import os
headers = {'User-Agent': 'Chrome/76.0.3809.132'}
#需要安装phantomjs,然后将phantomjs.exe路径指定到path
path = os.path.join(os.getcwd(), 'static', 'phantomjs', 'phantomjs.exe')
# print(path)
# 正则表达式提取数据
re_get_js = re.compile(r'<script>([\s\S]*?)</script>')
re_resultList = re.compile(r'"resultList":(\[{.+?}\]),"totalNumFound')
has_statement = False
def get_company_info(name):
'''
@func: 通过百度企业信用查询企业基本信息
'''
url = 'https://aiqicha.baidu.com/s?q=%s' % name
res = requests.get(url, headers=headers)
if res.status_code == 200:
html = res.text
js = re_get_js.findall(html)[1]
data = re_resultList.search(js)
if not data:
return
company = json.loads(data.group(1))[0]
url = 'https://aiqicha.baidu.com/company_detail_{}'.format(company['pid'])
# 调用环境变量指定的PhantomJS浏览器创建浏览器对象
driver = webdriver.PhantomJS(path)
driver.set_window_size(1366, 768)
driver.get(url)
# 获取页面名为wraper的id标签的文本内容
data = driver.find_element_by_class_name('zx-detail-basic-table').text
data = data.split()
data_return = {}
need_info = ['法定代表人', '经营状态', '注册资本', '实缴资本', '曾用名', '所属行业', '统一社会信用代码', '纳税人识别号', '工商注册号', '组织机构代码', '登记机关',
'成立日期', '企业类型', '营业期限', '审核/年检日期', '注册地址', '经营范围']
for epoch, item in enumerate(data):
if item in need_info:
if data[epoch + 1] in need_info or data[epoch + 1] == '-':
data_return[item] = None
continue
if item == '法定代表人':
if len(data[epoch + 1]) == 1:
data_return[item] = data[epoch + 2]
else:
data_return[item] = data[epoch + 1]
pass
elif item == '营业期限':
if data[epoch + 2] == '至':
data_return[item] = data[epoch + 1] + ' ' + data[epoch + 2] + ' ' + data[epoch + 3]
else:
data_return[item] = data[epoch + 1]
return data_return
else:
print('无法获取%s的企业信息' % name)
# get_company_info('江苏苏宁')
需要提前安装好phantomjs,这是一个无界面浏览器,大家可以资讯百度,将phantomjs.exe得路径指定到path就可以了
讲的不是很详细,但是结构比较简单,大家可以直接逐步打印信息查看爬虫过程,还是比较简单的。
这样的爬虫比较慢,一次爬虫大概5-10s,不过胜在稳定,用了这么久几乎没有出过问题。
喜欢的请一键三联👍
[1]: https://blog.csdn.net/qq_35408030/article/details/107068115


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









