







参考/引用资料:
Python 3 |菜鸟教程 http://www.runoob.com/python3/python3-tutorial.html
廖雪峰 Python教程 https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000
C语言中文网 http://c.biancheng.net/python/function/
mrbean博客 https://www.cnblogs.com/MrLJC/p/3715783.html
苍松博客 https://www.cnblogs.com/tkqasn/p/6001134.html
天道酬勤_FUN https://www.jianshu.com/p/d78982126318
https://blog.csdn.net/yatere/article/details/6658457
1.file
a.打开文件方式(读写两种方式)
Python使用 open() 方法用于打开一个文件,并返回文件对象,在对文件进行处理过程都需要使用到这个函数,如果该文件无法被打开,会抛出 OSError。
注意:使用 open() 方法一定要保证关闭文件对象,即调用 close() 方法。
open() 函数常用形式是接收两个参数:文件名(file)和模式(mode)。
open(file, mode='r')
完整的语法格式为:
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
参数说明:
file: 必需,文件路径(相对或者绝对路径)。
mode: 可选,文件打开模式
buffering: 设置缓冲
encoding: 一般使用utf8
errors: 报错级别
newline: 区分换行符
closefd: 传入的file参数类型
opener:
mode 参数有:
| 模式 | 描述 |
|---|---|
| t | 文本模式 (默认)。 |
| x | 写模式,新建一个文件,如果该文件已存在则会报错。 |
| b | 二进制模式。 |
| + | 打开一个文件进行更新(可读可写)。 |
| U | 通用换行模式(不推荐)。 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。默认为文本模式,如果要以二进制模式打开,加上 b 。 |
默认为文本模式,如果要以二进制模式打开,加上 b 。
w 只是代表写模式,而 w+ 则代表读写模式,但实际上它们的差别并不大。因为不管是 w 还是 w+ 模式,当使用这两种模式打开指定文件时,open() 函数都会立即清空文件内容,实际上都无法读取文件内容。
下图说明了不同文件打开模式的功能。
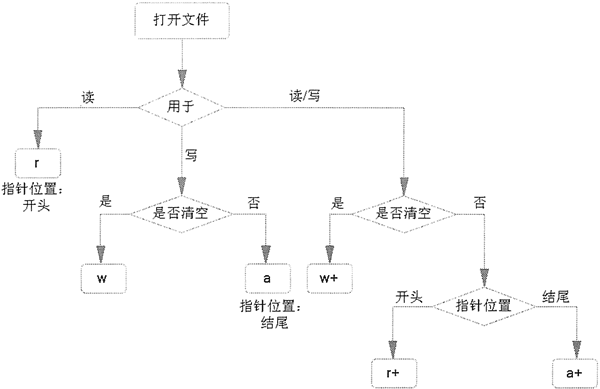
需要指出的是,如果程序使用 r 或 r+ 模式打开文件,则要求被打开的文件本身是存在的。也就是说,使用 r 或 r+ 模式都不能创建文件。但如果使用 w、w+、a、a+ 模式打开文件,则该文件可以是不存在的,open() 函数会自动创建新文件。
b 模式可被迫加到其他模式上,用于代表以二进制的方式来读写文件内容。对于计算机中的文件来说,文本文件只有很少的一部分,大部分文件其实都是二进制文件,包括图片文件、音频文件、视频文件等。
如果使用文本方式来操作二进制文件,则往往无法得到正确的文件内容。道理很简单,比如强行以文本方式打开一个音频文件,则势必会出现乱码。因此,如果程序需要读写文本文件以外的其他文件,则都应该添加 b 模式。
缓冲
众所周知,计算机外设(比如硬盘、网络)的 I/O 速度远远低于访问内存的速度,而程序执行 I/O 时要么将内存中的数据写入外设,要么将外设中的数据读取到内存,如果不使用缓冲,就必须等外设输入或输出一个字节后,内存中的程序才能输出或输入一个字节,这意味着内存中的程序大部分时间都处于等待状态。
内存中程序的读写速度很快,如果不使用缓冲,则程序必须等待外设进行同步读写。打个形象的比喻,就像在一条堵车的马路上开着跑车,必须等前面的车开一点,跑车才能前进一点。
因此,一般建议打开缓冲。在打开缓冲之后,当程序执行输出时,程序会先将数据输出到缓冲区中,而不用等待外设同步输出,当程序把所有数据都输出到缓冲区中之后,程序就可以去干其他事情了,留着缓冲区慢慢同步到外设即可;反过来,当程序执行输入时,程序会先等外设将数据读入缓冲区中,而不用等待外设同步输入。
在使用 open() 函数时,如果其第三个参数是 0(或 False),那么该函数打开的文件就是不带缓冲的;如果其第三个参数是 1(或 True),则该函数打开的文件就是带缓冲的,此时程序执行 I/O 将具有更好的性能。如果其第三个参数是大于 1 的整数,则该整数用于指定缓冲区的大小(单位是字节);如果其第三个参数为任何负数,则代表使用默认的缓冲区大小。
with语句
Python 提供了 with 语句来管理资源关闭。比如可以把打开的文件放在 with 语句中,这样 with 语句就会帮我们自动关闭文件。
with 语句的语法格式如下:
with context expression [as target(s)]:
with 代码块
在上面的语法格式中,context_expression 用于创建可自动关闭的资源。
例如,程序使用 with 语句来读取文件:
import codecs
# 使用with语句打开文件,该语句会负责关闭文件
with codecs.open("readlines_test.py", 'r', 'utf-8', buffering=True) as f:
for line in f:
print(line, end='')
## b.文件对象的操作方法
b.文件对象的操作方法
file 对象:file 对象使用 open 函数来创建,下表列出了 file 对象常用的函数:
| 方法 | 描述 |
|---|---|
| file.close() | 关闭文件。关闭后文件不能再进行读写操作。没有返回值。 |
| file.flush() | 刷新文件内部缓冲,直接把内部缓冲区的数据立刻写入文件, 而不是被动的等待输出缓冲区写入。没有返回值。 |
| file.fileno() | 返回一个整型的文件描述符(file descriptor FD 整型), 可以用在如os模块的read方法等一些底层操作上。 |
| file.isatty() | 如果文件连接到一个终端设备返回 True,否则返回 False。 |
| file.next() | 返回文件下一行。 |
| file.read([size]) | 从文件读取指定的字节数,如果未给定或为负则读取所有。 |
| file.readline([size]) | 读取整行,包括 “\n” 字符。 |
| file.readlines([sizeint]) | 读取所有行并返回列表,若给定sizeint>0,返回总和大约为sizeint字节的行, 实际读取值可能比 sizeint 较大, 因为需要填充缓冲区。 |
| file.seek(offset[, whence]) | 设置文件当前位置 |
| file.tell() | 返回文件当前位置。 |
| file.truncate([size]) | 从文件的首行首字符开始截断,截断文件为 size 个字符,无 size 表示从当前位置截断;截断之后后面的所有字符被删除,其中 Widnows 系统下的换行代表2个字符大小。 |
| file.write(str) | 将字符串写入文件,返回的是写入的字符长度。 |
| file.writelines(sequence) | 向文件写入一个序列字符串列表,如果需要换行则要自己加入每行的换行符。 |
c.学习对excel及csv文件进行操作
读写excel
读excel表
读excel要用到xlrd模块
#导入模块
import xlrd
#打开Excel文件读取数据
data = xlrd.open_workbook('excel.xls')
table = data.sheets()[0] #通过索引顺序获取
table = data.sheet_by_index(0) #通过索引顺序获取
table = data.sheet_by_name(u'Sheet1') #通过名称获取
#获取整行和整列的值(返回数组)
table.row_value 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2595
2595











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









