







本文所涉及所有资源均在传知代码平台可获取。
概述
扩散模型(Diffusion model)是一种目前在图像生成领域非常流行的生成模型,它来源于非平衡热力学理论。该模型最早由Sohl-Dickstein等人于2015年提出,通过迭代前向扩散过程,系统地、缓慢地破坏数据分布中的结构,并学习其反向扩散过程,从而生成类似数据的算法。自2015年以来,Diffusion model得到了不断的发展和改进,其中最具代表性的是2020年Jonathan Ho等人提出的Denoising diffusion probabilistic models,该模型在Sohl-Dickstein等人的基础上提出了更加实用的方法,进一步增强了模型的生成能力和鲁棒性。
● Sohl-Dickstein J, Weiss E A, Maheswaranathan N, et al. Deep Unsupervised Learning using Nonequilibrium Thermodynamics[J]. arXiv, 2015.
● Ho J, Jain A, Abbeel P. Denoising Diffusion Probabilistic Models[J]. arXiv, 2020.
准备工作-数据集
在本文,为了方便我们不去生成图片这种维度较高的数据集,而是以二维点集为例子来说明扩散模型的基本思想。在本文所使用的原始数据的蝴蝶分布,即

选这个分布的原因是其结构较为复杂,能够体现出生成模型生成的质量。这个分布是靠蝴蝶曲线得到的
def butterfly(self,nums,noise=0.0):
theta = np.linspace(0, 2 * np.pi, nums)
r = np.exp(np.cos(theta)) - 2 * np.cos(4 * theta) + np.power(np.sin(theta / 12), 5)
y = r * np.cos(theta) + noise * np.random.randn(nums)
x = r * np.sin(theta) + noise * np.random.randn(nums)
points = []
for i in range(0, nums):
points.append(np.array([x[i], y[i]]))
return np.array(points)演示效果
Denoising Diffusion Probabilistic Models 去噪扩散模型
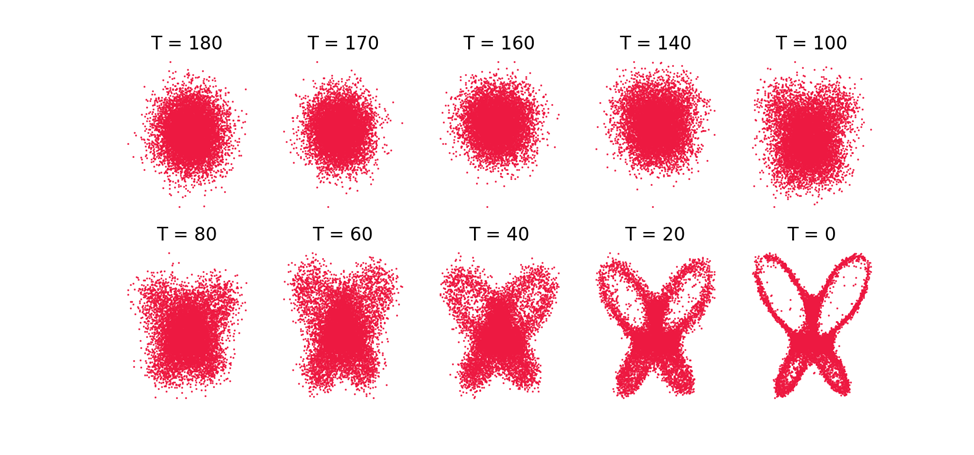
去噪扩散模型(denoising diffusion probabilistic models,以下简称DDPM)的核心思想是对现有数据集中的样本不断添加高斯噪声,使得样本接近真正的高斯分布;通过这个前向过程学习其逆向过程,通过不断迭代,从一个高斯分布中生成类似结构的数据,该模型的具体过程如图所示

数据集中的样本x0x0是从一个真实分布q(x0)q(x0)中抽取得到的。在前向过程中,对于每一步tt都会在前一步样本xt−1xt−1的基础上添加高斯噪声从而得到一个新的样本xtxt, 每一步的噪声大小可以用参数βtβt来控制
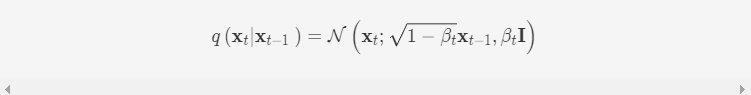
对x0x0添加TT次噪声依次可以得到一系列同维度的数据x0,x1,…,xTx0,x1,…,xT。考虑到t较小时的噪声富含了数据样本演化到高斯噪声过程中的大部分细节,因此每一步的噪声等级选择β1<β2<…<βTβ1<β2<…<βT。为了方便起见,可令αt=1−βtαt=1−βt以及αˉt=∏1tαtαˉt=∏1tαt,从而得到
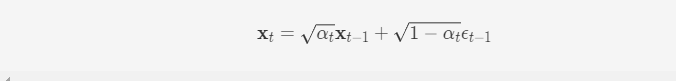
前向过程中一个很好的特性是任意步t下的加噪数据样本xtxt都可以直接由x0x0直接给出,免去了循环迭代的过程,使得前向过程在该模型中变得十分简单,即
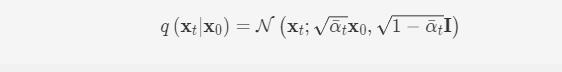
该模型的核心是逆向过程,需要将一个从高斯分布N(0,I)N(0,I)中抽样得到的数据xTxT不断去噪最终得到我们的目标数据x0x0。要做到这一点,我们需要知道每一步的噪声分布q(xt−1|xt)q(xt−1∣xt)。然而,事实上我们无法直接知道这个分布,因此我们可以使用神经网络模型pθ(xt−1|xt)pθ(xt−1∣xt)去学习并拟合这个分布。考虑到前向过程中的噪声为高斯噪声,故可以把pθ(xt−1|xt)pθ(xt−1∣xt)写成类似的结构
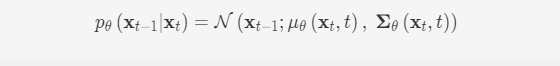
我们可以通过贝叶斯公式,计算得到
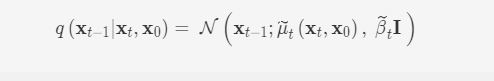
其中
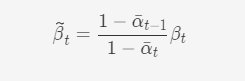
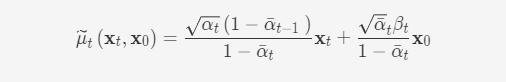
前面提到,每一步的xtxt可直接由x0x0计算得到,因此反过来可以将xtxt用x0x0表示,并代入可得
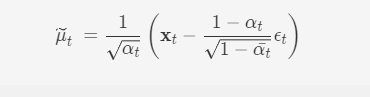
要从前向加噪过程中学习pθ(xt−1|xt)pθ(xt−1∣xt)的前提是知道并确定该模型的训练损失函数。该模型借鉴了变分自动编码器(VAE)的中的思想和推导过程,通过变分优化交叉熵的上界LVLBLVLB来实现。即
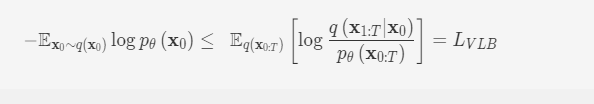
利用贝叶斯公式对L_{VLB}化解后,我们得到
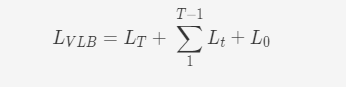
其中

由于预设的q(xt|xt+1,x0)q(xt∣xt+1,x0)和pθ(xt|xt+1)pθ(xt∣xt+1)都是高斯分布,故
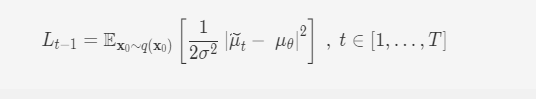
联想到μ~tμt的形式,将μθμθ设置成类似的形式
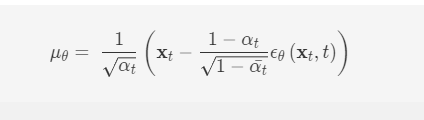
ϵθ(xt,t)ϵθ(xt,t)就是我们要学习的噪声网络了,而损失函数为
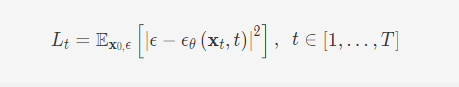
实现前向过程
首先,我们先观察前向过程,即不断给原始数据加高斯噪声最终将原始数据变成白噪声的过程
def getXt(self, x_0, t, nums):
return np.sqrt(self.npara.getProdAlpha(t)) * x_0 + np.sqrt(1 - self.npara.getProdAlpha(t)) * np.random.randn(nums,2)我们可以观察特定步数的结果来清晰的观察整个加噪的过程
test_t = [ 0, 19, 49, 69,89,109,129,149,169,179 ]
fig, axs = plt.subplots(1,len(test_t),figsize=(30,3))
plt.rc('text', color='black')
for i in range(len(test_t)):
x_t = DPNN.getXt(x_0, test_t[i], nums)
axs[i].scatter(x_t[:,0],x_t[:,1] ,color='#45b97c',s=1)
axs[i - 1].set_axis_off()
axs[i].set_title('T = ' + str(test_t[i]+1))
plt.savefig(dir_name + "/x_t_change.png")
plt.show()
逆向过程
逆向过程即为采样过程,通过一个噪声网络预测噪声,然后一步一步迭代得到最终的采样结果,这个迭代过程可以由之前的推导公式给出,即
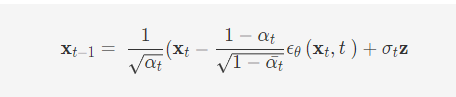
def sample_loop(self, x, t ):
alpha = self.npara.alpha[t]
alpha_bar = self.npara.prodAlpha[t]
a = 1.0 / np.sqrt( alpha )
b = ( 1.0 - alpha ) / np.sqrt( 1 - alpha_bar )
c = np.sqrt(self.npara.beta[t])
z = torch.randn_like(x)
z_theta = self.unn( x, tensor([t]).float() )
return a * ( x - b * z_theta ) + c * z
def sample(self, source):
x = torch.randn_like(tensor(source).float())
res = [x]
for t in reversed(range(self.T)):
x = self.sample_loop(x, t)
res.append(x)
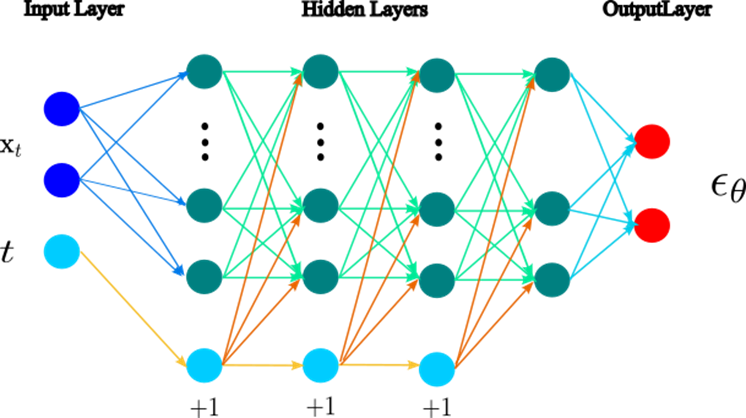
return res上面先写了一个一步的函数sample_loop,再写了一个不断迭代的函数sample,其中self.unn为一个噪声网络,即
class PredictNoiseNet(nn.Module):
def __init__(self, num_units = 128):
super(PredictNoiseNet, self).__init__()
self.x_embeddings = nn.ModuleList(
[
nn.Linear(2, num_units),
nn.ReLU(),
nn.Linear(num_units, num_units),
nn.ReLU(),
nn.Linear(num_units, num_units),
nn.ReLU(),
nn.Linear(num_units, 2),
]
)
self.t_embeddings = nn.ModuleList(
[
nn.Linear(1, num_units),
nn.Linear(1, num_units),
nn.Linear(1, num_units),
]
)
def forward(self, x, t):
for idx, embedding_layer in enumerate(self.t_embeddings):
t_embedding = embedding_layer(t)
x = self.x_embeddings[2 * idx](x)
x += t_embedding
x = self.x_embeddings[2 * idx + 1](x)
x = self.x_embeddings[-1](x)
return x这个网络非常简单仅仅是一个受tt控制的全连接网络
训练过程
训练过程与前面给的损失函数有关,损失函数是跟时间步tt密切相关的,所以我们需要首先随机选择的一个时间步tt,然后计算出这一步的xtxt,然后根据当前的xtxt和tt以及噪声网络算出这一步的噪声,再利用损失函数计算即可(记住前向的噪声是高斯分布固定的,所以直接采样就行)
def train(self, data):
#time series
t = torch.randint(0, self.T, (len(data),))
#random noise
z = torch.randn_like(data)
#step arguments
prodAlpha, somprodalpha = self.npara.getListLikeProdAlpha(t)
x_t = data * prodAlpha.unsqueeze(-1) + z * somprodalpha.unsqueeze(-1)
z_theta = self.unn(x_t.float(), t.float().unsqueeze(-1))
loss = (z - z_theta).square().mean()
self.optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(self.unn.parameters(), 1.)
self.optimizer.step()
return loss训练结果
● epoch 100

● epoch 200

● epoch 300

● …
● epoch 1000

总览

使用方式
● 终端运行python main.py
安装依赖
● Python 3.11.4
● torch 2.0.1
感觉不错,点击我,立即使用
















 628
628

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











