







本文所涉及所有资源均在传知代码平台可获取。
一、概述
本文讲解并复现了2024年一篇多模态情感计算的文章 “TETFN: A text enhanced transformer fusion network for multimodal sentiment analysis”,这篇论文利用三种模态之间进行交互,并对文本模态进行增强,以更准确的提取非文本模态的情感信息。
二、论文地址
三、研究背景
随着社交媒体和短视频行业的快速发展,来自文本、视频和音频的多模态数据呈现爆炸式增长。与此同时,捕获设备的广泛使用,加上其易用性、移动性和低成本,使得从不同用户捕获情感线索变得容易,这与人类语言交流相同。这三种情态在表达过程中既有语义上的联系又有互补性。因此,在多模态情感分析中的一个关键问题是如何设计一种多模态融合方案来有效地集成异构数据,以便学习包含更多情感相关信息的多模态表示,同时保持每个模态的一致性和差异性信息。
四、主要贡献
1. 本文提出了一种文本增强型Transformer融合网络,该网络通过面向文本的多头注意机制和文本引导的跨模态映射来获得模态间的一致性,并通过单峰预测来保持差异化信息;
2. 利用视觉预训练模型ViT对原始视频进行预处理和特征提取,以获得具有全局和局部信息的视觉特征;
3. 在增强文本模态表示的同时,利用文本模态信息充分提取非文本模态特征,并充分融合模态间表示,提高情感预测的准确性;
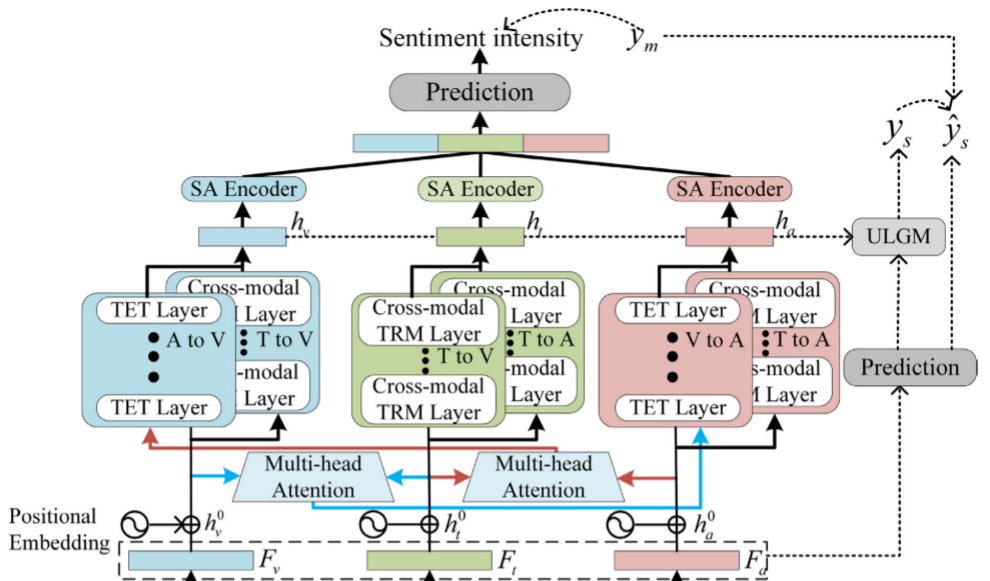
六、模型框架
下图是整体的TETFN模型框架:
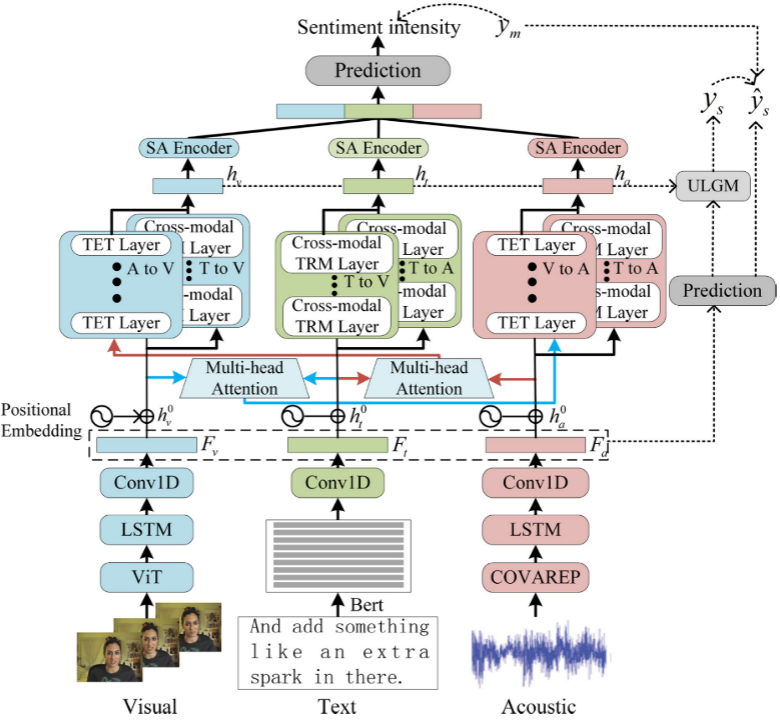
接下来,我们对其中重要模块逐一进行讲解;
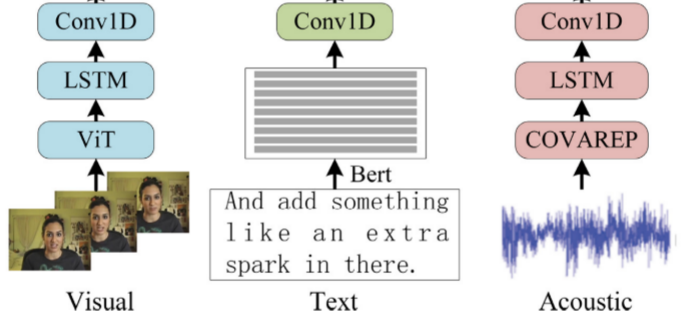
1. 特征提取
● 文本特征:使用预先训练好的语言模型Bert作为文本编码器,它可以为文本模态提供丰富的语义信息。给定原始句子S=w1,w2,...,wnS=w1,w2,...,wn,在将SS与两个特殊令牌[CLS][CLS]和[SEP][SEP]连接之后,将该序列输入到编码器中;然后,具有上下文信息的序列表示作为文本模态的输入;
● 视觉特征:至于视觉模态,使用预先训练的视觉模型Vision-Transformer(ViT)作为视觉编码器。视觉形态的情感主要通过面部表情来体现。同时,鉴于眼睛、嘴巴等特定器官更能反映人的情绪,因此本文采用ViT来获取人脸的全局和局部信息;
● 声学特征:对于音频模态,利用由COVERAP声学分析框架提取的音频手工特征。特征包括12个梅尔频率倒谱系数、音高、音量、声门源参数以及与语音的情绪和音调相关的其他特征。CMU-MultimodalSDK可以获得每个多模态示例的COVERAP特征序列;
● 上下文编码:鉴于说话人在视频中的情感表达是一个连续的过程,每种模态的输入序列都具有时间性。因此,为了通过将时间长期依赖注入特征序列来模拟情感的变化过程,对视觉和声学使用单层长短期记忆网络(LSTM),然后对所有模态使用时间卷积网络来捕获每个时间步的信息的时间依赖性,并投射所有隐藏状态以获得后续过程的统一维度;
2. 文本增强型Transformer模块
● Text enhanced Transformer主要包含3个模块:Positional embedding、Text Enhanced Transformer、Unimodal Label Generation Module;我们分别对他们进行介绍和讲解:Positional embedding
● 为了让模型捕获输入的顺序信息,根据Transformer的结构,作者在每个模态的低层表示中添加了位置嵌入,

Text Enhanced Transformer
设计了一个文本增强的Transformer(TET)模块,以更好地编码三个信息源。TET通过计算两种模态之间的注意力权重来促进一种模态从另一种模态接收信息,从而促进不同模态的情感相关信息的交互。众所周知,文本是反映说话人情感的最基本、最直观的形式,比视频和音频包含更多的情感相关信息。因此,当视觉模态v和音频模态a被映射和转换到彼此时,融合特征缺乏情感相关的信息和语义。针对这种情况,除了标准的多头注意力编码功能,从其他形式的组合,作者利用面向文本的多头注意力机制,它利用文本来催化音频和视觉形式之间的交互;下图是该模块的运作图:
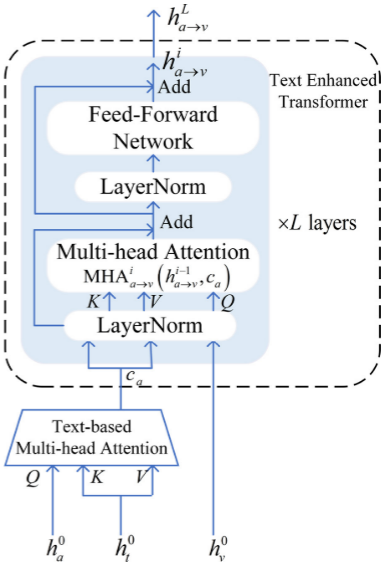
部分交互代码如下:
h_l_with_as = self.trans_l_with_a(proj_x_l, proj_x_a, proj_x_a) # Dimension (L, N, d_l)
h_l_with_vs = self.trans_l_with_v(proj_x_l, proj_x_v, proj_x_v) # Dimension (L, N, d_l)
h_ls = torch.cat([h_l_with_as, h_l_with_vs], dim=2)
h_ls = self.trans_l_mem(h_ls)
if type(h_ls) == tuple:
h_ls = h_ls[0]
last_h_l = h_ls[-1] # Take the last output for prediction
# (L,V) --> A
h_a_with_ls = self.trans_a_with_l(proj_x_a, proj_x_l, proj_x_l)
h_a_with_vs = self.trans_a_with_v(proj_x_v, proj_x_a, proj_x_l)
h_as = torch.cat([h_a_with_ls, h_a_with_vs], dim=2)
h_as = self.trans_a_mem(h_as)
if type(h_as) == tuple:
h_as = h_as[0]
last_h_a = h_as[-1]
# (L,A) --> V
h_v_with_ls = self.trans_v_with_l(proj_x_v, proj_x_l, proj_x_l)
h_v_with_as = self.trans_v_with_a(proj_x_a, proj_x_v, proj_x_l)
h_vs = torch.cat([h_v_with_ls, h_v_with_as], dim=2)
h_vs = self.trans_v_mem(h_vs)
if type(h_vs) == tuple:
h_vs = h_vs[0]
last_h_v = h_vs[-1]
# fusion
fusion_h = torch.cat([last_h_l, last_h_a, last_h_v], dim=-1)
fusion_h = self.post_fusion_dropout(fusion_h)
fusion_h = F.relu(self.post_fusion_layer_1(fusion_h), inplace=False)
# # text
text_h = self.post_text_dropout(text_h)
text_h = F.relu(self.post_text_layer_1(text_h), inplace=False)
# audio
audio_h = self.post_audio_dropout(audio_h)
audio_h = F.relu(self.post_audio_layer_1(audio_h), inplace=False)
# vision
video_h = self.post_video_dropout(video_h)
video_h = F.relu(self.post_video_layer_1(video_h), inplace=False)● Unimodal Label Generation Module
作者将单峰标签生成模块(ULGM)集成以捕获特定于模态的信息。在前向传播过程中,通过LSTM的音频和视觉模态的最后隐藏状态被用作初始表示。同时,在Bert的最后一层中的第一个词向量被选为文本表示。然后,通过全连接层获得单峰预测。在训练阶段,首先用预测的单峰标签和多峰融合表示来定义正中心和负中心。然后,计算从每个模态的表示到正中心和负中心的相对距离,并获得从单峰标签到多模态标签的偏移值,以生成第i个epoch的单峰标签。这样,更有利于情感分析获得不同模态的差异化信息,同时保持每个模态的一致性;
七、数据介绍及下载
1. CMU-MOSI:它是一个多模态数据集,包括文本、视觉和声学模态。它来自Youtube上的93个电影评论视频。这些视频被剪辑成2199个片段。每个片段都标注了[-3,3]范围内的情感强度。该数据集分为三个部分,训练集(1,284段)、验证集(229段)和测试集(686段)。
2. CMU-MOSEI:它类似于CMU-MOSI,但规模更大。它包含了来自在线视频网站的23,453个注释视频片段,涵盖了250个不同的主题和1000个不同的演讲者。CMU-MOSEI中的样本被标记为[-3,3]范围内的情感强度和6种基本情绪。因此,CMU-MOSEI可用于情感分析和情感识别任务。
在此附上下载链接:CMU-MOSI、CMU-MOSEI
八、复现过程(重要)
在准备好数据集并调试代码后,进行下面的步骤,附件已经调通并修改,可直接正常运行;
1. 下载多模态情感分析集成包
pip install MMSA2. 进行训练
# show usage
$ python -m MMSA -h
# train & test LMF on MOSI with default parameters
$ python -m MMSA -d mosi -m lmf -s 1111 -s 1112
# tune 50 times of TFN on MOSEI with custom config file & custom save dir
$ python -m MMSA -d mosei -m tfn -t -tt 30 --model-save-dir ./models --res-save-dir ./results
# train & test self_mm on SIMS with custom audio features & use gpu2
$ python -m MMSA -d sims -m self_mm -Fa ./Features/Feature-A.pkl --gpu-ids 2九、运行过程及结果
值得注意的是,我没有设置固定的epoch轮数,利用每轮训练结果与best performance比较,知道结果达到最好,则自动停止训练;
1. 训练过程

2. 每轮的单模态预测结果
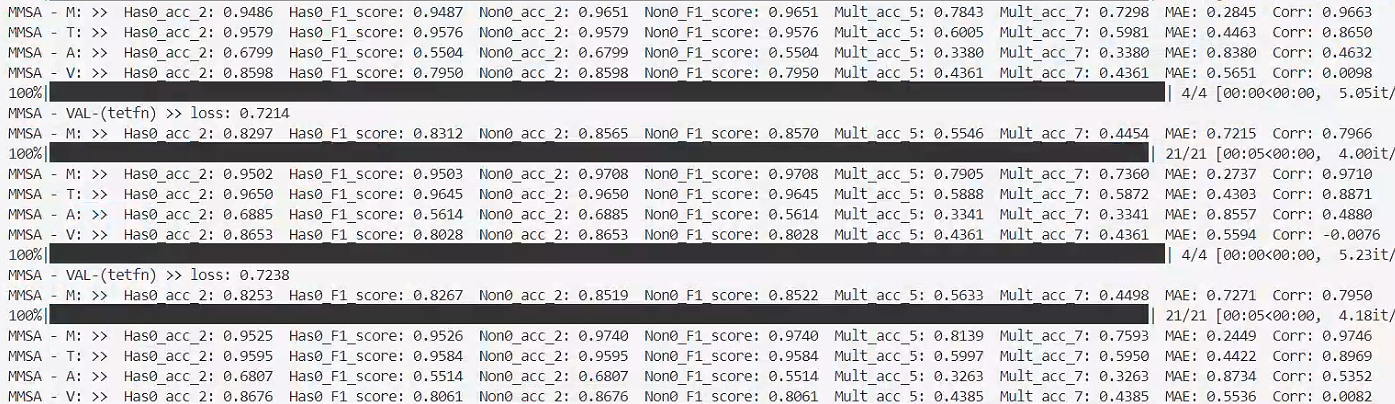
3. 最终模型结果输出

感觉不错,点击我,立即使用
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











