







Redis
说一下 Redis以及Redis 使用场景
答:Redis 是一种基于内存的数据库,对数据的读写操作都是在内存中完成,因此读写速度非常快,常用于缓存,消息队列、分布式锁等场景。
Redis 设置过期时间的命令
# 设置 key 在 60 秒后过期(该方法是针对已经存在的key设置过期时间)一般不常用
expire key 60
# setex key 时间 value--设置key = name value = lisi ,60秒过期
setex name 60 lisi
set name lisi ex 60分布式锁
答:Redis中可以用setnx设计分布式锁,为什么呢?因为setnx key value 只有当key不存在时候才会建立。但是在实际中常常如下命令创建分布式锁。
set key value nx ex 时间为什么是这样呢?
- 我们想一下,nx表示当键不存在时候才会创建,如果有线程1已经创建了锁,那么线程2,或者线程3执行这个命令就会失败。因此会获得不到锁对象。
- 设置锁过期时间是防止锁没有及时释放,其他线程或系统获取不到锁。
设计锁时要注意一些问题:
第一这个value是全局唯一的。是为了防止误删现象。
- 假如有线程1,获取了锁对象,在执行业务时被阻塞了,此时锁的时间过期了。
- 那么线程2 就可以获取锁对象,此时,线程1完成业务,(如果value不是全局唯一)那么线程1直接将锁释放,后来线程3,线程4。。就可以并发执行出现并发安全问题。
- 因此,我们设置全局唯一value值,在释放锁时要判断value值是不是自己的然后才进行释放。
第二锁释放要设置为原子性操作。为什么要这样呢?
如下图代码所示:判断value值是否是自己的,然后才进行锁释放操作。
public void unlock() {
// 获取线程标示
String threadId = ID_PREFIX + Thread.currentThread().getId();
// 获取锁中的标示
String id = stringRedisTemplate.opsForValue().get(KEY_PREFIX + name);
// 判断标示是否一致
if(threadId.equals(id)) {
// 释放锁
stringRedisTemplate.delete(KEY_PREFIX + name);
}
因此要采用Lua脚本实现原子操作。
-- 这里的 KEYS[1] 就是锁的key,这里的ARGV[1] 就是当前线程标示
-- 获取锁中的标示,判断是否与当前线程标示一致
if (redis.call('GET', KEYS[1]) == ARGV[1]) then
-- 一致,则删除锁
return redis.call('DEL', KEYS[1])
end
-- 不一致,则直接返回
return 0具体请看黑马点评项目Redis实现分布式锁_兜兜转转m的博客-CSDN博客
业务里 redis 的过期策略设置
我做的Redis过期策略有两种,
- 一种是直接过期就是设置过期时间,然后过期就删除数据。
- 一种是理论过期时间,就是在redis中添加一个字段,设置过期的时间,相当于用代码判断进行逻辑删除。---可以解决缓存击穿问题。
你的 redis 的使用场景
我使用的Redis场景
- 利用token和Redis进行登录验证
- 用作缓存-并且缓解缓存穿透、缓存雪崩和缓存击穿。
- 秒杀优惠券或者说是抢购劵
- 实现分布式锁
- 利用Redis的GEOHash来完成对于地理坐标的操作
- 使用Redis的BitMap数据统计功能
- 基于Set集合的关注、取消关注,共同关注等等功能
基于上述分析请看博主Redis专栏内容。Redis_兜兜转转m的博客-CSDN博客
缓存穿透:客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库。
-
缓存空对象
-
优点:实现简单,维护方便
-
缺点:
-
额外的内存消耗
-
可能造成短期的不一致,由于你设置为null。
-
-
缓存雪崩是指在同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力。
- 给不同的Key的TTL添加随机值
- 利用Redis集群提高服务的可用性
缓存击穿问题也叫热点Key问题,就是一个被高并发访问并且缓存重建业务较复杂的key突然失效了,无数的请求访问会在瞬间给数据库带来巨大的冲击。
-
互斥锁
-
逻辑过期
这里仅仅是进行总结
Redis 的淘汰策略
- noeviction:当内存使用超过配置的时候会返回错误,不会驱逐任何键
- allkeys-lru:加入键的时候,如果过限,首先通过LRU算法驱逐最久没有使用的键
- volatile-lru:加入键的时候如果过限,首先从设置了过期时间的键集合中驱逐最久没有使用的键
- allkeys-random:加入键的时候如果过限,从所有key随机删除
- volatile-random:加入键的时候如果过限,从过期键的集合中随机驱逐
- volatile-ttl:从配置了过期时间的键中驱逐马上就要过期的键
- volatile-lfu:从所有配置了过期时间的键中驱逐使用频率最少的键
- allkeys-lfu:从所有键中驱逐使用频率最少的键
你的使用场景 redis 宕机了怎么办
宕机:服务器停止服务
如果只有一台redis,肯定会造成数据丢失,无法挽救使用。
我们采用AOF和RDB
MySQL
Mysql 查询(出生日期,性别)在表(id,性别,年龄,出生日期)中怎么设置索引。
mysql 索引怎么选择?索引的优缺点?还有什么缺点 或者讲一下索引的你的理解
索引失效的场景、场景题的索引设计
这两个题是一个类型题,我就一起说了。
出生日期是非唯一索引,性别只有:男,女,其区分度不高,因此我们最不好不对其建立索引。
答:一般常用在where, orderby, group by字段进行索引设置,我们常见的索引一般是,主键索引,唯一索引和普通索引,其优点在于提升数据库对数据的查询速度,缺点是占用存储空间,而且会影响insert,update,delete的速度。但是索引并不是简简单单设置一下就好了,它也有相应的使用规则,否则其失效。
- 要遵循最左前缀法则,否则会索引会失效
- 在条件判断时索引字段不能作为函数的参数
- 索引字段不能进行类型转换。
- 使用<>查询是后面索引会失效。
- 当索引列模糊查询进行模糊头查询时。
- 在联合索引下,遵循最左前缀准则,而且不能跳过,如果跳过会引起部分索引失效。
- or连接条件:用or分割开的条件, 如果or前的条件中的列有索引,而后面的列中没有索引,那么涉及的索引都不会 被用到
- 数据查询分布不均匀时
具体参考MySQL进阶-索引生效和设计的原则总结_兜兜转转m的博客-CSDN博客
sql 事务的特性?什么是持久性
答:事务的特性主要有4个,也是我们常说的ACID,对应的是原子性,一致性,隔离性和持久性。
持久性:表示在某个事务的执行过程中,对数据所作的所有改动都必须在事务成功结束前保存至某种物理存储设备。
持久性的实现主要是通过redo log保证的。
redo log是Innodb引擎特有的,其主要分为日志缓存区和日志文件两部分组成,前部分是在于内存中后部分在于磁盘中。它记录的是一条更新操作所做的修改,其修改的数据都会存放在日志缓存区中,当事务提交时将redolog中的数据刷入磁盘中。
MyISAM 与 InnoDB 的区别

数据库隔离级别
答:MySQL的隔离级别主要有4个,读未提交,读已提交,可重复读,串行读等。
读已提交可以解决脏读问题,可重复读可以解决不可重复读问题,串行读可以解决幻读问题。
- “脏读”指读到了未提交的数据,然后基于这个数据做了一些事情,结果做完发现数据被回滚了。
- 不可重复读问题是,首先我们读取一条数据,然后我们再次读取这条数据时发现改数据已经被修改了(侧重点在修改)。
- 幻读:当某个事务在读取某个范围内的记录时,另一个事务又在该记录插入了新数据,当前事务再次读取这个范围的记录,会产生幻读行。
oss 数据库与 mysql 数据库不一致怎么解决
同一条 sql,不同规模数据会走同一条索引吗
答:不会,因为索引的失效原因有一条是:数据查询分布不均匀会导致索引失效。
为何会这样呢?因为MySQL优化器会评估使用索引的效率与走全表扫描的效率,如果走全表扫描更快,则放弃索引,走全表扫描。
索引是用来索引少量数据的,如果通过索引查询返回大批量的数据,则还不 如走全表扫描来的快,此时索引就会失效。
select * from tb_user where phone >= '17799990005';
select * from tb_user where phone >= '17799990015';mySQL 死锁怎么解决?mySQL 不能解决死锁的原因
死锁如何发生呢?
假设这时有两事务,一个事务要插入订单 1007 ,另外一个事务要插入订单 1008,因为需要对订单做幂等性校验,所以两个事务先要查询该订单是否存在,不存在才插入记录,过程如下:
两个临键锁相互锁住了对方,都在等对方释放。可以看到,两个事务都陷入了等待状态(前提没有打开死锁检测),也就是发生了死锁,因为都在相互等待对方释放锁。
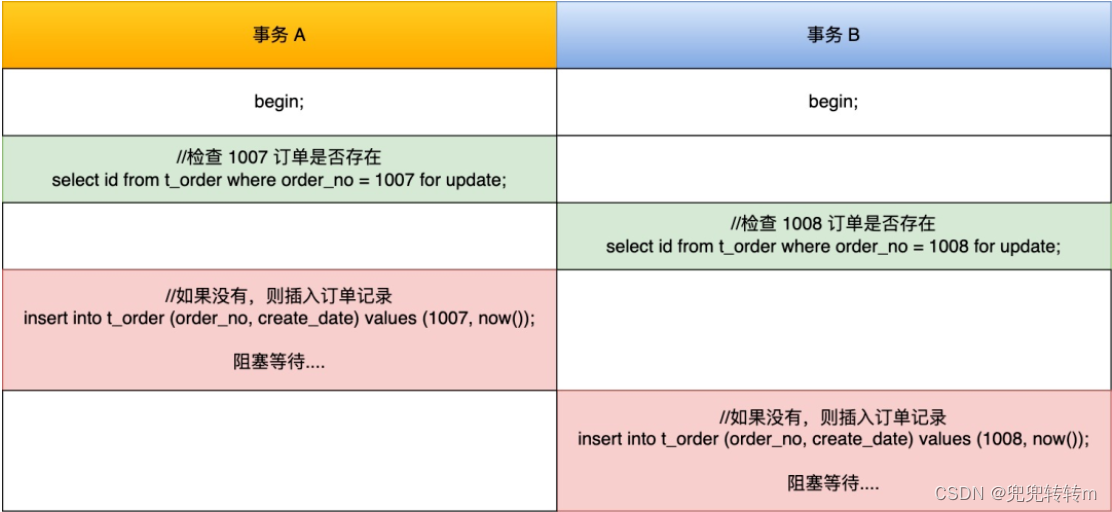
因为当我们执行以下插入语句时,会在插入间隙上获取插入意向写锁,而插入意向锁与间隙锁是冲突的,所以当其它事务持有该间隙的间隙锁时,需要等待其它事务释放间隙锁之后,才能获取到插入意向锁。而间隙锁与间隙锁之间是兼容的,所以所以两个事务中 select ... for update 语句并不会相互影响。
如何避免死锁?
死锁的四个必要条件:互斥、占有且等待、不可强占用、循环等待。只要系统发生死锁,这些条件必然成立,但是只要破坏任意一个条件就死锁就不会成立。
- 设置事务等待锁的超时时间:一个事务的等待时间超过该值后,就对这个事务进行回滚,于是锁就释放了,另一个事务就可以继续执行了
- 开启主动死锁检测。主动死锁检测在发现死锁后,主动回滚死锁链条中的某一个事务,让其他事务得以继续执行。将参数
innodb_deadlock_detect设置为 on,表示开启这个逻辑,默认就开启
参考:
慢 sql 优化
1、先检测出慢sql。
2、分析因为什么慢
具体:针对insert,order by,limit,update,conut,group by
综合问题
如何保证数据库和Redis的一致性问题。
最好是由开发者自己维护:由缓存调用者,在更新数据库的同时更新缓存。
那么假设我们每次操作数据库后,都操作缓存,但是中间如果没有人查询,那么这个更新动作实际上只有最后一次生效,中间的更新动作意义并不大,我们可以把缓存删除,等待再次查询时,将缓存中的数据加载出来。
-
删除缓存还是更新缓存?
-
更新缓存:每次更新数据库都更新缓存,无效写操作较多
-
删除缓存:更新数据库时让缓存失效,查询时再更新缓存
-
-
如何保证缓存与数据库的操作的同时成功或失败?
-
单体系统,将缓存与数据库操作放在一个事务
-
分布式系统,利用TCC等分布式事务方案
-
-
先操作缓存还是先操作数据库?
-
先删除缓存,再操作数据库
-
先操作数据库,再删除缓存
-
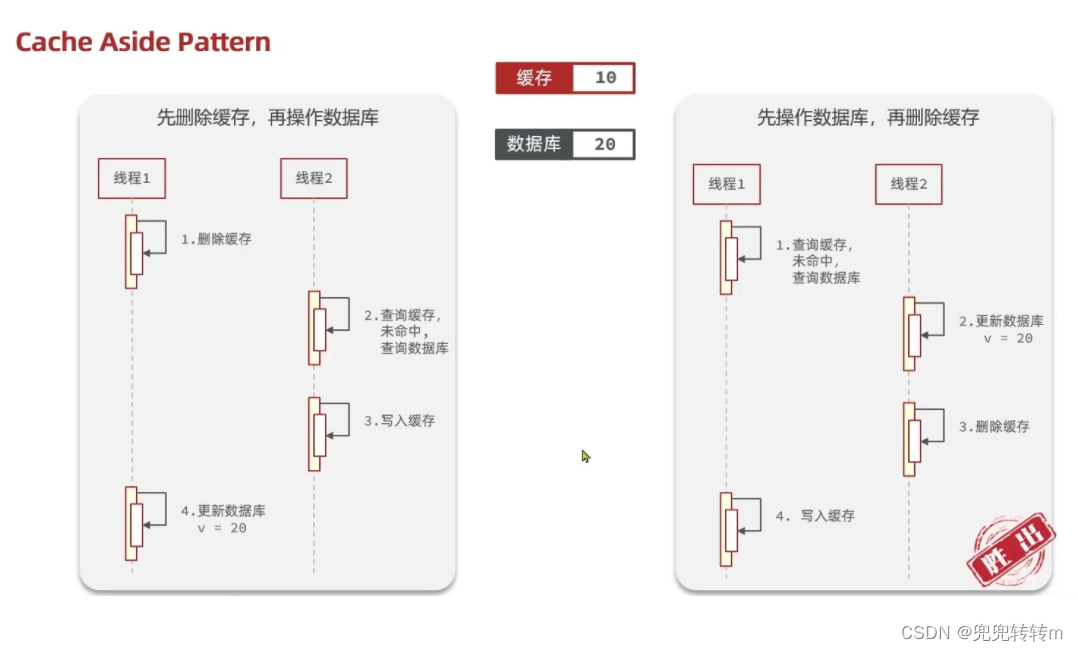
// 更新是要先查询数据库然后删除缓存
@Override
@Transactional
public Result update(Shop shop) {
// 1. 数值校验
Long id = shop.getId();
if (id == null) {
return Result.fail("店铺id不能为null");
}
// 更新数据库
selectById(id);
// 删除redis
template.delete(CACHE_SHOP_KEY + id);
return null;
}
















 1212
1212











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











