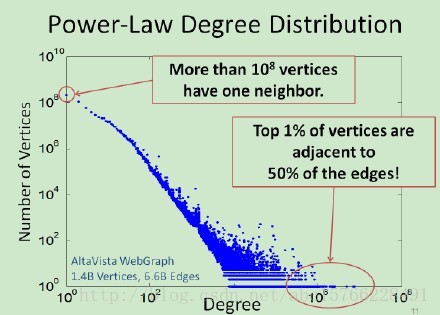
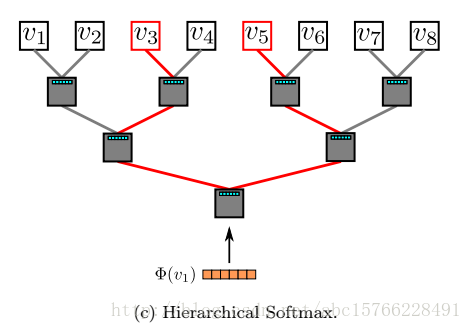
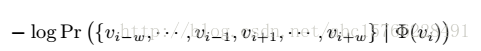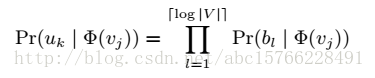论文题目:《DeepWalk: Online Learning of Social Representations》出版时间2014年6月 这篇文章是网络表示学习的经典文章,下面将简单介绍这篇文章的算法思想,如有不对的地方,欢迎指正!!!! 这篇论文提出的算法可以将网络中的节点用低维度,连续的向量表示,以便进行进一步机器学习 本文提出的算法的主要贡献有: 1、使用随机游走的方法学习到的顶点表示,会更加具有健壮性(robust) 2、deepwalk甚至可以在只给出部分网络的情况下,学习到更好的顶点表示 3、这种方法更加有利于并行化 定义: E⊆(V,E),这里V是网络的节点集合,E是边的集合,E⊆(V*V)。给出一个部分带标签的社区网络:G=(V,E,X,Y)。其中,X∈R^(|V|S),这里S是特征向量,就是每个点的特征数,Y∈R^(|V||y|)这里y是标签的集合(就是有几类)。我们的目标是学习一个XE∈R^(|V|*d)。这里d就是我们学习到的低维的隐藏的表示。这里的意思就是说,这里d维的向量中,包含了社区结构,我们可以通过这个向量进行进一步的训练和对整个社区的进一步的学习。 这个算法学习到的主要的优点有: 1、自适应性:在新的点加进来之后,不用重新学习。 2、社区表示性:向量相似的点,对应在网络中,被分在同一个类的几率比较大。 3、低维度性:产生低维的向量可以加速进一步的分类及其他问题的求解。 4、连续性:在连续的空间中的顶点表示,可以进一步增强分类的效果。 下面是一些相关的算法的基础 1、随机游走:定义,从根节点出发,随机游走的结果定义为向量Wvi,向量中的每个值是当前顶点随机选择的下一步的邻居。 2、幂率:如果在整个网络中的点遵循幂率分布,那么,在某个随机游走的点上也遵循幂率分布。 幂率科普(网上资源+个人理解)如下图:简单来说,就是,拥有大量的度数的点的数量是少的,拥有少量的度数的点的数量是多的,就是,好学生是少的,一般的学生是多的。。。。 3、语言模型:假设,有个文章,我们给出一个词序列:W=(w0,w1,……..,wn),我们在训练的时候要最大化这个概率:Pr(wn| w0,…,wn-1)。同样,放在随机游走的序列中,我们要最大化这个概率:Pr(Vi| (v1,v2,…,vi-1))。我们的目标是学习一个函数(隐含的表示方法)φ,这个φ对应一个点的d维表示,那么:上面的概率值可以表示为:Pr(Vi| (φ(v1),….,φ(vi-1))。但是,这个不太好最大化。于是,可以用以下方法:1、用文章预测缺失词,化为用词预测上下文;2、上下文对应于给出的词的左右两边;3、移除出现的词的顺序问题。最后,模型要求最大化一个词在上下文出现的概率,在没有给出词的情况下(就是说,输出一个向量,这个向量的每个概率表示这个向量的这个位置表示的词出现在这个位置的概率)。 最终,优化问题变成了最小化下面这个式子(个人理解,这里用log主要是将连乘变为连加,有利于优化): 最终产生的顶点的向量表示,由于随机游走,比较近的点游走到的概率比较大,在网络上比较相似的点的表示会比较相似,这样就可以用于其他机器学习算法了。 算法 DEEPWALK 这个算法由两个步骤组成:1、随机游走,2、更新步骤。 算法参数:一个图G(V,E),游走窗口大小w,产生的向量的长度(顶点表示的维度)d,对于每个点走的次数γ,走的长度t。 输出:一个顶点表示矩阵φ,大小为|V|*d 下面逐行介绍: 1:初始化φ 2:从V构建一个二叉树T(应该是用来做分层softmax的) 3-9是算法核心,外层循环代表了每个顶点产生多少个随机序列,内层循环表示对每个点产生一个Wi,并用SkipGram进行更新φ。 SkipGram 这个算法是语言模型中,最大化窗口w中出现的词的概率的方法(梯度下降),如上图所示 外层循环是对这个序列中的每个词进行操作,内层循环是对每个词的窗口大小为w的词序列进行操作。具体操作是用一个似然函数J(φ)表示φ,然后求导,用梯度下降的方法更新,(这个α应该是学习率)。 Hierarchical Softmax 由于直接计算概率Pr(uk|φ(vj))不好计算,因此,如果把顶点放在二叉树的叶子上,那么预测的问题,就变成了最大化下面这个概率 路径被定义为这样一个序列: 计算复杂度由O(|v|)变为O(log|v|),可以加速训练过程。 优化: 这里优化使用随机梯度下降(SGD),这里的学习率α一般为0.25,然后线性减少。 通俗来讲,v1在v3和v5之间,那么,hierarchical Softmax会计算Pr(v3|φ(v1)和Pr(v5|φ(v1))的概率,而φ则向着v1的上下文是v3和v5的“方向”更新。 Emmmmm算法部分基本就是这些啦,后面的算法变形和实验部分,就不贴出来了,这篇文章将自然语言处理中的word2vec的方法应用到了deepwalk的社交网络上,也算是经典论文了。

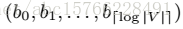 计算复杂度由O(|v|)变为O(log|v|),可以加速训练过程。
计算复杂度由O(|v|)变为O(log|v|),可以加速训练过程。
 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言