









目录
- 机器学习( M a c h i n e L e a r n i n g Machine Learning MachineLearning, M L ML ML)
- 一,基本术语
- 1.数据集( d a t a data data s e t set set) D D D
- 2.标记( l a b e l label label) y y y
- 3.训练( t r a i n i n g training training)
- 4.监督学习( s u p e r v i s e d supervised supervised l e a r n i n g learning learning)
- 5.无监督学习( u n s u p e r v i s e d unsupervised unsupervised l e a r n i n g learning learning)
- 6.归纳学习( i n d u c t i v e inductive inductive l e a r n i n g learning learning)
- 二,模型评估和选择
- (一)概念
- (二)评估方法
- 1.留出法( h o l d hold hold- o u t out out)
- 2.交叉验证法(cross validation)( k k k折交叉验证法, k k k- f o l d fold fold c r o s s cross cross v a l i d a t i o n validation validation)
- 3.留一法( l e a v e leave leave- o n e one one- o u t out out, L O O LOO LOO)
- 4.自助法( b o o t s t r a p p i n g bootstrapping bootstrapping)
- 5.调参
- (三)性能度量( p e r f o r m a n c e performance performance m e a s u r e measure measure)
- (四)偏差-方差分解( b i a s − v a r i a n c e bias-variance bias−variance d e c o m p o s i t i o n decomposition decomposition)
- (五)比较检验
- 三,归纳学习的分类领域
- 四,机器学习方法
- (一)传统机器学习方法
- 1.监督学习( s u p e r v i s e d supervised supervised l e a r n i n g learning learning)
- (1)线性回归( l i n e a r linear linear r e g r e s s i o n regression regression)
- (2)逻辑回归( l o g i s t i c logistic logistic r e g r e s s i o n regression regression)
- (3)决策树( d e c i s i o n decision decision t r e e tree tree)
- (4)支持向量机( s u p p o r t support support v e c t o r vector vector m a c h i n e machine machine, S V M SVM SVM)
- (5) k k k最近邻( k − n e a r e s t k-nearest k−nearest n e i g h b o r s neighbors neighbors, k − N N k-NN k−NN)
- (6)计算学习( c o m p u t a t i o n a l computational computational l e a r n i n g learning learning)
- (7)规则学习( r u l e rule rule l e a r n i n g learning learning)
- (8)生成式模型( g e n e r a t i v e generative generative m o d e l s models models)
- (9)集成学习( e n s e m b l e ensemble ensemble l e a r n i n g learning learning)
- 2.无监督学习( u n s u p e r v i s e d unsupervised unsupervised l e a r n i n g learning learning)
- 3. 半监督学习( s e m i − s u p e r v i s e d semi-supervised semi−supervised l e a r n i n g learning learning)
- (1)自训练( s e l f − t r a i n i n g self-training self−training)
- (2)协同训练( c o − t r a i n i n g co-training co−training)
- (3)标签传播( l a b e l label label p r o p a g a t i o n propagation propagation)
- (4)分布式共享表示( d i s t r i b u t e d distributed distributed s h a r e d shared shared r e p r e s e n t a t i o n s representations representations)
- 4.强化学习( r e i n f o r c e m e n t reinforcement reinforcement l e a r n i n g learning learning)
- 5.迁移学习( t r a n s f e r transfer transfer l e a r n i n g learning learning)
- (二)深度学习
- 五,其他概念
机器学习( M a c h i n e L e a r n i n g Machine Learning MachineLearning, M L ML ML)
机器学习所研究的主要内容:关于在计算机上从数据中产生模型( m o d e l model model)或学习器( l e a r n i n g learning learning)的算法,即学习算法( l e a r n i n g learning learning a l g o r i t h m algorithm algorithm)。
一,基本术语
1.数据集( d a t a data data s e t set set) D D D
D
=
{
x
⃗
1
,
x
⃗
2
,
…
,
x
⃗
m
}
D=\left\{\vec{x}_1,\vec{x}_2,…,\vec{x}_m\right\}
D={x1,x2,…,xm}
其中
x
⃗
i
\vec{x}_i
xi为数据集
D
D
D的第
i
i
i个示例(
i
n
s
t
a
n
c
e
instance
instance)或样本(
s
a
m
p
l
e
sample
sample),是关于一个事件或对象的描述
x
⃗
i
=
(
x
i
1
;
x
i
2
;
…
;
x
i
d
)
\vec{x}_i=(x_{i1};x_{i2};…;x_{id})
xi=(xi1;xi2;…;xid)
其中
d
d
d为样本
x
⃗
i
\vec{x}_i
xi的维度(
d
i
m
e
n
s
i
o
n
a
l
i
t
y
dimensionality
dimensionality),表示样本有
d
d
d个属性(
a
t
t
r
i
b
u
t
e
attribute
attribute)或特征(
f
e
a
t
u
r
e
feature
feature),其反映事件或对象在某方面的表现或性质的事项;
x
i
j
x_{ij}
xij是
x
⃗
i
\vec{x}_i
xi在第
j
j
j个属性上的属性值(
a
t
t
r
i
b
u
t
e
attribute
attribute
v
a
l
u
e
value
value)
属性值构成的空间为属性空间(
a
t
t
r
i
b
u
t
e
attribute
attribute
s
p
a
c
e
space
space)或样本空间(
s
a
m
p
l
e
sample
sample
s
p
a
c
e
space
space)或输入空间
χ
\chi
χ,可以认为
x
⃗
i
\vec{x}_i
xi是d维样本空间
χ
\chi
χ的特征向量(
f
e
a
t
u
r
e
feature
feature
v
e
c
t
o
r
vector
vector),
x
⃗
i
∈
χ
\vec{x}_i\in\chi
xi∈χ
2.标记( l a b e l label label) y y y
拥有了标记信息的示例,称为样例( e x a m p l e example example); ( x ⃗ i , y i ) (\vec{x}_i,y_i) (xi,yi)表示第 i i i个样例,其中 y i y_i yi为示例 x ⃗ i \vec{x}_i xi的标记;所有标记的集合为标记空间( l a b e l label label s p a c e space space)或输出空间 γ \gamma γ, y i ∈ γ y_i\in\gamma yi∈γ
若将标记看作对象本身的一部分,则“样例”有时也称为“样本”
3.训练( t r a i n i n g training training)
- 训练:从数据中学得模型的过程
- 训练示例(
t
r
a
i
n
train
train
i
n
s
t
a
n
c
e
instance
instance)或训练样本(
t
r
a
i
n
train
train
s
a
m
p
l
e
sample
sample)
x ⃗ i 或( x ⃗ i , y i ) \vec{x}_i或(\vec{x}_i,y_i) xi或(xi,yi) - 训练(数据)集(
t
r
a
i
n
train
train
s
e
t
set
set):用于训练模型的数据集
{ x ⃗ 1 , x ⃗ 2 , … , x ⃗ m } \left\{\vec{x}_1,\vec{x}_2,…,\vec{x}_m\right\} {x1,x2,…,xm}
或 { ( x ⃗ 1 , y 1 ) , ( x ⃗ 2 , y 2 ) , … , ( x ⃗ m , y m ) } \left\{(\vec{x}_1,y_1),(\vec{x}_2,y_2),…,(\vec{x}_m,y_m)\right\} {(x1,y1),(x2,y2),…,(xm,ym)}
4.监督学习( s u p e r v i s e d supervised supervised l e a r n i n g learning learning)
监督学习是处理拥有标记信息的训练数据的学习任务。
预测(
p
r
e
d
i
c
t
i
o
n
prediction
prediction)任务是希望通过对这种训练集进行学习,建立一个从输入空间
χ
\chi
χ到输出空间
γ
\gamma
γ的映射
f
f
f:
χ
↦
γ
\chi\mapsto\gamma
χ↦γ
- 学习任务——分类(
c
l
a
s
s
i
f
i
c
a
t
i
o
n
classification
classification):预测离散值
只有两个标记类别的学习任务为二分类( b i n a r y binary binary c l a s s i f i c a t i o n classification classification),其中一个类为正类( p o s i t i v e positive positive c l a s s class class),另一个类为反类或负类( n e g a t i v e negative negative c l a s s class class);常令 γ = { − 1 , + 1 } \gamma=\left\{ -1,+1\right\} γ={−1,+1}或 { 0 , 1 } \left\{ 0,1\right\} {0,1}
有多个标记类别的学习任务为多分类( m u l t i multi multi- c l a s s class class c l a s s i f i c a t i o n classification classification),常令 ∣ γ ∣ > 2 |\gamma|>2 ∣γ∣>2 - 学习任务——回归(
r
e
g
r
e
s
s
i
o
n
regression
regression):预测连续值
对于回归问题,常令 γ = R \gamma=R γ=R, R R R为常数集
学得模型后,使用其进行预测的过程为测试( t e s t i n g testing testing),被预测的样本为测试示例( t e s t i n g testing testing i n s t a n c e instance instance)或测试样本( t e s t i n g testing testing s a m p l e sample sample);即对于测试示例 x ⃗ \vec{x} x,对于预测映射 f f f,可得到其预测标记 y = f ( x ⃗ ) y=f(\vec{x}) y=f(x)
5.无监督学习( u n s u p e r v i s e d unsupervised unsupervised l e a r n i n g learning learning)
无监督学习是处理没有标记信息的训练数据的学习任务。
- 学习任务——聚类(
c
l
u
s
t
e
r
i
n
g
clustering
clustering):
将训练集中的样本分成若干组,每组称为一个簇( c l u s t e r cluster cluster),这些自动形成的簇可能对应一些潜在的概念划分;但这些概念事先是不知道的。 - 学习任务——降维
6.归纳学习( i n d u c t i v e inductive inductive l e a r n i n g learning learning)
学得模型适用于新样本的能力,称为泛化(
g
e
n
e
r
a
l
i
z
a
t
i
o
n
generalization
generalization)能力;具有强泛化能力的模型能很好地适用于整个样本空间。
归纳学习就是从样例中学习,是从特殊到一般的泛化过程,涵盖了监督学习,无监督学习等,也是学习算法的主要讨论对象。
“没有免费的午餐”定理(No Free Lunch Theorem,NFL定理)
脱离具体问题,空泛地谈论“什么学习算法更好”毫无意义,因为若考虑所有潜在的问题,则所有学习算法都一样好,期望性能相同。要谈论算法的相对优劣,必须要针对具体的学习问题;在某些问题上表现好的学习算法,在另些问题上却可能不尽如人意,学习算法自身的归纳偏好与问题是否相配,往往会起到决定性的作用
二,模型评估和选择
(一)概念
- 误差( e r r o r error error)(误差期望):学习器的实际预测输出与样本的真实输出之间的差异
- 训练误差( t r a i n i n g training training e r r o r error error)或经验误差( e m p i r i c a l empirical empirical e r r o r error error):学习器在训练集上的误差
- 泛化误差( g e n e r a l i z a t i o n generalization generalization e r r o r error error):学习器在新样本上的误差
- 欠拟合( u n d e r f i t t i n g underfitting underfitting):模型过于简单,未能很好地捕捉数据的复杂性,导致在训练数据和新数据上表现都不佳
- 过拟合( o v e r f i t t i n g overfitting overfitting):模型过于复杂,过度拟合了训练数据,导致在新数据上表现不佳
- 模型选择( m o d e l model model s e l e c t i o n selection selection):从多个可用的模型中选择最合适的模型,以获得最佳的性能和泛化能力
(二)评估方法
- 测试集( t e s t i n g testing testing s e t set set):用于最终评估模型性能的数据集,测试学习器对新样本的判别能力
- 测试误差( t e s t i n g testing testing e r r o r error error):测试集评估模型预测性能时所得到的模型预测与真实标签之间的差异或错误程度,期望作为泛化误差的近似
1.留出法( h o l d hold hold- o u t out out)
数据集
D
D
D划分为两个互斥的集合,即训练集
S
S
S和测试集
T
T
T,
D
=
S
∪
T
D=S \cup T
D=S∪T,
S
∩
T
=
∅
S\cap T=\varnothing
S∩T=∅;在S上训练模型,用T评估其测试误差,作为对泛化误差的估计;在使用留出法时,一般要采用若干次随机划分,重复进行实验评估后取平均值作为留出法的评估结果。
训练集
S
S
S和测试集
T
T
T的占比都不易过大或过小,否则会降低评估结果的保真性(
f
i
d
e
l
i
t
y
fidelity
fidelity);常见做法是将大约
2
3
∼
4
5
\frac{2}{3}\sim\frac{4}{5}
32∼54的样本用于训练,剩余样本用于测试。
- 采样( s a m p l i n g sampling sampling):从一个总体或总体中的子集中选择出一部分观察样本
- 分层采样( s t r a t i f i e d stratified stratified s a m p l e sample sample):将总体划分为若干层,并从每一层中独立地进行采样,以保证样本更好地代表总体的不同层次特征
- 保真性(fidelity):提供准确、可靠、真实反映原始数据或系统性能的能力
2.交叉验证法(cross validation)( k k k折交叉验证法, k k k- f o l d fold fold c r o s s cross cross v a l i d a t i o n validation validation)
数据集
D
D
D划分为
k
k
k个大小相似的互斥子集,即
D
=
D
1
∪
D
2
∪
…
∪
D
k
D=D_1\cup D_2\cup…\cup D_k
D=D1∪D2∪…∪Dk
D
i
∩
D
j
=
∅
(
i
≠
j
)
D_i\cap D_j=\varnothing(i\neq j)
Di∩Dj=∅(i=j)
每个子集
D
i
D_i
Di都尽可能保持数据分布的一致性,即从
D
D
D中通过分层采样得到。然后每次用
k
−
1
k-1
k−1个子集的并集作为训练集,另一个子集作为测试集;这样就可获得
k
k
k组训练/测试集,从而可进行
k
k
k次训练和测试,最终返回的是这
k
k
k个测试结果的均值
将数据集
D
D
D划分为
k
k
k个子集同样存在多种划分方式,为减少因样本划分不同而引入的差别,
k
k
k折交叉验证通常要随机使用不同的划分重复
p
p
p次,最终的评估结果是这
p
p
p次
k
k
k折交叉验证结果的均值
k k k最常用的取值是10,其他常用值有5,20
3.留一法( l e a v e leave leave- o n e one one- o u t out out, L O O LOO LOO)
假定数据集
D
D
D中包含
m
m
m个样本,留一法为
k
k
k折交叉验证法中
k
=
m
k=m
k=m的特例,即留一法只有一种划分方式
优点:留一法的训练集和初始数据集相比只少一个样本,故绝大多数情况下评估结果比较准确
缺点:数据集比较大时,计算开销过大
4.自助法( b o o t s t r a p p i n g bootstrapping bootstrapping)
自助采样法( b o o t s t r a p bootstrap bootstrap s a m p l i n g sampling sampling)(又称可重复采样,有放回采样):假设初始数据集 D D D包含 m m m个样本,有放回地随机等概率进行 m m m次采样,直到新产生的采样数据集 D ′ D' D′的大小与初始数据集相同。
若 m m m足够大,样本在 m m m次采样中始终不被采到的概率为
p = l i m m → ∞ ( 1 − 1 m ) m = 1 / e ≈ 0.368 p=lim_{m\rightarrow\infty} (1-\frac{1}{m})^m=1/e\approx0.368 p=limm→∞(1−m1)m=1/e≈0.368
通过自助采样,初始数据集
D
D
D中约有
36.8
36.8
36.8%的样本未出现在采样数据集
D
′
D'
D′中,于是我们可将
D
′
D'
D′用作训练集,
D
D
D\
D
′
D'
D′用作测试集。
这样实际评估的模型与期望评估的模型都使用m个训练样本,而仍有数据总量约
1
/
3
1/3
1/3的,没在训练集中出现的样本用于测试;这样的测试结果,也叫包外估计(
o
u
t
out
out-
o
f
of
of-
b
a
g
bag
bag
e
s
t
i
m
a
t
e
estimate
estimate)。
包外估计是一种用于评估随机森林等基于自助采样方法构建的模型性能的统计方法。在随机森林的训练过程中,由于自助采样法的有放回特性,部分样本可能在构建每棵树时没有被选中。这些未被选中的样本可以被用作包外样本( o u t out out- o f of of- b a g bag bag s a m p l e s samples samples)。
包外估计的原理如下:
- 对于每个样本,在构建随机森林时,大约有36.8%(约1/e)的样本没有被选中,这些样本被称为包外样本。
- 对于每个树,可以使用包外样本来评估该树的性能。使用包外样本进行预测,并将预测结果与真实标签进行比较,从而计算模型的误差。
- 对所有树的误差进行平均,得到包外估计的性能指标,例如准确率、F1得分等。
- 包外估计提供了对模型性能的无偏估计,因为它使用了未参与训练的样本进行评估。
包外估计是一种通过使用未被选中的样本来评估随机森林等模型性能的统计方法,可以提供无偏的模型性能估计,并且无需额外的验证集或交叉验证过程可以直接从训练过程中获得模型的性能估计;也使其成为一种简单而有效的模型选择和调参工具。
优点:适用于样本较少,难以有效划分训练/测试集的数据集;能从初始数据集中产生多个不同的训练集,有利于集成学习等方法
缺点:改变了初始数据集的分布,这会引入估计误差
5.调参
- 参数(
p
a
r
a
m
e
t
e
r
parameter
parameter):模型中可调整的变量,控制着模型的行为和性能,可分为模型参数和超参数(
h
y
p
e
r
p
a
r
a
m
e
t
e
r
hyperparameter
hyperparameter)
深度学习–超参数 - 调参( p a r a m e t e r parameter parameter t u n i n g tuning tuning):尝试不同的超参数组合来优化模型的性能,以使模型更好地适应数据并提高其泛化能力
- 验证集( v a l i d a t i o n validation validation s e t set set):用于模型选择和调参的数据集。在训练过程中,通过在验证集上评估模型的性能,可以选择不同的超参数、模型结构等进行调整,以提高模型的泛化能力。
通过在验证集上计算误差,可以比较不同模型或超参数设置之间的性能差异,并选择表现最佳的模型。但验证误差本质上是用于模型选择和调整的一种评估指标,而不是一个直接度量模型在真实世界中的性能的指标。
在研究对比不同算法的泛化性能时,用测试集上的判别效果来估计模型在实际使用时的泛化能力,而把训练数据另外划分为训练集和验证集
(三)性能度量( p e r f o r m a n c e performance performance m e a s u r e measure measure)
- 预测任务: D = { ( x ⃗ 1 , y 1 ) , ( x ⃗ 2 , y 2 ) , … , ( x ⃗ m , y m ) } D=\left\{(\vec{x}_1,y_1),(\vec{x}_2,y_2),…,(\vec{x}_m,y_m)\right\} D={(x1,y1),(x2,y2),…,(xm,ym)},其中 y i y_i yi为示例 x ⃗ i \vec{x}_i xi的真实标记。评估学习器 f f f的性能,即比较学习器预测结果 f ( x ⃗ ) f(\vec{x}) f(x)和真实标记 y y y。
- 回归任务:均方误差(
m
e
a
n
mean
mean
s
q
u
a
r
e
d
squared
squared
e
r
r
o
r
error
error,
M
S
E
MSE
MSE)
E ( f ; D ) = 1 m ∑ i = 1 m ( f ( x i ⃗ ) − y i ) 2 E(f;D)=\frac{1}{m}\sum_{i=1}^m (f(\vec{x_i})-y_i)^2 E(f;D)=m1i=1∑m(f(xi)−yi)2
其中 D D D为定样例集,即离散数据
E ( f ; D ~ ) = ∫ x ⃗ ∼ D ~ ( f ( x ⃗ ) − y ) 2 p ( x ⃗ ) d x ⃗ E(f;\tilde{D})=\int_{\vec{x}\sim\tilde{D}}(f(\vec{x})-y)^2 p(\vec{x})d\vec{x} E(f;D~)=∫x∼D~(f(x)−y)2p(x)dx
其中 D ~ \tilde{D} D~为数据分布,即连续数据, p ( ∗ ) p(*) p(∗)为概率密度函数 - 分类任务:如下
1.错误率和精度
- 错误率(
e
r
r
o
r
error
error
r
a
t
e
rate
rate):分类错误的样本数占样本总数的比例
E ( f ; D ) = 1 m ∑ i = 1 m I ( f ( x ⃗ i ) ≠ y i ) E(f;D)=\frac{1}{m}\sum_{i=1}^m\mathbb{I}(f(\vec{x}_i)\neq y_i) E(f;D)=m1i=1∑mI(f(xi)=yi)
E ( f ; D ~ ) = ∫ x ⃗ ∼ D ~ I ( f ( x ⃗ ) ≠ y ) p ( x ⃗ ) d x ⃗ E(f;\tilde{D})=\int_{\vec{x}\sim\tilde{D}}\mathbb{I}(f(\vec{x})\neq y)p(\vec{x})d\vec{x} E(f;D~)=∫x∼D~I(f(x)=y)p(x)dx - 精度(
a
c
c
u
r
a
c
y
accuracy
accuracy):分类正确的样本数占样本总数的比例
a c c ( f ; D ) = 1 m ∑ i = 1 m I ( f ( x ⃗ i ) = y i ) = 1 − E ( f ; D ) acc(f;D)=\frac{1}{m}\sum_{i=1}^m\mathbb{I}(f(\vec{x}_i)=y_i)=1-E(f;D) acc(f;D)=m1i=1∑mI(f(xi)=yi)=1−E(f;D)
a c c ( f ; D ~ ) = ∫ x ⃗ ∼ D ~ I ( f ( x ⃗ ) = y ) p ( x ⃗ ) d x ⃗ = 1 − E ( f ; D ~ ) acc(f;\tilde{D})=\int_{\vec{x}\sim\tilde{D}}\mathbb{I}(f(\vec{x})=y)p(\vec{x})d\vec{x}=1-E(f;\tilde{D}) acc(f;D~)=∫x∼D~I(f(x)=y)p(x)dx=1−E(f;D~)
I \mathbb{I} I为指示函数的数学符号表示,用来表示一个条件是否成立,如果条件成立,则返回 1 1 1;否则返回 0 0 0
2.查准率和查全率
- 查准率( P r e c i s i o n Precision Precision, P P P)(准确率):在所有被分类为正例的样本中,实际上是正例的比例
- 查全率( R e c a l l Recall Recall, R R R)(召回率,真正例率):在所有实际为正例的样本中,被正确分类为正例的比例
对于二分类问题,可将样例根据其真实类别与学习器预测类别的组合划分为真正例( t r u e true true p o s i t i v e positive positive, T P TP TP),假正例( f a l s e false false p o s i t i v e positive positive, F P FP FP),真反例( t r u e true true n e g a t i v e negative negative, T N TN TN),假反例( f a l s e false false n e g a t i v e negative negative, F N FN FN),则分类结果的混淆矩阵( c o n f u s i o n confusion confusion m a t r i x matrix matrix)如下:
| 真实情况 | 预测结果 | |
|---|---|---|
| 正例 | 反例 | |
| 正 | 真正例(TP) | 假反例(FN) |
| 反 | 假正例(FP) | 真反例(TN) |
P = T P T P + F P , R = T P T P + F N P=\frac{TP}{TP+FP},R=\frac{TP}{TP+FN} P=TP+FPTP,R=TP+FNTP
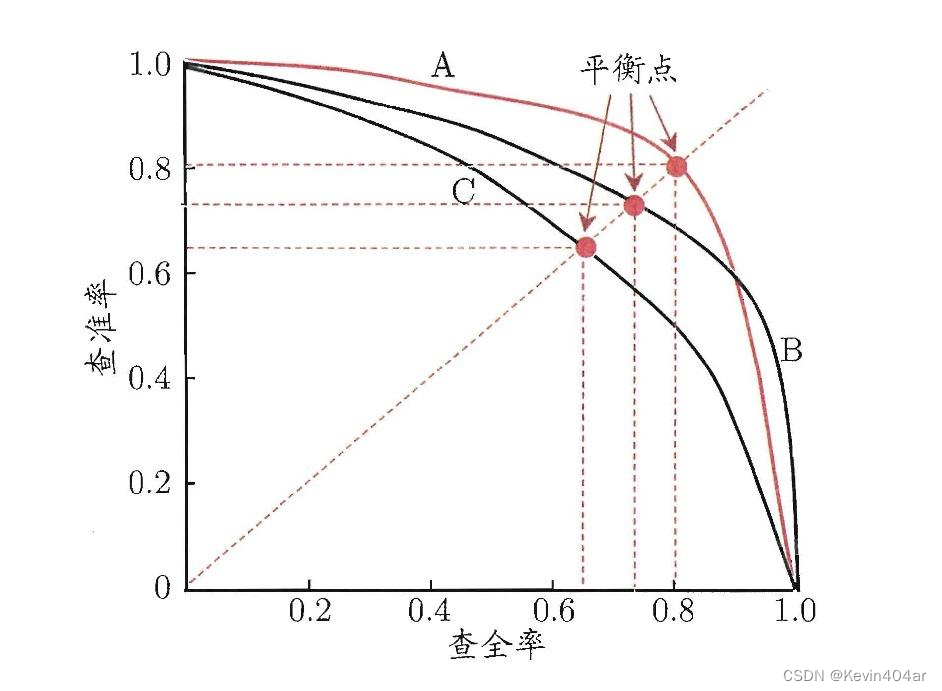
(1)平衡点( b r e a k break break- e v e n even even p o i n t point point, B E P BEP BEP)
如上为
P
−
R
P-R
P−R曲线,平衡点(
b
r
e
a
k
break
break-
e
v
e
n
even
even
p
o
i
n
t
point
point,
B
E
P
BEP
BEP)为
P
=
R
P=R
P=R时的取值,即此时
B
E
P
=
P
=
R
BEP=P=R
BEP=P=R;一般可以认为,BEP越高,学习器性能越好。
(2) F 1 F1 F1度量
F
1
F1
F1是基于查准率和查全率的调和平均定义的,
m
m
m为样例总数
1
F
1
=
1
2
(
1
P
+
1
R
)
\frac{1}{F1}=\frac{1}{2}(\frac{1}{P}+\frac{1}{R})
F11=21(P1+R1)
F
1
=
2
P
R
P
+
R
=
2
T
P
m
+
T
P
−
T
N
F1=\frac{2PR}{P+R}=\frac{2TP}{m+TP-TN}
F1=P+R2PR=m+TP−TN2TP
(3) F β F_\beta Fβ度量
F
β
F_\beta
Fβ是基于查准率和查全率的加权调和平均定义的,用以对查准率和查全率的不同偏好
1
F
β
=
1
1
+
β
2
(
1
P
+
β
2
R
)
\frac{1}{F_\beta}=\frac{1}{1+\beta^2}(\frac{1}{P}+\frac{\beta^2}{R})
Fβ1=1+β21(P1+Rβ2)
F
β
=
(
1
+
β
2
)
P
R
β
2
P
+
R
F_\beta=\frac{(1+\beta^2)PR}{\beta^2P+R}
Fβ=β2P+R(1+β2)PR
其中
β
>
0
\beta>0
β>0度量了查全率对查准率的相对重要性。
β
=
1
\beta=1
β=1即为标准的F1,
β
>
1
\beta>1
β>1时查全率有更大影响,
β
<
1
\beta<1
β<1时查准率有更大影响。
例如在商品推荐系统中,查准率更重要;在逃犯信息检索系统中,查全率更重要
(4)宏 F 1 F1 F1和微 F 1 F1 F1
在 n n n个二分类混淆矩阵上综合考察查准率和查全率,则
- 先计算再平均
P i = T P i T P i + F P i , R i = T P i T P i + F N i , i = 1 , 2 , … , n P_i=\frac{TP_i}{TP_i+FP_i},R_i=\frac{TP_i}{TP_i+FN_i},i=1,2,…,n Pi=TPi+FPiTPi,Ri=TPi+FNiTPi,i=1,2,…,n
m a c r o − P = 1 n ∑ i = 1 n P i , m a c r o − R = 1 n ∑ i = 1 n R i macro-P=\frac{1}{n}\sum_{i=1}^nP_i,macro-R=\frac{1}{n}\sum_{i=1}^nR_i macro−P=n1i=1∑nPi,macro−R=n1i=1∑nRi
m a c r o − F 1 = 2 × ( m a c r o − P ) × ( m a c r o − R ) ( m a c r o − P ) + ( m a c r o − R ) macro-F1=\frac{2\times (macro-P)\times (macro-R)}{(macro-P)+(macro-R)} macro−F1=(macro−P)+(macro−R)2×(macro−P)×(macro−R) - 先平均再计算
T P ‾ = 1 n ∑ i = 1 n T P i , F P ‾ = 1 n ∑ i = 1 n F P i , F N ‾ = 1 n ∑ i = 1 n F N i \overline{TP}=\frac{1}{n}\sum_{i=1}^nTP_i,\overline{FP}=\frac{1}{n}\sum_{i=1}^nFP_i,\overline{FN}=\frac{1}{n}\sum_{i=1}^nFN_i TP=n1i=1∑nTPi,FP=n1i=1∑nFPi,FN=n1i=1∑nFNi
m i c r o − P = T P ‾ T P ‾ + F P ‾ , m i c r o − R = T P ‾ T P ‾ + F N ‾ micro-P=\frac{\overline{TP}}{\overline{TP}+\overline{FP}},micro-R=\frac{\overline{TP}}{\overline{TP}+\overline{FN}} micro−P=TP+FPTP,micro−R=TP+FNTP
m i c r o − F 1 = 2 × ( m i c r o − P ) × ( m i c r o − R ) ( m i c r o − P ) + ( m i c r o − R ) micro-F1=\frac{2\times (micro-P)\times (micro-R)}{(micro-P)+(micro-R)} micro−F1=(micro−P)+(micro−R)2×(micro−P)×(micro−R)
其中 m a c r o − P macro-P macro−P为宏查准率, m a c r o − R macro-R macro−R为宏查全率, m a c r o − F 1 macro-F1 macro−F1为宏F1, m i c r o − P micro-P micro−P为微查准率, m i c r o − R micro-R micro−R为微查全率, m i c r o − F 1 为微 F 1 micro-F1为微F1 micro−F1为微F1
3. R O C 曲线 ROC曲线 ROC曲线和 A U C AUC AUC
- 分类阈值( t h r e s h o l d threshold threshold):将产生的预测值与分类阈值进行比较,大于阈值则分为正类,否则为反类
- 截断点( c u t cut cut p o i n t point point):先将测试样本进行排序,“最可能”是正例的样本排在最前面,“最不可能”是正例的样本排在最后面,以截断点将样本分成两部分,前一部分判作正例,后一部分判作反例
将连续的输出值转换为离散的类别标签,需要根据具体问题和需求进行选择
| 真实情况 | 预测结果 | |
|---|---|---|
| 正例 | 反例 | |
| 正 | 真正例(TP) | 假反例(FN) |
| 反 | 假正例(FP) | 真反例(TN) |
- 真正例率(
t
r
u
e
true
true
p
o
s
i
t
i
v
e
positive
positive
r
a
t
e
rate
rate,
T
P
R
TPR
TPR):被正确地预测为正例的样本在正例样本中的比例
T P R = T P T P + F N TPR=\frac{TP}{TP+FN} TPR=TP+FNTP
真正例率和查全率计算方式完全一样
- 假正例率(
f
a
l
s
e
false
false
p
o
s
i
t
i
v
e
positive
positive
r
a
t
e
rate
rate,
F
P
R
FPR
FPR):被错误地预测为正例的样本在反例样本中的比例
F P R = F P T N + F P FPR=\frac{FP}{TN+FP} FPR=TN+FPFP - 真反例率(
t
r
u
e
true
true
n
e
g
a
t
i
v
e
negative
negative
r
a
t
e
rate
rate,
T
N
R
TNR
TNR):被正确地预测为反例的样本在反例样本中的比例
T N R = T N T N + F P = 1 − F P R TNR=\frac{TN}{TN+FP}=1-FPR TNR=TN+FPTN=1−FPR - 假反例率(
f
a
l
s
e
false
false
n
e
g
a
t
i
v
e
negative
negative
r
a
t
e
rate
rate,
F
N
R
FNR
FNR):被错误地预测为反例的样本在正例样本中的比例
F N R = F N T P + F N = 1 − T P R FNR=\frac{FN}{TP+FN}=1-TPR FNR=TP+FNFN=1−TPR -
R
O
C
ROC
ROC:全称为受试者工作特征(
r
e
c
e
i
v
i
n
g
receiving
receiving
o
p
e
r
a
t
i
n
g
operating
operating
c
h
a
r
a
c
t
e
r
i
s
t
i
c
characteristic
characteristic),
R
O
C
ROC
ROC曲线为
T
P
R
−
F
P
R
TPR-FPR
TPR−FPR曲线,即仅讨论正例率
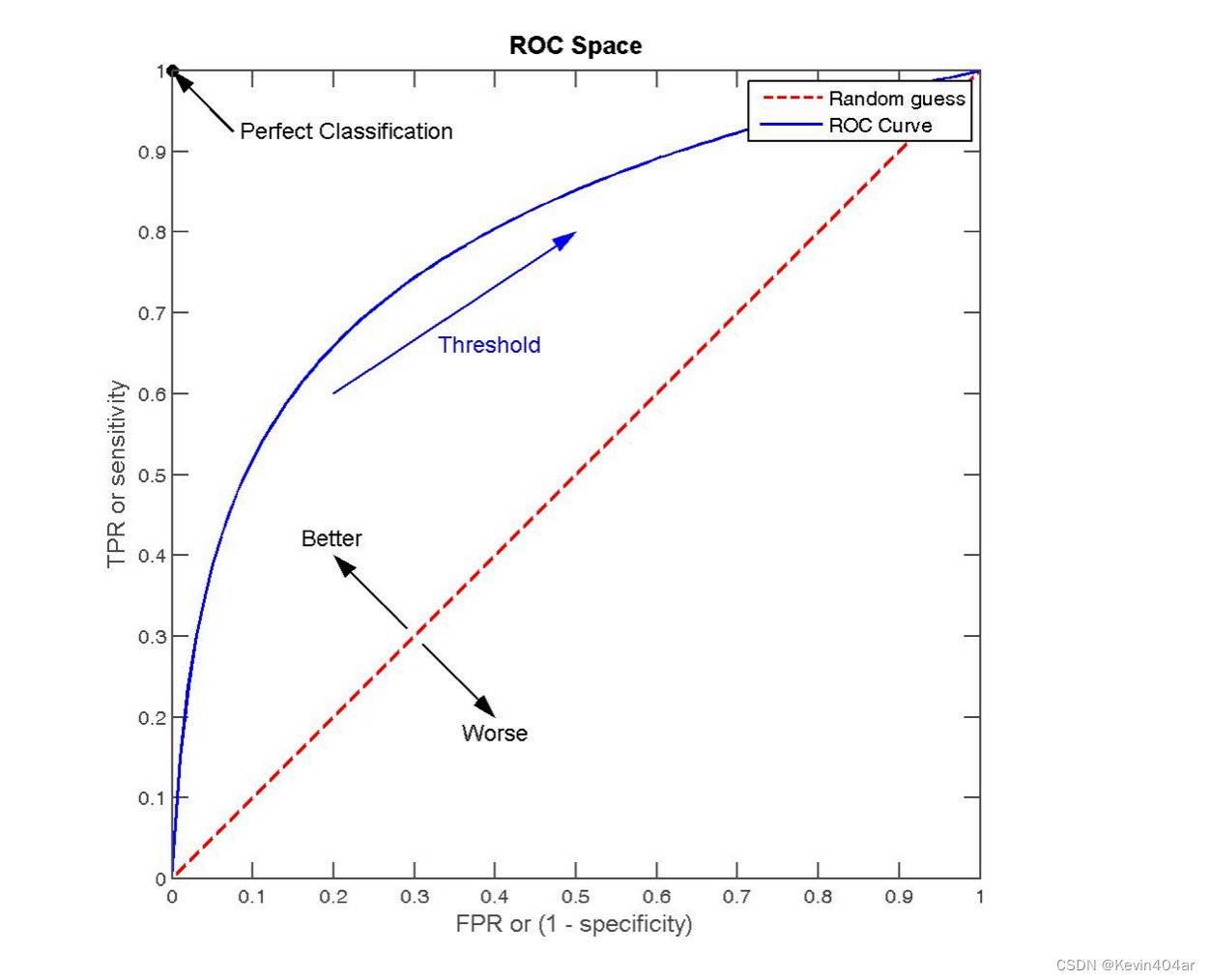
对角线对应于“随机猜测”模型,点(0,1)对应于将所有正例排在所有反例之前的“理想模型”; -
A
U
C
AUC
AUC(
a
r
e
a
area
area
u
n
d
e
r
under
under
c
u
r
v
e
curve
curve):此处即为
R
O
C
ROC
ROC曲线下的面积,其考虑的是样本预测的排序质量;一般可以认为,
A
U
C
AUC
AUC越高,学习器性能越好;在有限个测试样例中,可估算为:
A U C = 1 2 ∑ i = 1 m − 1 ( x i + 1 − x i ) ( y i + y i + 1 ) AUC=\frac{1}{2}\sum_{i=1}^{m-1}(x_{i+1}-x_i)(y_i+y_{i+1}) AUC=21i=1∑m−1(xi+1−xi)(yi+yi+1) - 排序损失(
r
a
n
k
rank
rank
l
o
s
s
loss
loss):
l r a n k = 1 m + m − ∑ x + ϵ D + ∑ x − ϵ D − ( I ( f ( x + ) < f ( x − ) ) + 1 2 I ( f ( x + ) = f ( x − ) ) ) l_{rank}=\frac{1}{m^+m^-}\sum_{x^+\epsilon D^+}\sum_{x^-\epsilon D^-}(\mathbb{I}(f(x^+)<f(x^-))+\frac{1}{2}\mathbb{I}(f(x^+)=f(x^-))) lrank=m+m−1x+ϵD+∑x−ϵD−∑(I(f(x+)<f(x−))+21I(f(x+)=f(x−)))
A U C = 1 − l r a n k AUC=1-l_{rank} AUC=1−lrank
其中 m + m^+ m+为正例数, m − m^- m−为反例数, D + D^+ D+为正例集合, D − D^- D−为反例集合;易得 l r a n k l_{rank} lrank对应的是 R O C ROC ROC曲线之上的面积
4.代价敏感错误率和代价曲线
- 非均等代价( u n e q u a l unequal unequal c o s t cost cost):在不同情况下,不同决策或行动所带来的成本或效益不同的情况
例如医疗诊断中,错误地把患者诊断为健康人和错误地把健康人诊断为患者,代价并不一样
- 代价矩阵( c o s t cost cost m a t r i x matrix matrix)
| 真实类别 | 预测类型 | |
|---|---|---|
| 第0类 | 第1类 | |
| 第0类 | 0 | cost_01 |
| 第1类 | cost_10 | 0 |
其中, c o s t i j cost_{ij} costij表示将第 i i i类样本预测为第 j j j类样本的代价;一般 c o s t i i = 0 cost_{ii}=0 costii=0
- 总体代价( t o t a l total total c o s t cost cost):在决策或行动过程中,考虑到所有相关因素和成本,综合评估并计算出的总体成本
- 代价敏感错误率(
c
o
s
t
−
s
e
n
s
i
t
i
v
e
cost-sensitive
cost−sensitive
e
r
r
o
r
error
error
r
a
t
e
rate
rate):在分类问题中的评估指标,考虑了不同类别的错误分类所带来的不同代价和成本
E ( f ; D ; c o s t ) = 1 m ( ∑ x i ϵ D + I ( f ( x i ) ≠ y ) × c o s t 01 + ∑ x i ϵ D − I ( f ( x i ) ≠ y ) × c o s t 10 ) E(f;D;cost)=\frac{1}{m}(\sum_{x_i\epsilon D^+}\mathbb{I}(f(x_i)\neq y)\times cost_{01}+\sum_{x_i\epsilon D^-}\mathbb{I}(f(x_i)\neq y)\times cost_{10}) E(f;D;cost)=m1(xiϵD+∑I(f(xi)=y)×cost01+xiϵD−∑I(f(xi)=y)×cost10) - 正例概率代价(
p
o
s
i
t
i
v
e
positive
positive
p
r
o
b
a
b
i
l
i
t
y
probability
probability
c
o
s
t
cost
cost):一种损失函数,通过对错误分类的正例进行更严重的惩罚,以提高模型对正例的识别能力;取值为
[
0
,
1
]
[0,1]
[0,1]的正例概率代价如下,其中
p
p
p是样例为正例的概率:
P c o s t + = p × c o s t 01 p × c o s t 01 + ( 1 − p ) × c o s t 10 P^+_{cost}=\frac{p\times cost_{01}}{p\times cost_{01}+(1-p)\times cost_{10}} Pcost+=p×cost01+(1−p)×cost10p×cost01
正例概率代价可以用于改善如欺诈检测、罕见疾病诊断等不平衡数据集的分类任务
- 归一化代价(
n
o
r
m
a
l
i
z
e
d
normalized
normalized
c
o
s
t
cost
cost):将不同类型代价的范围映射到相同的尺度上,以便能够进行比较和权衡;此处针对代价矩阵的,取值为
[
0
,
1
]
[0,1]
[0,1]的归一化代价如下:
c o s t n o r m = F N R × p × c o s t 01 + F P R × ( 1 − p ) × c o s t 10 p × c o s t 01 + ( 1 − p ) × c o s t 10 cost_{norm}=\frac{FNR\times p\times cost_{01}+FPR\times (1-p)\times cost_{10}}{p\times cost_{01}+(1-p)\times cost_{10}} costnorm=p×cost01+(1−p)×cost10FNR×p×cost01+FPR×(1−p)×cost10
其中, F N R FNR FNR为假反利率, F P R FPR FPR为假正例率,计算方式见前文 - 代价曲线(
c
o
s
t
cost
cost
c
u
r
v
e
curve
curve)或代价效益曲线(
c
o
s
t
−
e
f
f
e
c
t
i
v
e
n
e
s
s
cost-effectiveness
cost−effectiveness
c
u
r
v
e
curve
curve)
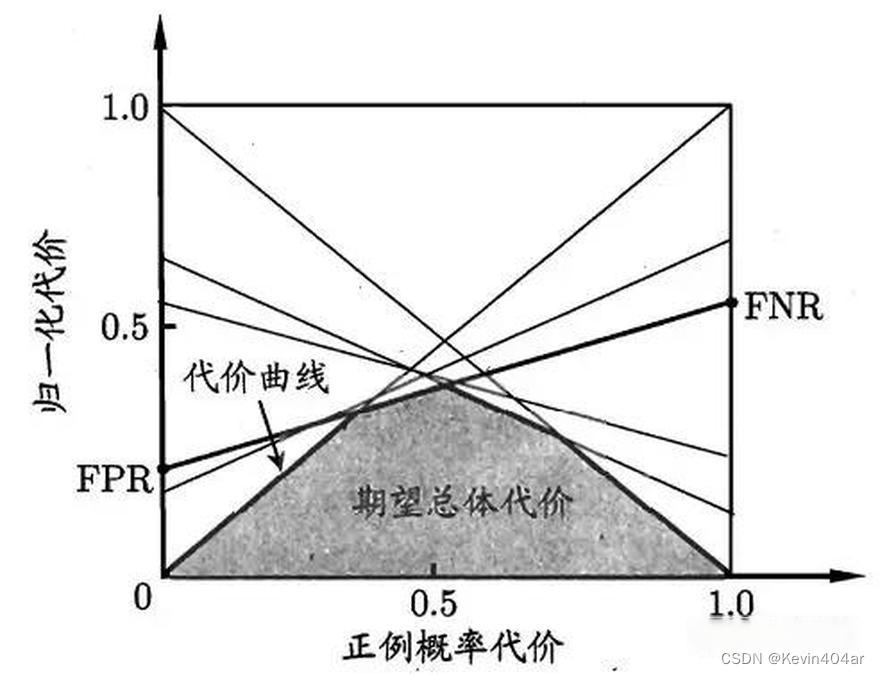
曲线图的横轴是取值为 [ 0 , 1 ] [0,1] [0,1]的正例概率代价,纵轴是取值为 [ 0 , 1 ] [0,1] [0,1]的归一化代价
取 R O C ROC ROC上的一个点,点坐标即为 ( F P R , T P R ) (FPR,TPR) (FPR,TPR),可得 F N R = 1 − T P R FNR=1-TPR FNR=1−TPR,从而可在代价平面上得到 ( 0 , F P R ) (0,FPR) (0,FPR)到 ( 1 , F N R ) (1,FNR) (1,FNR)的线段,线段下围成的面积表示该条件下的期望总体代价;取 R O C ROC ROC上的所有点,所有线段下界围成的面积表示在所有条件下学习器的期望总体代价
(四)偏差-方差分解( b i a s − v a r i a n c e bias-variance bias−variance d e c o m p o s i t i o n decomposition decomposition)
1.期望预测输出
对于训练集
D
D
D,测试样本
x
⃗
\vec{x}
x,令
y
y
y为
x
⃗
\vec{x}
x的真实标记,
y
D
y_D
yD为
x
⃗
\vec{x}
x在数据集中的标记(噪音使得
y
D
≠
y
y_D\neq y
yD=y),
f
(
x
;
D
)
f(x;D)
f(x;D)为训练集
D
D
D上学得模型
f
f
f在
x
⃗
\vec{x}
x上的预测输出;在回归任务中,学习算法的期望预测输出为
f
ˉ
(
x
)
=
E
D
[
f
(
x
;
D
)
]
\bar{f}(x)=E_D[f(x;D)]
fˉ(x)=ED[f(x;D)]
2.偏差( b i a s bias bias)
偏差为期望预测输出与真实标记的差别,是由模型对真实关系的错误假设引起的误差
高偏差意味着模型对真实关系的拟合能力较差,容易产生欠拟合,其模型倾向于过于简单,无法捕捉数据的复杂性。
b
i
a
s
(
x
⃗
)
=
f
ˉ
(
x
)
−
y
bias(\vec{x})=\bar{f}(x)-y
bias(x)=fˉ(x)−y
3.方差( v a r i a n c e variance variance)
方差是由模型对训练数据的敏感性引起的误差
高方差意味着模型对训练数据过度拟合,无法泛化到新的数据集,其模型过于复杂,对数据中的噪声过于敏感。
使用样本数相同的不同训练集产生的方差为:
v
a
r
(
x
⃗
)
=
E
D
[
(
f
(
x
;
D
)
−
f
ˉ
(
x
)
)
2
]
var(\vec{x})=E_D[(f(x;D)-\bar{f}(x))^2]
var(x)=ED[(f(x;D)−fˉ(x))2]
4.噪声(voice)
噪声就是不可避免的误差(Irreducible Error),是数据中的无关或错误信息,是由数据本身或不可预测的因素引起的误差,可能会干扰模型的学习和预测过程;这部分误差无法通过改进模型来减少。
ϵ
2
=
E
D
[
(
y
D
−
y
)
2
]
\epsilon^2=E_D[(y_D-y)^2]
ϵ2=ED[(yD−y)2]
5.泛化误差的分解
泛化误差可分解为偏差,方差和噪声之和;对于基于均方误差的回归问题:
E
(
f
;
D
)
=
E
D
[
b
i
a
s
2
(
x
⃗
)
]
+
E
D
[
v
a
r
(
x
⃗
)
]
+
E
D
[
ϵ
2
]
E(f;D)=E_D[bias^2(\vec{x})]+E_D[var(\vec{x})]+E_D[\epsilon^2]
E(f;D)=ED[bias2(x)]+ED[var(x)]+ED[ϵ2]
推理过程:
假定噪声期望为
0
0
0,即
E
D
[
y
D
−
y
]
=
0
E_D[y_D-y]=0
ED[yD−y]=0,有
E
(
f
;
D
)
=
E
D
[
(
f
(
x
;
D
)
−
y
D
)
2
]
E(f;D)=E_D[(f(x;D)-y_D)^2]
E(f;D)=ED[(f(x;D)−yD)2]
=
E
D
[
(
f
(
x
;
D
)
−
f
ˉ
(
x
)
+
f
ˉ
(
x
)
−
y
D
)
2
]
=E_D[(f(x;D)-\bar{f}(x)+\bar{f}(x)-y_D)^2]
=ED[(f(x;D)−fˉ(x)+fˉ(x)−yD)2]
=
E
D
[
(
f
(
x
;
D
)
−
f
ˉ
(
x
)
)
2
]
+
E
D
[
(
f
ˉ
(
x
)
−
y
D
)
2
]
+
E
D
[
2
(
f
(
x
;
D
)
−
f
ˉ
(
x
)
)
(
f
ˉ
(
x
)
−
y
D
)
]
=E_D[(f(x;D)-\bar{f}(x))^2]+E_D[(\bar{f}(x)-y_D)^2]+E_D[2(f(x;D)-\bar{f}(x))(\bar{f}(x)-y_D)]
=ED[(f(x;D)−fˉ(x))2]+ED[(fˉ(x)−yD)2]+ED[2(f(x;D)−fˉ(x))(fˉ(x)−yD)]
=
E
D
[
(
f
(
x
;
D
)
−
f
ˉ
(
x
)
)
2
]
+
E
D
[
(
f
ˉ
(
x
)
−
y
D
)
2
]
=E_D[(f(x;D)-\bar{f}(x))^2]+E_D[(\bar{f}(x)-y_D)^2]
=ED[(f(x;D)−fˉ(x))2]+ED[(fˉ(x)−yD)2]
=
E
D
[
(
f
(
x
;
D
)
−
f
ˉ
(
x
)
)
2
]
+
E
D
[
(
f
ˉ
(
x
)
−
y
+
y
−
y
D
)
2
]
=E_D[(f(x;D)-\bar{f}(x))^2]+E_D[(\bar{f}(x)-y+y-y_D)^2]
=ED[(f(x;D)−fˉ(x))2]+ED[(fˉ(x)−y+y−yD)2]
=
E
D
[
(
f
(
x
;
D
)
−
f
ˉ
(
x
)
)
2
]
+
E
D
[
(
f
ˉ
(
x
)
−
y
)
2
]
+
E
D
(
y
−
y
D
)
2
]
+
E
D
[
2
(
f
ˉ
(
x
)
−
y
)
(
y
−
y
D
)
]
=E_D[(f(x;D)-\bar{f}(x))^2]+E_D[(\bar{f}(x)-y)^2]+E_D(y-y_D)^2]+E_D[2(\bar{f}(x)-y)(y-y_D)]
=ED[(f(x;D)−fˉ(x))2]+ED[(fˉ(x)−y)2]+ED(y−yD)2]+ED[2(fˉ(x)−y)(y−yD)]
=
E
D
[
(
f
(
x
;
D
)
−
f
ˉ
(
x
)
)
2
]
+
E
D
[
(
f
ˉ
(
x
)
−
y
)
2
]
+
E
D
(
y
−
y
D
)
2
]
=E_D[(f(x;D)-\bar{f}(x))^2]+E_D[(\bar{f}(x)-y)^2]+E_D(y-y_D)^2]
=ED[(f(x;D)−fˉ(x))2]+ED[(fˉ(x)−y)2]+ED(y−yD)2]
=
E
D
[
b
i
a
s
2
(
x
⃗
)
]
+
E
D
[
v
a
r
(
x
⃗
)
]
+
E
D
[
ϵ
2
]
=E_D[bias^2(\vec{x})]+E_D[var(\vec{x})]+E_D[\epsilon^2]
=ED[bias2(x)]+ED[var(x)]+ED[ϵ2]
6.偏差-方差窘境( b i a s − v a r i a n c e bias-variance bias−variance t r a d e o f f tradeoff tradeoff)
偏差-方差窘境指的是在机器学习中,降低模型的偏差和方差是一种权衡。当降低模型的偏差时,通常会增加模型的复杂度,从而增加了方差。相反,降低方差可能会导致模型的偏差增加。要在偏差和方差之间找到一个平衡点,以使模型具有良好的拟合能力和泛化能力。
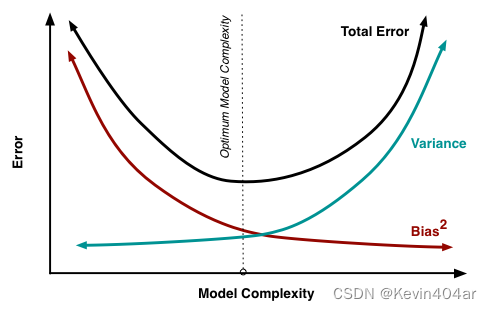
- 解决偏差-方差窘境的方法包括:
- 增加模型复杂度:通过增加模型的容量,例如增加神经网络的隐藏层的数量或节点数,可以减小偏差,但可能会增加方差。
- 减少模型复杂度:通过减少模型的复杂度,例如减少神经网络的隐藏层的数量或节点数,可以减小方差,但可能会增加偏差。
- 正则化:通过添加正则化项来控制模型的复杂度,例如L1正则化或L2正则化,可以在一定程度上同时减小偏差和方差。
- 数据增强:通过增加训练数据的多样性,例如旋转、平移、缩放等操作,可以减小方差,帮助模型更好地泛化到新的数据。
- 集成学习:通过结合多个不同模型的预测结果,例如随机森林、梯度提升树等方法,可以减小方差,提高模型的泛化能力。
(五)比较检验
三,归纳学习的分类领域
(一)符号主义学习
1.决策树
2.基于逻辑的学习——归纳逻辑程序设计( I n d u c t i v e Inductive Inductive L o g i c Logic Logic P r o g r a m m i n g Programming Programming, I L P ILP ILP)
由于表示能力太强,直接导致学习过程面临的假设空间太大,复杂度极高。因此问题规模稍大就难以有效进行学习
(二)连接主义学习(基于神经网络的黑箱模型)
1.反向传播( B a c k P r o p a g a t i o n BackPropagation BackPropagation, B P BP BP)算法
2.深度学习
其学习过程涉及大量参数,而参数的设置缺乏理论指导,主要靠手工调参,试错性太高
(三)统计学习
1.支持向量机( S u p p o r t Support Support V e c t o r Vector Vector M a c h i n e Machine Machine, S V M SVM SVM)
2.核方法
四,机器学习方法
(一)传统机器学习方法
传统的机器学习方法通常基于统计学和概率理论,通过从训练数据中学习模型的参数或规则,以进行预测、分类、聚类等任务。
1.监督学习( s u p e r v i s e d supervised supervised l e a r n i n g learning learning)
通过给定输入数据和相应的标签或目标输出来训练模型,建立一个函数来预测新的输入数据的标签,来学习输入和输出之间的关系
(1)线性回归( l i n e a r linear linear r e g r e s s i o n regression regression)
用于建立连续输出变量与输入变量之间的线性关系。
(2)逻辑回归( l o g i s t i c logistic logistic r e g r e s s i o n regression regression)
用于建立二分类或多分类模型,可以用于预测离散的输出变量。
(3)决策树( d e c i s i o n decision decision t r e e tree tree)
通过对特征进行逐步划分,构建一个树状模型,用于分类和回归任务。
(4)支持向量机( s u p p o r t support support v e c t o r vector vector m a c h i n e machine machine, S V M SVM SVM)
通过将数据映射到高维空间,找到一个最优的超平面来进行分类或回归。
(5) k k k最近邻( k − n e a r e s t k-nearest k−nearest n e i g h b o r s neighbors neighbors, k − N N k-NN k−NN)
基于实例,通过计算输入样本与训练集中k个最近邻样本的距离来进行分类或回归预测
KNN算法可以用于监督学习任务中的分类问题,也可以用于无监督学习任务中的聚类问题。
(6)计算学习( c o m p u t a t i o n a l computational computational l e a r n i n g learning learning)
通过计算方法和算法实现对数据的学习和预测
(7)规则学习( r u l e rule rule l e a r n i n g learning learning)
通过从数据中提取规则或条件,用于预测或分类新的未知数据
(8)生成式模型( g e n e r a t i v e generative generative m o d e l s models models)
通过建立数据的生成概率模型来对数据进行建模和预测
- 朴素贝叶斯(
n
a
i
v
e
naive
naive
b
a
y
e
s
bayes
bayes)
基于贝叶斯定理和特征条件独立性假设,通过计算后验概率来预测输入数据的类别,并假设所有特征之间是独立的;用于分类任务 - 高斯混合模型(
g
a
u
s
s
i
a
n
gaussian
gaussian
g
i
x
t
u
r
e
gixture
gixture
m
o
d
e
l
s
models
models,
G
M
M
GMM
GMM)
基于高斯分布,假设数据是由多个高斯分布组成的,通过最大化似然函数来估计模型参数;用于聚类、异常检测等任务 - 隐马尔可夫模型(
h
i
d
d
e
n
hidden
hidden
m
a
r
k
o
v
markov
markov
m
o
d
e
l
s
models
models,
H
M
M
HMM
HMM)
假设系统的状态是一个隐藏的马尔可夫链,并通过观测数据来推断系统的状态,建模具有隐含状态的序列数据 - 受限玻尔兹曼机(
r
e
s
t
r
i
c
t
e
d
restricted
restricted
b
o
l
t
z
m
a
n
n
boltzmann
boltzmann
m
a
c
h
i
n
e
s
machines
machines,
R
B
M
RBM
RBM)
基于能量模型,由可见层和隐藏层组成,通过最大化训练样本的似然函数来学习模型参数,通过学习权重参数来拟合数据分布;用于无监督学习和特征学习
RBM本身是无监督学习算法,但在特定应用中可以与监督学习结合使用。
- 深度生成模型(
d
e
e
p
deep
deep
g
e
n
e
r
a
t
i
v
e
generative
generative
m
o
d
e
l
s
models
models)
基于神经网络,如变分自编码器( v a r i a t i o n a l variational variational a u t o auto auto e n c o d e r encoder encoder, V A E VAE VAE)和生成对抗网络( g e n e r a t i v e generative generative a d v e r s a r i a l adversarial adversarial n e t w o r k network network, G A N GAN GAN),模型通过学习编码和解码器或博弈过程来生成新的样本。
(9)集成学习( e n s e m b l e ensemble ensemble l e a r n i n g learning learning)
通过组合多个基本学习器的预测结果,来产生更准确、鲁棒性更强的整体预测,提高模型性能
组合方式:投票法、平均法、堆叠法等
虽然集成学习主要用于监督学习,但也可以与无监督学习相结合,例如使用无监督学习算法对数据进行聚类或降维,然后在集成学习中使用这些无监督学习的结果进行训练和预测。这种结合可以在半监督学习或弱监督学习等任务中发挥作用。
- 随机森林(
r
a
n
d
o
m
random
random
f
o
r
e
s
t
forest
forest)
基于决策树,构建多个决策树,并通过投票或平均的方式进行集成;用于分类和回归预测。 - 提升(
b
o
o
s
t
i
n
g
boosting
boosting)算法
通过组合多个弱学习器来构建一个强学习器,这些弱学习器一般是准确率略高于随机猜测的学习器。通过迭代训练一系列弱学习器,每个学习器都尝试修正前一轮学习器的错误,最终将这些弱学习器的预测结果进行加权组合,形成一个强学习器 - 自适应提升(
A
d
a
p
t
i
v
e
Adaptive
Adaptive
B
o
o
s
t
i
n
g
Boosting
Boosting,
A
d
a
B
o
o
s
t
AdaBoost
AdaBoost)算法
通过迭代训练一系列弱学习器,每个学习器都根据前一轮学习器的错误情况自适应地调整训练样本的权重,从而更加关注错误分类的样本,以提高整体模型的准确性。在每一轮迭代中,根据弱学习器的准确性为其分配一个权重,然后将所有弱学习器的预测结果进行加权投票,得到最终的预测结果
在处理二分类问题时表现出色,但对噪声和异常值比较敏感 - 梯度提升(
g
r
a
d
i
e
n
t
gradient
gradient
b
o
o
s
t
i
n
g
boosting
boosting)算法
基于梯度优化,通过迭代训练一系列弱学习器来构建一个强学习器,使用了梯度下降优化算法来最小化损失函数。在每一轮迭代中,通过计算损失函数的负梯度来确定下一轮弱学习器的目标,每个弱学习器都试图拟合上一轮学习器的残差,以逐步减少整体模型的误差,以提升整体模型的性能。最终将所有弱学习器的预测结果进行加权组合,得到最终的预测结果。
更加灵活且能够处理更复杂的问题。
变种: g r a d i e n t gradient gradient b o o s t i n g boosting boosting m a c h i n e machine machine( G B M GBM GBM), e x t r e m e extreme extreme g r a d i e n t gradient gradient b o o s t i n g boosting boosting( X G B o o s t XGBoost XGBoost)和 L i g h t G B M LightGBM LightGBM等。 - 自助聚合(
b
o
o
t
s
t
r
a
p
bootstrap
bootstrap
a
g
g
r
e
g
a
t
i
n
g
aggregating
aggregating,
B
a
g
g
i
n
g
Bagging
Bagging)算法
基于自助采样( b o o t s t r a p bootstrap bootstrap),通过从原始训练数据集中多次有放回地进行采样,生成多个不同的训练集。然后每个训练集都用于训练一个基本学习器,最后通过投票或取平均值的方式来集成这些基本学习器的预测结果
可以降低模型的方差,提高模型的鲁棒性和泛化能力。 - 随机森林(
r
a
n
d
o
m
random
random
f
o
r
e
s
t
forest
forest)算法
基于决策树,构建多个决策树,并通过投票或平均的方式进行集成,是 B a g g i n g Bagging Bagging的拓展;用于分类和回归预测。 - 堆叠泛化(
s
t
a
c
k
e
d
stacked
stacked
g
e
n
e
r
a
l
i
z
a
t
i
o
n
generalization
generalization,
S
t
a
c
k
i
n
g
Stacking
Stacking)算法
基于模型堆叠( s t a c k e d stacked stacked),通过将多个基本学习器的预测结果作为输入,再训练一个元学习器来对最终的目标进行预测。首先将原始训练数据集划分为两个或多个不相交的子集,分别用于训练基本学习器和构建元学习器的训练集。基本学习器生成的预测结果被用作元学习器的输入特征,从而产生最终的预测结果。
可以使模型更加灵活和强大,因为元学习器可以学习到基本学习器之间的关系和权重。
2.无监督学习( u n s u p e r v i s e d unsupervised unsupervised l e a r n i n g learning learning)
用于处理无标签数据的学习方法,目标是发现数据中的隐藏结构和模式。
(1)聚类( c l u s t e r i n g clustering clustering)
将相似的数据样本分组为不同的类别,每个类别内的数据具有较高的相似性,而不同类别之间的数据具有较大的差异。
- K均值聚类(
k
−
m
e
a
n
s
k-means
k−means
c
l
u
s
t
e
r
i
n
g
clustering
clustering)
将数据样本分为 k k k个簇,使得簇内的样本之间的距离最小化 - 层次聚类(
h
i
e
r
a
r
c
h
i
c
a
l
hierarchical
hierarchical
c
l
u
s
t
e
r
i
n
g
clustering
clustering)
通过自下而上或自上而下的聚合方式,将数据样本组织成层次结构 - 基于密度的空间聚类与噪声应用(
D
e
n
s
i
t
y
−
B
a
s
e
d
Density-Based
Density−Based
S
p
a
t
i
a
l
Spatial
Spatial
C
l
u
s
t
e
r
i
n
g
Clustering
Clustering
o
f
of
of
A
p
p
l
i
c
a
t
i
o
n
s
Applications
Applications
w
i
t
h
with
with
N
o
i
s
e
Noise
Noise,
D
B
S
C
A
N
DBSCAN
DBSCAN)
基于样本的密度来将数据点分为核心点、边界点和噪声点。
(2)关联规则挖掘( a s o c i a t i o n asociation asociation r u l e rule rule m i n i n g mining mining)
用于发现数据项之间关联关系的学习方法,通过分析数据集中的频繁项集和关联规则,揭示数据中的相关模式;购物篮分析是关联规则挖掘的一个具体应用领域
-
A
p
r
i
o
r
i
Apriori
Apriori算法:
通过逐层搜索频繁项集,找出具有最小支持度的频繁项集和关联规则。 -
F
P
−
G
r
o
w
t
h
FP-Growth
FP−Growth算法
通过构建频繁项集的紧凑数据结构( F P FP FP树, f r e q u e n t frequent frequent p a t t e r n pattern pattern t r e e tree tree),从而高效地挖掘频繁项集和关联规则。 -
E
c
l
a
t
Eclat
Eclat算法(
e
q
u
i
v
a
l
e
n
c
e
equivalence
equivalence
c
l
a
s
s
class
class
t
r
a
n
s
f
o
r
m
a
t
i
o
n
transformation
transformation)
利用等价类的概念来处理频繁项集和关联规则的挖掘,通过压缩事务数据库来形成垂直数据格式,然后使用递归方式搜索。
(3)降维——主成分分析( p r i n c i p a l principal principal c o m p o n e n t component component a n a l y s i s analysis analysis, P C A PCA PCA)
通过降维将高维数据映射到低维空间,以保留最重要的特征。
3. 半监督学习( s e m i − s u p e r v i s e d semi-supervised semi−supervised l e a r n i n g learning learning)
利用有标签和无标签的数据来进行训练和预测的学习方法,通常情况下有大量无标签数据和少量有标签数据,可以利用未标记数据的信息来提高模型性能;常用于数据标注困难或昂贵的情况下。
(1)自训练( s e l f − t r a i n i n g self-training self−training)
通过使用有标签数据训练初始模型,然后将该模型应用于未标签数据,并将模型预测的结果作为伪标签来扩充训练集进行迭代训练。
(2)协同训练( c o − t r a i n i n g co-training co−training)
通过将特征空间划分为多个视角,使用有标签数据训练多个独立的分类器,在每个视角上使用未标签数据进行互相增强和更新;适用于特征空间有多个视角的问题
(3)标签传播( l a b e l label label p r o p a g a t i o n propagation propagation)
假设相似的样本在标签上也是相似的,基于图模型,通过构建样本之间的相似度图,并将有标签数据的标签传播到无标签数据上,从而进行预测。
(4)分布式共享表示( d i s t r i b u t e d distributed distributed s h a r e d shared shared r e p r e s e n t a t i o n s representations representations)
通过在有标签和无标签数据上共享特征表示来进行训练。它通过使用无监督学习方法来学习共享特征表示,并在有标签数据上进行监督学习来提高性能。
4.强化学习( r e i n f o r c e m e n t reinforcement reinforcement l e a r n i n g learning learning)
通过与环境的交互学习,通过试错来最大化累积奖励。强化学习适用于需要决策和行动的问题,如游戏、自动驾驶等。
5.迁移学习( t r a n s f e r transfer transfer l e a r n i n g learning learning)
将在一个任务上学习到的知识和经验应用于另一个相关任务上,以加速学习过程和提高性能。
(二)深度学习
深度学习是一种特定的机器学习方法,,通过构建和训练多层神经网络来模拟人脑的神经结构,实现对复杂数据的高级特征提取和预测
五,其他概念
1.误分类代价,测试代价,标记代价,属性代价,代价敏感学习
2.要素化表示法,分析学习(演绎学习)
3.假说,分类,假说空间,一致假说,奥坎姆剃刀
4.学习曲线,快乐图,熵,信息收益,决策树剪枝,重要性测试,
χ
2
\chi^2
χ2剪枝,早期终止,收益比率,分裂点,回归树
χ 2 \chi^2 χ2剪枝是一种特征选择
5.稳定性假设,误差率,偷窥,最优化,封套(
w
r
a
p
p
e
r
wrapper
wrapper),损耗函数,泛化损耗,经验损耗,小规模学习,大规模学习,正则化,特征选择,极小描述长度(
m
i
n
i
m
u
m
minimum
minimum
d
e
s
c
r
i
p
t
i
o
n
description
description
l
e
n
g
t
h
length
length,
M
D
L
MDL
MDL)假说
6.概率近似正确(
p
r
o
b
a
b
l
y
probably
probably
a
p
p
r
o
x
i
m
a
t
e
l
y
approximately
approximately
c
o
r
r
e
c
t
correct
correct,
P
A
C
PAC
PAC)学习算法,计算学习理论,样本复杂度,决策表
7.类比学习,概念学习,度量学习,稀疏学习
以上未完待更新,仅供个人学习,侵权联系删除,如有错误或不足之处可指出,以便改进。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











