






一:回归总论
1,什么是回归算法
回归分析是一种研究自变量与因变量之间相互关系的一种建模技术,主要用来预测时间序列,找到变量之间的关系。
2,回归的种类
按照自变量和因变量之间的关系类型,可分类线性回归和非线性回归,按照自变量的多少可分为一元回归和多元回归
二:线性回归
1,概念
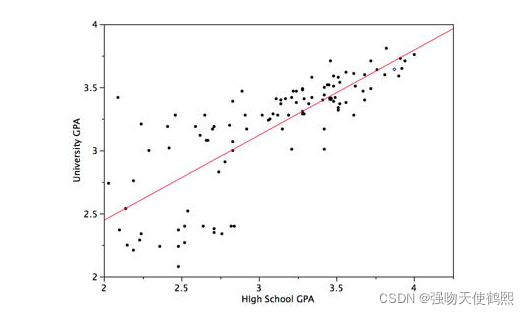
线性回归一般用来做连续值的预测,自变量可以是连续的,也可以是离散的,但预测结果是连续的,回归的性质是线性的,他使用最佳拟合直线在自变量和因变量之间建立一种线性关系
2,线性回归的数学假设
(1):假设输入x和输出y是线性关系,预测的输出需要通过输入来建立线性模型
(2):输入和输出满足y = wx+b,其中y是输出,x是输入,w为权重,也就是线性回归模型需要学习的参数,b是偏置项
3,回归模型损失函数
在线性回归中,通常用预测值和真实值之间的平方损失来作为模型的损失函数,即最小二乘法作为损失函数。原因如下
【1】对于观测的数据,他通过最小化数据点到线的垂直距离偏差的平方和来计算最佳拟合分界线。因为在点到分界线的垂直距离相加时候先进行了平方,所以正负值并没有影响,能够准确统计点到线的真实距离,也就是整体的损失。
【2】线性模型希望的是预测值和真实值在训练集上尽可能接近,用平方损失来定义数据样本上的损失,当该损失越小,说明模型在样本上的估计值和真实值偏差越小
【3】线性回归的损失函数-点模型和矩阵模型(笔者手写)

4,线性回归的优化算法–小批量随机梯度下降
具体的论述细节,读者可参考笔者的该文章
三:逻辑回归
四:多项式回归
如果一个回归,它的自变量指数超过1,则称为多项式回归。可以用公式表示:
y = a + b * x^2
在这个回归技术中,最适的线不是一条直线,而是一条曲线。

重点:
1.很多情况下,我们为了降低误差,经常会抵制不了使用多项式回归的诱惑,但事实是,我们经常会造成过拟合。所以要经常的把数据可视化,观察数据与模型的拟合程度。
2.特别是要看曲线的结尾部分,看它的形状和趋势是否有意义。高的多项式往往会产生特别古怪的预测值。
五:逐步回归
适用范围:多个自变量需要处理,且自变量的选择都是程序自动进行的,无需人工干预,这也是逐步回归最大的优点
工作原理:逐步回归每执行一次迭代,都会增加或者减少一个变量特征
优点:用最少的变量去最大化模型的泛化能力,这是一种典型的处理高维数据的方法,即降维
变量选择的标准:通过观测值来确定,例如最小信息熵
常见的逐步回归方法:
1,前向选择法:从模型中显著性最强的变量开始,每次迭代增加一个变量
2,后向剔出法:从模型中显著性(最小信息熵)最小的变量开始,每一步不消除一个变量
六:岭回归
1, 什么是岭回归:
岭回归的目标函数在一般的线性回归的基础上加入了正则项,在保证最佳拟合误差的同时,使得参数尽可能的“简单”,使得模型的泛化能力强(即不过分相信从训练数据中学到的知识)。正则项一般采用一,二范数,使得模型更具有泛化性,同时可以解决线性回归中不可逆情况。
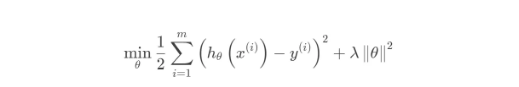
其迭代优化函数如下:
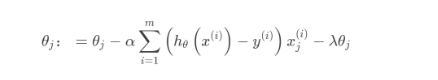
另外从最小二乘的角度来看,通过引入二范正则项,使其主对角线元素来强制矩阵可逆。
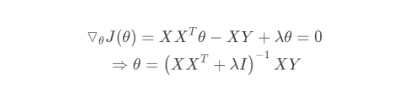
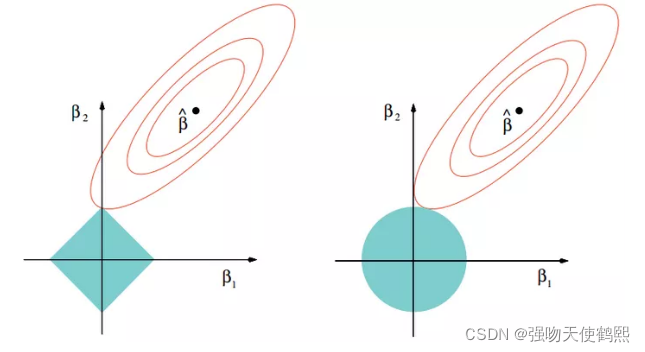
Lasso回归采用一范数来约束,使参数非零个数最少。而Lasso和岭回归的区别很好理解,在优化过程中,最优解为函数等值线与约束空间的交集,正则项可以看作是约束空间。可以看出二范的约束空间是一个球形,而一范的约束空间是一个方形,这也就是二范会得到很多参数接近0的值,而一范则尽可能非零参数最少。重点:这里需要注意的是,我们求解加入正则化项的算是函数最小,就是求红券商某一点和蓝圈上某一点之和的最小值,这个值通常就是两个图像的相切点(如果不在相切出,那么至少有两个点的值相同,这与极值的定义矛盾),而L1范数曲线更容易与蓝色曲线在顶点出相交,这就导致了除相切出的维度不为零,其他维度的权重均为0,从而更容易产生模型的稀疏解。
七:Elasticnet回归–弹性网络回归
概念:一种介于罗素回归和岭回归之间的方法,他使用L1训练,L2做作为正则化矩阵,当有多个相关的特征时,该方法会选择两个正则化。这样做的好处是允许继承循环状态下ridge的稳定性
注意:在变量高度相关的情况下鼓励群体效应,而不是像lossu一样将变量归一化,其次,变量的选择没有数目的限制,亦可以承受双重搜索。
八:如何去选择回归模型
面对如此多的回归模型,最重要的是根据自变量因变量的类型、数据的维数和其他数据的重要特征去选择最合适的方法。以下是我们选择正确回归模型时要主要考虑的因素:
1.数据探索是建立预测模型不可或缺的部分。它应该是在选择正确模型之前要做的。
2.为了比较不同模型的拟合程度,我们可以分析不同的度量,比如统计显著性参数、R方、调整R方、最小信息标准、BIC和误差准则。另一个是Mallow‘s Cp准则。
3.交叉验证是验证预测模型最好的方法。你把你的数据集分成两组:一组用于训练,一组用于验证。
4.如果你的数据集有许多让你困惑的变量,你就不应该用自动模型选择方法,因为你不想把这些变量放在模型当中。
5.不强大的模型往往容易建立,而强大的模型很难建立。
6.回归正则方法在高维度和多重共线性的情况下表现的很好。














 3779
3779











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









