






前言

这是一篇用python爬取微博签到数据的爬虫教程,不建议没有爬虫基础的小伙伴食用惹,因为代码我用Ai润色过,所以看起来会比较复杂繁琐!教程并没有怎么参考现有的文章,所以很多东西都是自己瞎诌嘿嘿
网页解析
这里用的是微博的移动端界面进行爬取,因为它不用登陆账号就可以进行爬取。打开微博手机版网页,在搜索框搜索想爬取的地方,我这里搜广州市来实操一下。
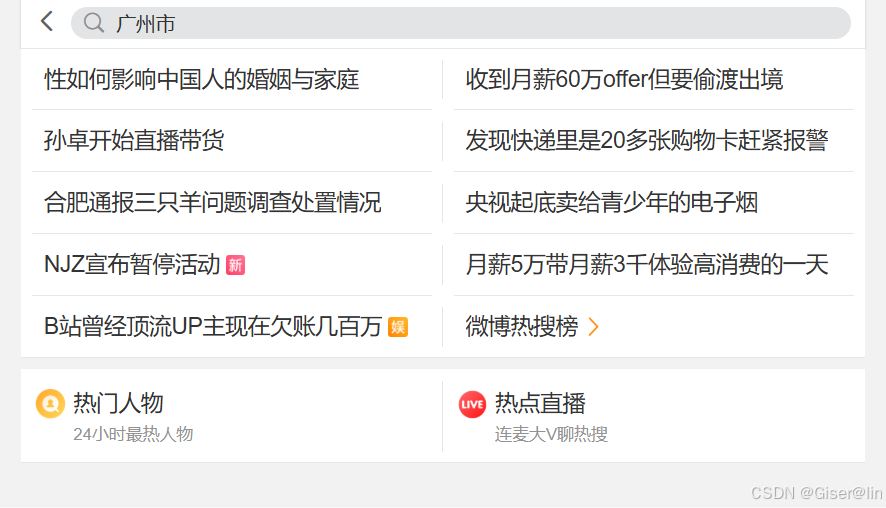
搜完之后点击地点,至于为什么惹,因为这里面的微博基本都会打卡一个地点,不然怎么爬签到的地点数据咧~
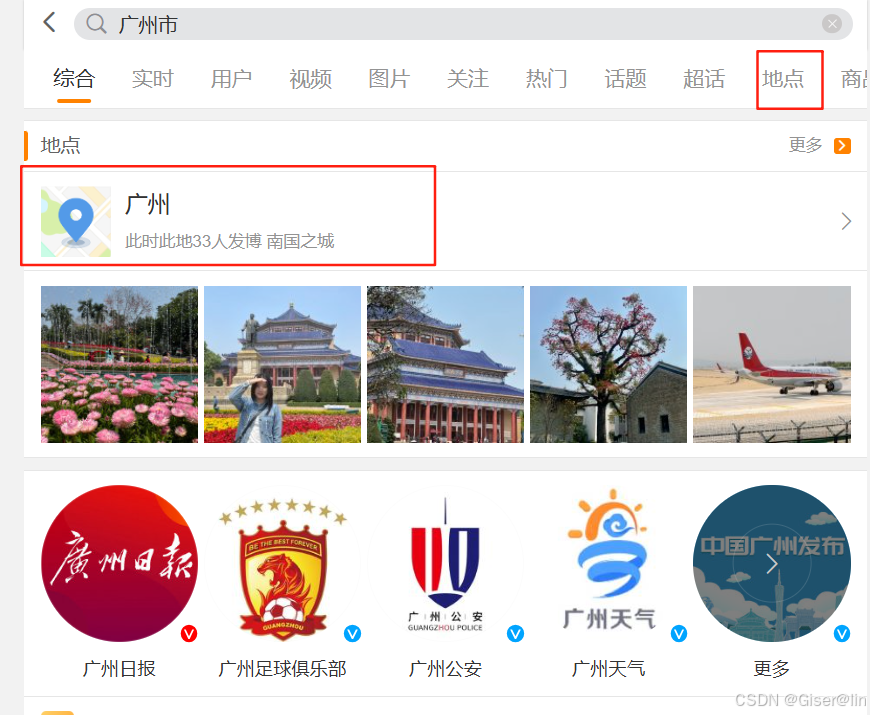
我们把下面每一条微博的用户、微博内容、发布时间、打卡地点都爬取下来。
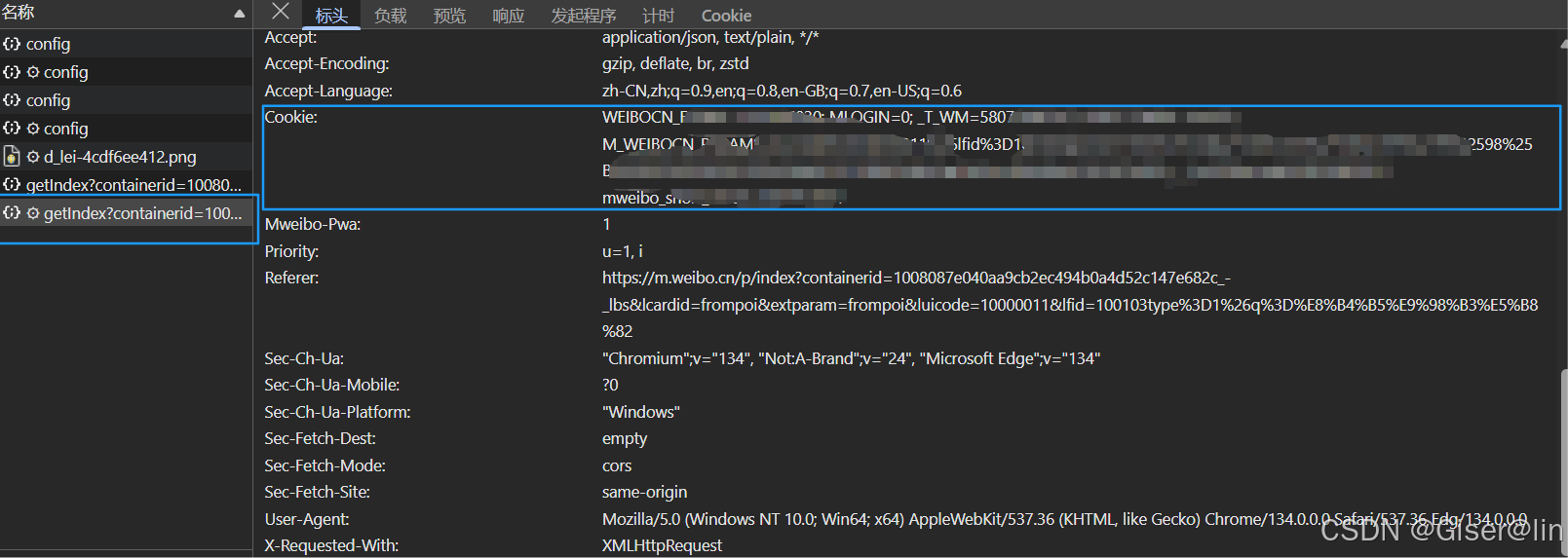
事不宜迟,F12找到网络选项卡,我们找到有一个getindex?containerid=1008087e040aa9cb2ec494b0a4d5.2=100103tpe%3D1%26g%3D%E8%B4%B5%E9%98%B3%E5%B8%82的东西,在预览里不断翻找,终于还是找到了数据的藏身之处
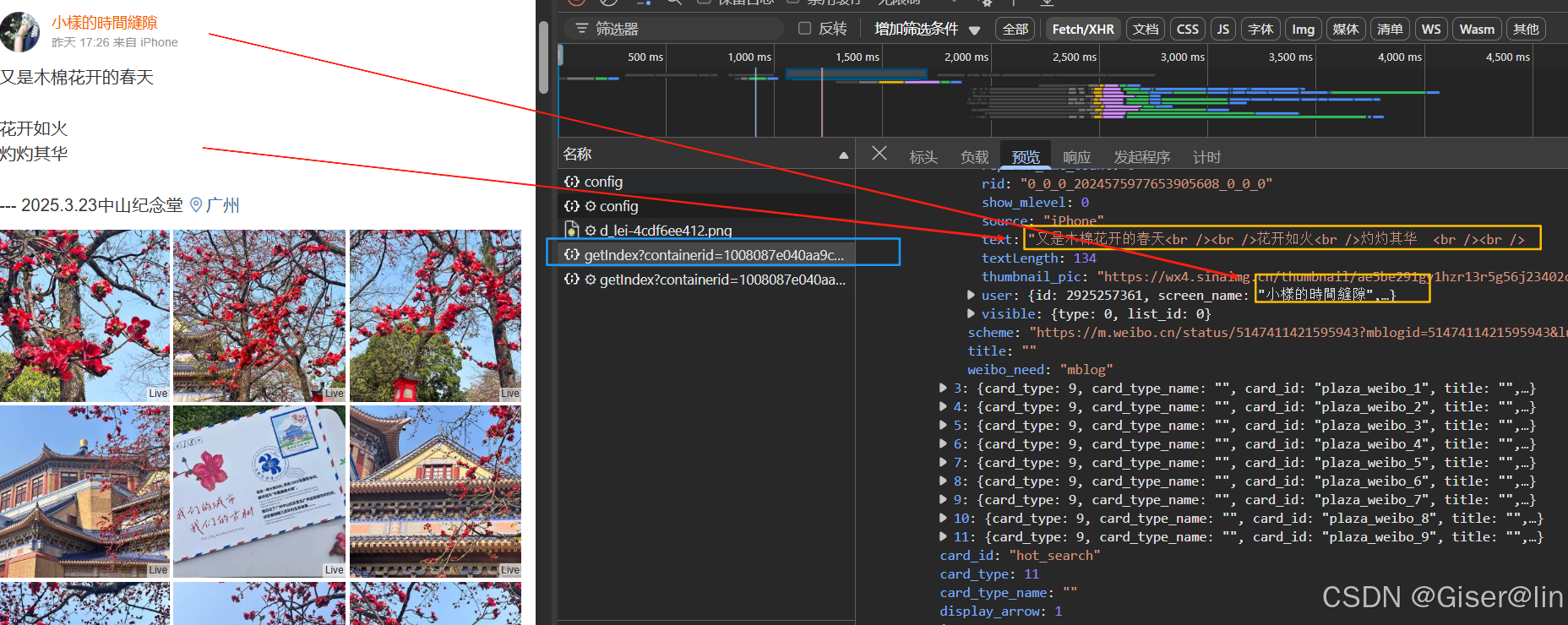
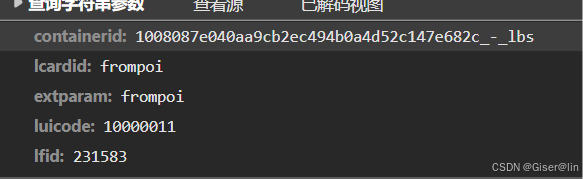
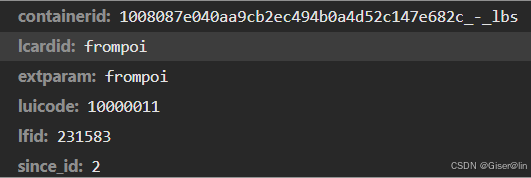
切换到标头,找到对应的URL和cookie(可以切到另一个文件去查看),同时我们在负载找到请求url所必须的参数,这些参数会随着搜索城市的不同而异,大致如下:
containerid: 1008087e040aa9cb2ec494b0a4d52c147e682c_-_lbs
lcardid: frompoi
extparam: frompoi
luicode: 10000011
lfid: 231583

找到了对应的数据以及相应的参数之后,我们就可以来分析一下这个文件的结构,但是这里需要注意一下:首页的结构跟后续第二第三页的结构是不一样的!这就意味着我们需要给首页跟后续页分别构建不同的数据提取方法。
先来看看首页结构:
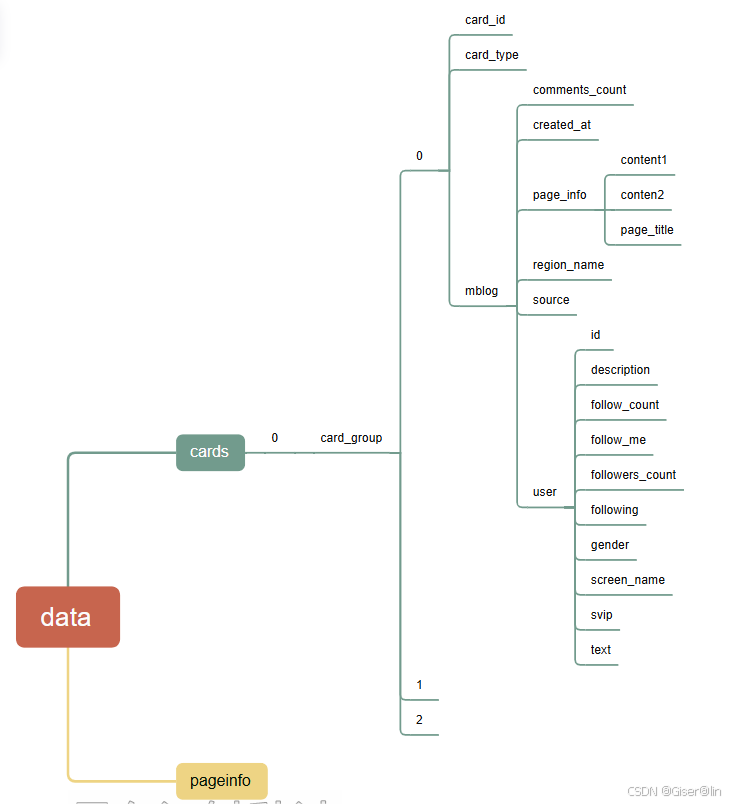
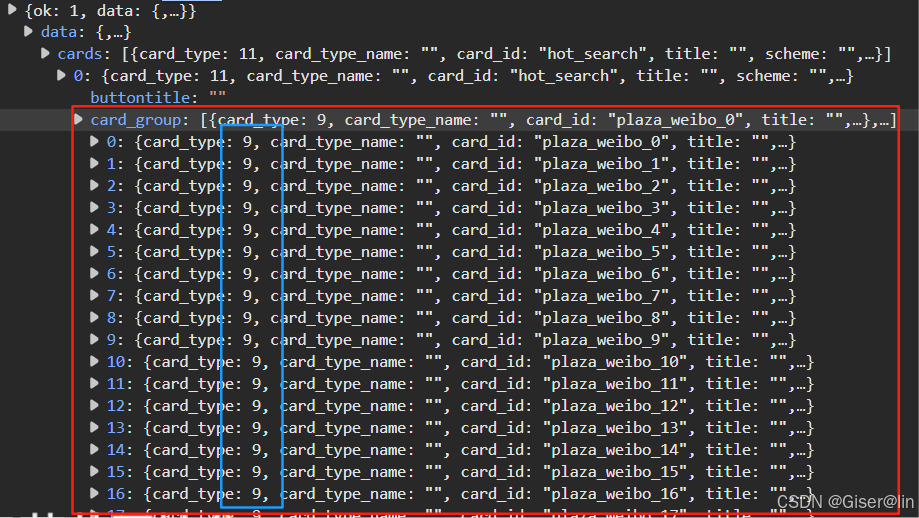
看不懂?没关系~也就是如果我们发送一只爬虫出去,小虫子带回来的是一份层层包裹的数据(命名为res),然后我们通过res.json()方法把数据转成了能看懂的样子(命名为data),通过data[‘data’]我们打开了第一层,发现里面有cards和pageinfo两个小包裹,我们使用data[‘data’][‘cards’]果断选择打开cards那个(命名为cards),发现里面有还有一个层层包裹的数据,所以我们继续打开,通过data[‘data’][‘cards’][0]打开后我们发现了一个叫card_group的数据(card_group),card_group里有很多个card,其中每个card就包含了一条微博。
经过层层地挖掘,我们在首页的card_group里找到了12条card,但只有card_type为9的card才是用户发布的微博!!! 所以这个card_type可以用来提取对应的微博。
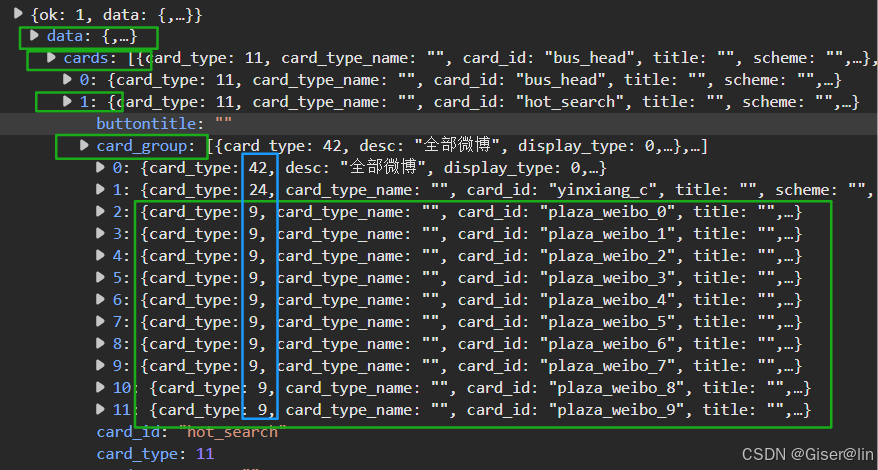
我们再来看看第二页的结构(第二页可以通过滚动下拉条找到!),大同小异,这里第二页的card_group里面就全是用户发布的贴子了,同时需要注意的是,第二页开始url需要加上since_id的页码了,因此需要构造两种url,首页是不带页码的,后续是需要页码的。至于为什么不能设置sice_id=1,因为实践下来发现是没有数据的…

所以了解了大致的结构之后我们就可以来敲代码了!!!
爬取框架
先来说一下思路,整个流程需要构建4个核心函数:
- 快递员函数(数据获取)
- 叫fetch_page函数(类似快递小哥取包裹)
- 功能:带着微博会员卡(Cookie)去微博仓库(API)取快递包裹(JSON数据)
- 特殊技能:会假装不同手机下单(随机User-Agent),隔5秒取一次件(防封禁)
- 拆包裹函数(数据处理)
- 叫clean_text函数(像拆快递的小刀)
- 四步拆包法:
① 解开加密胶带(HTML解码)
② 找到地址标签(用正则表达式匹配"广州·天河区")
③ 撕掉泡沫纸(去除广告链接)
④ 整理成标准快递单(合并空白字符)
- 地图导航函数(地理编码)
- 叫get_geocode函数(像导航软件)
- 功能:把"天河体育中心"翻译成经纬度(113.323,23.114)
- 特殊限制:每分钟最多查2次(QPS控制),查过的地址会记在小本本上(缓存)
- 仓库管理员函数(数据存储)
- 叫parse_raw_data函数(像快递分拣员)
- 工作流程:
① 把快递按楼层分类(分页解析cards数据)
② 挑出有效快递(过滤广告卡片)
③ 登记发件人信息(提取用户ID、昵称)
④ 记录签收时间(转换时间格式)
⑤ 最后打包发往Excel仓库(to_excel)
代码实战
- 参数配置
首先来创建一个参数配置的类,方便我们后续直接调用这个类里面的各种属性,包括高德API的密钥、并发量、需要爬取的城市、cookies等等,这里是需要根据需要修改的~
# ------------------------- 配置类 -------------------------
class WeiboConfig:
"""微博爬虫配置中心"""
# 高德地图API配置
AMAP_MAX_RETRY = 3 # 地理编码最大重试次数
AMAP_QPS = 2 # 每秒查询率限制
AMAP_RETRY_DELAY = 5 # 重试等待时间(秒)
AMAP_API_KEY = "自行填写" # 高德API密钥
AMAP_GEOCODE_URL = "https://restapi.amap.com/v3/geocode/geo" # 地理编码端点
# 爬虫核心参数
CITY_NAME = "目标城市" # 目标城市名称
CONTAINER_ID = "查看负载里填写" # 微博容器ID
LFID = f"查看负载里填写" # 微博页面ID
# 请求头配置
REQUEST_HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)...", # 模拟浏览器
"X-Requested-With": "XMLHttpRequest", # 标识AJAX请求
}
# Cookie配置(需定期更新)
COOKIES = {
"_T_WM": "自行填写",
"WEIBOCN_FROM": "自行填写",
"MLOGIN": "0",
"M_WEIBOCN_PARAMS": "自行填写",
"XSRF-TOKEN": "自行填写",
}
# 运行参数
MAX_PAGES = 1 # 最大爬取页数
REQUEST_INTERVAL = 5 # 请求间隔(秒)
RETRY_TIMES = 1 # 网络请求重试次数
TIMEOUT = 15 # 请求超时时间(秒)
@classmethod
def reload_config(cls):
"""支持从外部文件动态加载配置"""
# 示例实现可读取config.json更新类属性
pass
- 数据模型的构建
这里创建一个类用来存储用户信息,比如用户的id、昵称、性别等等,同时使用__slots__优化了内存(相比普通类减少约40%内存占用);同时创建一个类来存储微博内容、发布时间、发布地点等等,分为两大类方便后期维护~
@dataclass
class WeiboUser:
"""微博用户核心数据模型(不可变数据类型)
字段说明:
- id: 用户唯一数字标识(微博UID,可用于去重和关联)
- screen_name: 显示名称(可能含emoji/特殊符号,最大长度20字符)
- gender: 性别编码(微博API原始值:m=男,f=女,空值=未知)
- verified: 认证状态(True表示蓝V认证/黄V认证等任一类型)
- followers_count: 粉丝数量(动态指标,数据时效性取决于采集时间)
"""
__slots__ = ['id', 'screen_name', 'gender', 'verified', 'followers_count']
id: int # type: int 用户唯一标识(示例:123456789)
screen_name: str # type: str 显示名称(示例:"广州美食探店")
gender: str # type: str 性别编码转换结果("男"/"女"/"未知")
verified: bool # type: bool 是否通过微博认证(企业/个人/机构等)
followers_count: int # type: int 粉丝数指标(可能被微博模糊处理)
@dataclass
class WeiboPost:
"""微博帖子核心数据模型(支持地理信息分析)
字段说明:
- user: 关联用户对象(WeiboUser实例)
- created_at: 发帖时间(已转换为UTC+8时区)
- content: 清洗后的纯文本内容(最大长度2000字符)
- location: 原始定位文本(示例:"广州·天河体育中心")
"""
user: WeiboUser # type: WeiboUser 发布者信息(嵌套数据模型)
created_at: datetime # type: datetime 发帖时间(带时区信息)
content: str # type: str 清洗后文本(示例:"打卡天河体育中心篮球场!")
location: Optional[str] # type: Optional[str] 原始地址文本(可能为None)
coordinates: Optional[Tuple[float, float]] # type: Optional[Tuple] 经纬度元组(示例:(113.323,23.114))
-
地理编码类构建
这个专门负责把像"天河体育中心"这种文字地址变成地图上的经纬度坐标(比如113.32,23.15)class GeoCoder: """高德地图地理编码服务封装(带QPS限流和缓存机制) 核心功能: - 地址转坐标(经纬度) - 严格遵守高德API的QPS限制 - 缓存机制减少重复请求 - 自动重试提升可靠性 """ def __init__(self): # 最后请求时间戳(用于QPS计算) self._last_req_time = 0 # QPS间隔计算(1.2倍缓冲确保不超限) self._qps_interval = 1.2 / WeiboConfig.AMAP_QPS # 创建持久化会话(TCP连接复用) self.session = requests.Session() # 设置请求头(模拟浏览器) self.session.headers.update({'User-Agent': WeiboConfig.REQUEST_HEADERS["User-Agent"]}) @lru_cache(maxsize=2000) # 最近最少使用缓存(2000条目防内存溢出) def get_geocode(self, address: str) -> Optional[Tuple[float, float]]: """ 地理编码核心方法 Args: address: 待解析地址(需包含城市特征,如"天河体育中心") Returns: (经度, 纬度)元组 或 None(解析失败时) 处理流程: 地址清洗 → QPS控制 → API请求 → 响应解析 → 失败重试 """ # === 地址预处理 === address = re.sub(r'\s+', '', address).strip() # 去除所有空白字符 if not address or address == "地址不详": logging.debug("跳过无效地址") return None # === 重试机制(AMAP_MAX_RETRY控制容错)=== for retry in range(WeiboConfig.AMAP_MAX_RETRY): try: # === QPS精确控制 === elapsed = time.time() - self._last_req_time if elapsed < self._qps_interval: # 计算需要等待的时间(增加随机扰动防止规律请求) sleep_time = (self._qps_interval - elapsed) + random.uniform(0.1, 0.3) time.sleep(max(sleep_time, 0)) # 确保不小于0 # === 构造API请求参数 === params = { "key": WeiboConfig.AMAP_API_KEY, # 高德开发者密钥 "address": f"{WeiboConfig.CITY_NAME}{address}", # 地址拼接(确保城市级搜索) "city": WeiboConfig.CITY_NAME.rstrip('市') # 城市参数需去除"市"后缀 } # === 发送API请求 === response = self.session.get( WeiboConfig.AMAP_GEOCODE_URL, params=params, timeout=WeiboConfig.TIMEOUT # 超时设置(秒) ) data = response.json() # 获取JSON响应 self._last_req_time = time.time() # 更新请求时间戳 # === 响应解析 === if data.get('status') == '1': # 高德成功状态码 if geocodes := data.get('geocodes'): first_geocode = geocodes[0] # 取置信度最高的结果 if loc_str := first_geocode.get('location'): # 坐标格式校验(经度,纬度 字符串) if ',' in loc_str: # 转换为浮点数元组(如(113.32, 23.15)) return tuple(map(float, loc_str.split(','))) # 响应状态码非1时触发重试 logging.warning(f"高德API返回异常: {data.get('info')}") except Exception as e: # 异常分类处理(网络问题/解析错误等) logging.error(f"地理编码请求异常: {str(e)}") if retry == WeiboConfig.AMAP_MAX_RETRY - 1: return None # 指数退避重试(2秒、4秒...) time.sleep((retry + 1) * 2) return None # 所有重试失败- 初始化
准备好问问题的节奏,装成普通用户用浏览器查地图
def __init__(self): self._last_req_time = 0 # 记着上次问高德的时间(像排队买包子要看前面人什么时候买完) self._qps_interval = 1.2 / 每秒能问几次 # 控制问问题的速度(比如1秒只能问1次,我就等1.2秒再问下一个) self.session = requests.Session() # 跟高德保持通话不挂电话(省得每次重新拨号) self.session.headers = 假装是浏览器 # 让高德觉得是正常人在用浏览器查地图- 带缓存的地理编码(查字典还带小本本)
最近查过的地址直接翻小本本,不用再问高德
@lru_cache(maxsize=2000) # 最近查过的地址记在小本本上(最多记2000个,太旧的自动忘) def get_geocode(self, address: str):- 地址清洗
address = re.sub(r'\s+', '', address) # 去掉地址里的空格/换行(像把烂菜叶择干净) if 地址是空或者"地址不详": 直接放弃- QPS控制(排队买包子策略)
严格按照高德规定的提问速度,还故意随机多等会儿免得被发现是机器人
if 距离上次问问题时间太近: 等个随机时间(比如等1秒+随机多等0.1-0.3秒) # 假装思考人生- 构造请求(填调查问卷)
把地址包装成高德喜欢的格式,像填快递单一样
参数 = { "key": 高德给我的通行证, "address": "广州市"+地址, # 防止全国重名(比如北京也有个体育中心) "city": "广州" # 高德要求不能带"市"字(像填表格要写简称) }- 请求与解析
打电话问高德 → 等回复 → 如果回复说"天河体育中心在113.32,23.15" → 记下坐标 if 回复有问题: 记到小本本说这次有问题- 异常重试
如果高德没接电话/说胡话: 第一次等2秒再问 → 第二次等4秒 → 第三次等6秒(像打电话催快递) - 初始化
4. 文本清洗函数
这个类主要是用来从微博发布内容里提取文本和定位的,因为爬取回来的发布内容不仅带有很多的html标记,还把文本跟定位放在一块,因此需要做清洗跟分离。
class TextProcessor:
"""多阶段文本清洗处理器
核心功能:
- 从微博HTML文本中提取结构化信息
- 地理位置信息智能提取
- 去除广告/链接等干扰内容
"""
# 预编译正则表达式(提升性能,避免重复编译)
ADDRESS_PATTERN = re.compile(
r'(?:广州市)?([\u4e00-\u9fa5]{2,20}区?[\u4e00-\u9fa5]+?(?:路|街|号|广场|大厦|学校|馆))'
# 作用:匹配广州市内具体地址(如"天河区体育西路112号")
# 结构说明:
# (?:广州市)? → 可选城市前缀(非捕获组)
# [\u4e00-\u9fa5]{2,20}区? → 匹配2-20个中文字符的行政区(如"天河区")
# (?:路|街|号...) → 地址特征词(非捕获组)
)
LINK_TAG = re.compile(
r'<a\b[^>]*?>.*?<span\s+class=["\']surl-text["\'].*?</span>.*?</a>',
flags=re.DOTALL # 使.匹配包括换行符的所有字符
# 作用:去除微博中的链接卡片(如"网页链接"占位符)
# 匹配示例:<a href="..."><span class="surl-text">网页链接</span></a>
)
HTML_TAG = re.compile(r'<[^>]+>') # 匹配所有HTML标签
WHITESPACE = re.compile(r'\s+') # 匹配连续空白字符
CITY_PATTERNS = {} # 城市匹配模式缓存(避免重复生成正则)
BRACKET_PATTERN = re.compile(
r'[((](.+?)[))]' # 匹配中文/英文括号内容
# 示例:"广州塔(海心沙)" → 提取"海心沙"
)
@classmethod
def clean_text(cls, text: str) -> Dict[str, Optional[str]]:
"""
四阶段文本清洗流水线
Args:
text: 原始HTML文本(可能包含HTML实体和复杂标签)
Returns:
{
"text": 清洗后的纯文本,
"location": 提取的地理位置(可能为None)
}
处理流程:
解码 → 定位提取 → 标签清除 → 空白规范化
"""
result = {'text': None, 'location': None}
try:
# === 阶段1:HTML实体解码 ===
# 将"等实体转换为实际字符(处理微博的二次编码)
decoded = html.unescape(text) if text else ''
# === 阶段2:地理位置提取 ===
city_name = WeiboConfig.CITY_NAME.rstrip('市') # 处理"广州市"→"广州"
# 动态生成城市匹配正则(缓存提升性能)
if city_name not in cls.CITY_PATTERNS:
cls.CITY_PATTERNS[city_name] = re.compile(
fr'<span\s+class=["\']surl-text["\'][^>]*>{re.escape(city_name)}[·•]([^<]+)</span>'
# 匹配微博定位卡片格式(如<span class="surl-text">广州·广州塔</span>)
)
# 多层级位置提取策略
location_match = (
cls.CITY_PATTERNS[city_name].search(decoded) or # 优先匹配定位卡片
re.search(fr'{city_name}[·•\s]?([\u4e00-\u9fa5A-Za-z0-9]+)', decoded) or # 匹配简写格式
cls.BRACKET_PATTERN.search(decoded) or # 括号内容兜底
cls.ADDRESS_PATTERN.search(decoded) # 正则地址匹配
)
result['location'] = location_match.group(1) if location_match else None
# === 阶段3:HTML标签清除 ===
# 先去除链接卡片(避免残留内容)
clean = cls.LINK_TAG.sub('', decoded)
# 去除所有HTML标签(保留纯文本)
clean = cls.HTML_TAG.sub('', clean)
# === 阶段4:空白规范化 ===
# 合并连续空白为单个空格(包括换行/tab等)
result['text'] = cls.WHITESPACE.sub(' ', clean).strip()
except Exception as e:
logging.error(f"文本处理失败: {str(e)}", exc_info=True)
# 失败时返回已处理内容(尽最大努力输出)
result = {'text': clean, 'location': result['location']}
return result
5. 数据请求函数
这个是专门发送get请求的类,包括发送首页url以及后续页url,只负责把数据请求回来
# ------------------------- 微博客户端 -------------------------
class WeiboClient:
"""微博API客户端(带自动重试和连接池管理)
核心功能:
- 维持长连接提升性能(TCP连接复用)
- 实现智能重试机制(带随机延迟防封禁)
- 处理微博特有参数逻辑(containerid/lfid等)
"""
def __init__(self):
# 创建持久化会话(自动处理cookies和headers)
self.session = requests.Session()
# 配置连接池优化性能(适用于高并发场景)
# pool_connections: 缓存连接池数量(推荐值10-20)
# pool_maxsize: 单个主机最大连接数(根据服务器限制调整)
self.session.mount('https://', requests.adapters.HTTPAdapter(
pool_connections=10, # 同时保持的连接数
pool_maxsize=100 # 最大连接池容量
))
def fetch_page(self, page: int) -> Optional[Dict]:
"""
分页获取微博数据(核心请求方法)
Args:
page: 页码(从1开始,微博的分页逻辑特殊)
- 第1页使用默认请求
- 后续页通过since_id分页
Returns:
成功:解析后的JSON数据(包含data.cards数组)
失败:None(达到重试次数上限)
重试策略:
1. 随机延迟:基础间隔±1秒(防止规律请求)
2. 指数退避:每次失败后增加等待时间
3. 状态码检查:非200响应立即重试
"""
# 构造微博特有请求参数
params = {
"containerid": WeiboConfig.CONTAINER_ID, # 容器ID(定位目标feed流)
"lcardid": "frompoi", # 定位卡片类型参数
"extparam": "frompoi", # 扩展参数(与lbs相关)
"luicode": "10000011", # 固定客户端标识参数
"lfid": WeiboConfig.LFID, # 页面ID(城市关联)
"since_id": str(page) if page > 1 else None # 分页机制:
# - 第1页:不传since_id
# - 后续页:since_id=页码(微博特殊分页逻辑)
}
# 带重试的请求逻辑(RETRY_TIMES控制容错性)
for attempt in range(WeiboConfig.RETRY_TIMES + 1):
try:
# 随机延迟逻辑(避免固定间隔被封禁)
base_delay = WeiboConfig.REQUEST_INTERVAL
delay = base_delay + random.uniform(-1, 1) # 添加±1秒随机扰动
time.sleep(max(delay, 1)) # 保证最小延迟1秒
# 发送GET请求(带超时和重试机制)
response = self.session.get(
"https://m.weibo.cn/api/container/getIndex", # 移动端API地址
params=params,
headers=WeiboConfig.REQUEST_HEADERS, # 携带模拟浏览器头
cookies=WeiboConfig.COOKIES, # 维持登录态
timeout=WeiboConfig.TIMEOUT # 超时设置(避免僵死连接)
)
# 检查HTTP状态码(2xx以外的状态码触发异常)
response.raise_for_status()
# 验证业务状态码(微博成功状态码为ok=1)
if response.json().get('ok') == 1:
return response.json()
# 处理业务逻辑错误(如账号被封禁)
logging.warning(f"第{page}页返回异常状态码: {response.json()}")
except requests.HTTPError as he:
# HTTP状态码异常处理(4xx/5xx)
logging.warning(f"第{page}页HTTP异常[{he.response.status_code}] 尝试次数: {attempt+1}")
except requests.Timeout as te:
# 超时特殊处理(可能是网络波动)
logging.warning(f"第{page}页请求超时 尝试次数: {attempt+1}")
except JSONDecodeError as je:
# 响应非JSON格式(反爬机制触发)
logging.warning(f"第{page}页响应解析失败 尝试次数: {attempt+1}")
except Exception as e:
# 其他未知异常(记录详细信息)
logging.warning(f"第{page}页请求异常: {str(e)} 尝试次数: {attempt+1}", exc_info=True)
# 最终失败处理
if attempt == WeiboConfig.RETRY_TIMES:
logging.error(f"第{page}页请求失败,已达最大重试次数")
return None # 所有尝试失败后返回空
7. 数据处理函数
这个函数主要由解析数据跟生成详情地址两个函数组成。
- 解析数据是用于将请求回来的数据进行处理,这里需要分别处理首页跟非首页两种结构,因此需要根据page判断一下是否首页来执行对应的处理。
- 生成详情地址是为了提高定位的准确性,一般在content1里面会记录打卡详细的地址,比如某某县某某村某某路几号这样,加上前面提取的城市+大体地名(比如广州·广州塔)组成更加完整的地址(比如广州·广州塔某某路)。
# ------------------------- 数据处理流水线 -------------------------
class DataPipeline:
"""微博数据解析流水线(核心数据处理模块)"""
@staticmethod
def parse_raw_data(raw: Dict, page: int) -> List[Dict]:
"""
原始数据解析引擎
- 功能:将微博API返回的复杂JSON结构转换为结构化数据
- 处理流程:卡片筛选 → 用户数据提取 → 文本清洗 → 地址合成 → 数据校验
Args:
raw: 原始API响应数据(包含多层嵌套结构)
page: 当前页码(用于处理首页特殊结构)
Returns:
结构化数据列表(每个元素对应一条有效微博数据)
Raises:
KeyError: API数据结构变更时触发
Exception: 其他未捕获异常
"""
posts = []
try:
# 卡片结构定位逻辑
# 首页(page=1)数据位于cards[1],后续页在cards[0]
card_group = raw['data']['cards'][1 if page < 2 else 0]['card_group']
# 遍历卡片组(每个卡片对应一条微博或广告)
for card in card_group:
# 过滤非微博卡片(card_type=9为普通微博卡片)
if card.get('card_type') != 9:
continue
# 核心数据提取区
mblog = card['mblog'] # 微博主体数据
user_info = mblog['user'] # 用户资料数据
# ----------- 用户信息处理 -----------
# 将嵌套的用户数据转换为扁平化结构
user = WeiboUser(
id=user_info['id'], # 用户唯一标识(数字ID)
screen_name=user_info.get('screen_name', '匿名用户'), # 可能被清空的昵称
gender={'m': '男', 'f': '女'}.get(user_info.get('gender'), '未知'), # 性别编码转换
verified=user_info.get('verified', False), # 蓝V认证状态
followers_count=user_info.get('followers_count', 0) # 粉丝数(默认0防报错)
)
# ----------- 文本处理流水线 -----------
# 清洗原始HTML文本并提取地理位置信息
cleaned = TextProcessor.clean_text(mblog.get('text', ''))
# ----------- 地址合成策略 -----------
# 合并正文地址和附加信息(如定位卡片中的详细地址)
full_address = DataPipeline.generate_address(
main=cleaned['location'], # 正文提取的地址(可能为空)
extra=mblog.get('page_info', {}).get('content1', '') # 定位卡片附加信息
)
# ----------- 结构化数据构建 -----------
# 注意时间处理:将微博时间字符串转换为带时区的datetime对象
# 示例:"Tue Dec 05 19:21:22 +0800 2023" → 标准化时间格式
post_dict = {
# >>> 用户基础信息 <<<
'用户ID': user.id, # 用户唯一标识(用于去重)
'用户昵称': user.screen_name, # 可能包含emoji等特殊字符
'性别': user.gender, # 用于用户画像分析
# >>> 微博内容信息 <<<
'发布时间': parser.parse(mblog['created_at'])
.astimezone(ZoneInfo("Asia/Shanghai"))
.strftime("%Y-%m-%d %H:%M:%S"), # 统一为北京时间
'打卡地点': full_address, # 合并后的规范地址
'经度': None, # 留待地理编码填充
'纬度': None, # 留待地理编码填充
'来源': re.sub(r'<.*?>', '', mblog.get('source', '未知来源')), # 去除来源中的HTML标签
'微博内容': cleaned['text'], # 清洗后的纯文本内容
'附加内容': mblog.get('page_info', {}).get('content1', ''), # 关联的定位卡片信息
'评论数': mblog.get('comments_count', 0), # 互动数据指标
# >>> 用户画像信息 <<<
'个人简介': user_info.get('description', ''), # 可能包含联系方式等敏感信息
'关注数': user_info.get('follow_count', 0), # 用户关注数(非粉丝数)
'关注我': '是' if user_info.get('follow_me', False) else '否', # 与当前账号关系
'粉丝数': user_info.get('followers_count', 0), # 粉丝规模指标
'关注中': '是' if user_info.get('following', False) else '否', # 当前账号是否关注
'超级会员': '是' if user_info.get('svip', False) else '否', # 商业属性标识
'认证状态': '已认证' if user_info.get('verified', False) else '未认证', # 加V状态
'认证信息': user_info.get('verified_reason', '') # 认证原因(如"某公司CEO")
}
# ----------- 数据有效性校验 -----------
# 过滤无效地址数据(地理编码将跳过这些记录)
if not full_address or full_address == "地址不详":
logging.warning(f"丢弃无效地址记录 | 原始地址: {cleaned['location']}")
continue
posts.append(post_dict)
except KeyError as e:
# 捕获API结构变更异常(如字段名修改或路径变化)
logging.error(f"关键字段缺失 | 可能API结构已变更 | 缺失字段: {str(e)}")
except Exception as e:
# 捕获未预料异常(保留堆栈信息便于调试)
logging.error(f"解析过程异常 | 错误信息: {str(e)}", exc_info=True)
return posts
@staticmethod
def generate_address(main: str, extra: str) -> str:
"""
地址规范化引擎
- 功能:合并多个来源的地址信息,生成标准格式
- 处理流程:有效性验证 → 主地址合成 → 附加信息合并 → 格式标准化
Args:
main: 正文提取的主地址(可能包含定位卡片信息)
extra: 附加地址信息(如微博自带的定位卡片内容)
Returns:
规范化的完整地址字符串(无效时返回"地址不详")
示例:
>>> generate_address("天河体育中心", "天河路299号")
"广州市天河体育中心天河路299号"
"""
# 无效内容匹配规则(排除视频链接、编码等非地址内容)
invalid_patterns = [
r'微博视频$', # 以"微博视频"结尾的内容
r'\.mp4$', # 视频文件名
r'http', # 包含URL
r'\.mp4|微博视频', # 视频相关关键词
r'[a-zA-Z]{5,}', # 连续5个以上字母(排除英文内容)
r'^[A-Z0-9]{4,}$' # 纯大写字母/数字组合(如设备编码)
]
# 地址合成策略
address_parts = []
# 主地址处理:添加城市前缀(如"广州塔"→"广州市广州塔")
if main:
# 避免重复添加城市名(如原始地址已包含"广州市")
if not re.search(WeiboConfig.CITY_NAME, main):
address_parts.append(f"{WeiboConfig.CITY_NAME}{main}")
else:
address_parts.append(main)
# 附加信息处理:验证有效性后合并
if extra:
# 检查附加信息是否包含无效内容
is_valid = not any(re.search(p, extra) for p in invalid_patterns)
# 有效地址成分检查(包含路、号等特征词)
if is_valid and re.search(r'\d+号|\d+米|区$|市$|街道?|大道|路', extra):
address_parts.append(extra)
# 格式标准化处理
full_address = "".join(address_parts)
# 去重逻辑:合并重复的城市名称(如"广州市天河区广州市中心"→"广州市天河区中心")
full_address = re.sub(
fr'{WeiboConfig.CITY_NAME}(?:市|区|县)?([区县镇乡]+)',
WeiboConfig.CITY_NAME,
full_address
)
# 最终有效性检查(空值或无效合成结果返回"地址不详")
return full_address if full_address else "地址不详"
8.批量地理编码
class BatchGeocoder:
def __init__(self):
self.geocoder = GeoCoder()
self.address_cache = {}
def batch_process(self, df: pd.DataFrame) -> pd.DataFrame:
"""网页4建议的地址规范化处理"""
# 去重处理
unique_addresses = df['打卡地点'].unique().tolist()
# 批量请求(带QPS控制)
for addr in unique_addresses:
if addr not in self.address_cache:
coord = self.geocoder.get_geocode(addr)
# 确保存入的是元组,即使失败也返回(None, None)
self.address_cache[addr] = coord if coord else (None, None)
# 映射回数据(网页1的数据映射思路)
df['经度'] = df['打卡地点'].apply(lambda x: self.address_cache.get(x, (None, None))[0])
df['纬度'] = df['打卡地点'].apply(lambda x: self.address_cache.get(x, (None, None))[1])
return df
9. 主函数
# ------------------------- 主程序 -------------------------
def main():
"""主执行流程"""
# 初始化组件
WeiboConfig.reload_config() # 加载配置文件(如API密钥、请求头等参数)
client = WeiboClient() # 创建微博API客户端实例(包含连接池和重试机制)
pipeline = DataPipeline() # 初始化数据清洗管道(含HTML解析和地址提取模块)
geocoder = BatchGeocoder() # 创建批量地理编码器(带缓存和QPS限流功能)
# 阶段1:数据采集(分页爬取微博内容)
all_posts = []
# 循环爬取1到配置指定的最大页数(MAX_PAGES控制采集深度)
for page in range(1, WeiboConfig.MAX_PAGES + 1):
# 调用微博客户端获取当前页数据(page参数控制分页)
if raw_data := client.fetch_page(page):
# 解析原始JSON数据(返回结构化数据列表)
# page参数影响首页特殊处理逻辑(第1页卡片结构不同)
posts = pipeline.parse_raw_data(raw_data, page)
# 合并当前页数据到总列表(extend保持列表维度)
all_posts.extend(posts)
# 遵守请求间隔(REQUEST_INTERVAL控制采集频率,单位秒)
time.sleep(WeiboConfig.REQUEST_INTERVAL)
# 阶段2:地理编码(地址转坐标)
# 将字典列表转换为DataFrame(二维表格结构)
df = pd.json_normalize(all_posts)
# 批量地址编码(自动处理QPS限制和缓存复用)
df = geocoder.batch_process(df)
# 阶段3:数据存储(持久化到文件)
# 基于用户ID和发布时间去重(防止重复采集)
df.drop_duplicates(subset=['用户ID', '发布时间'], inplace=True)
# 保存为Excel文件(index=False去除pandas自动索引列)
df.to_excel('weibo_data.xlsx', index=False)
# 记录完成日志(len(df)获取最终数据条目数)
logging.info(f"数据已保存,共{len(df)}条记录")
if __name__ == "__main__":
# 程序入口(直接执行本文件时运行main函数)
# 适用于命令行启动场景:python weibo_crawler.py
main()
爬取结果


踩过的坑
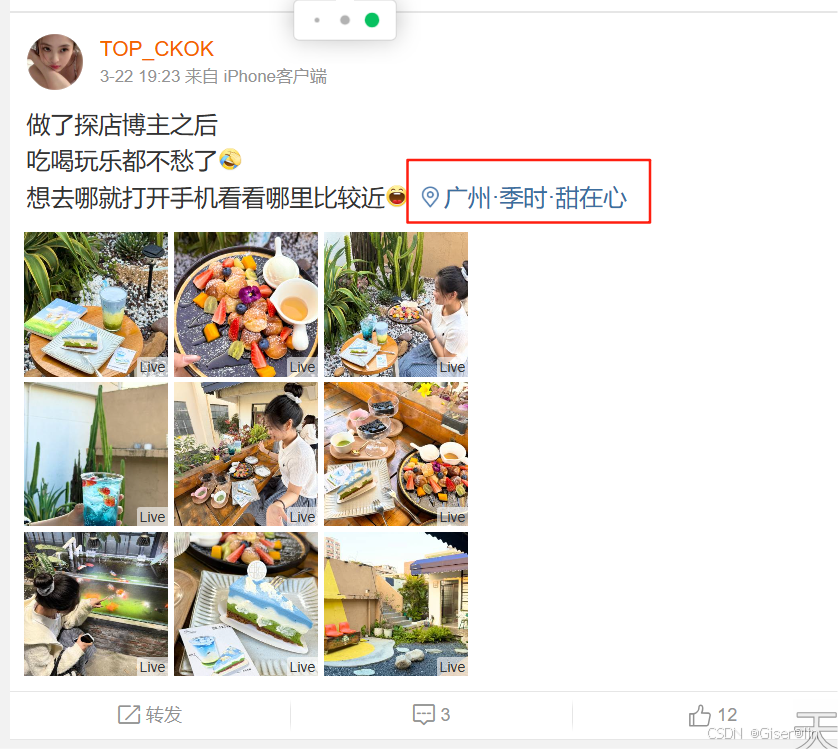
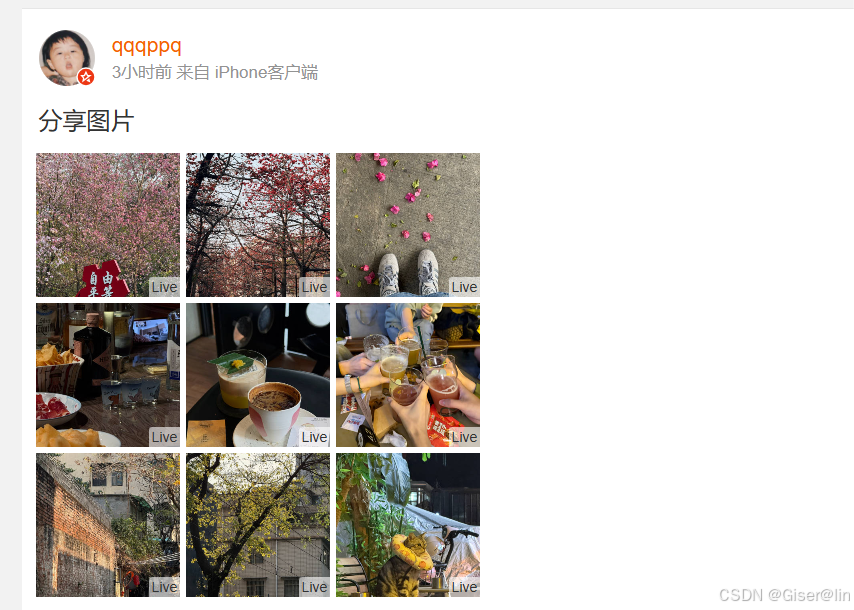
- 并不是所有微博都有定位,比如下图,没有定位的时候就请求不到地址!!!
- 幽灵微博
就是没有user、created_at等信息但爬取回来又实实在在是一条数据的,如果不做异常判断的话就会出问题~ - 数据重复问题
一般每页的数据大概是9条、10条这样,而第二页出现18条左右的数据,前9条一般都是第一页的重复数据,所以在把所有数据采集完毕后根据用户和发布时间做去重~ - 区域爬取不到数据
这是因为有的区域的分页参数是page而不是since_id,因此如果你输入区域爬不到数据的时候,记得F12看看第二页的分页参数,把since_id改成page就可以正常爬取数据了


















 1762
1762

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









