







精品推荐:
《征服数据结构》专栏:50多种数据结构彻底征服
《经典图论算法》专栏:50多种经典图论算法全部掌握
一网友面试的时候,面试官问他为啥从上家公司离职,他说:老板答应的涨薪没兑现,不喜欢画大饼的公司。这不就是大实话吗,我觉得回答的挺好的,也没啥问题,就因为这个原因说人家不合适,面试的估计也是个喜欢画大饼的公司。
其实离职原因无非就那几个:1,钱少了,2,加班太多了,3,太累了干的不爽。但面试的时候又不能说,非说一些高大上的:
1,希望可以迈向一个新的台阶,在这个领域学习更多的新知识,寻求更多的发展。
2,我跟重视平台发展,我认为一个人只有放在合适的平台才能够最大程度的发挥出自己的能力。
3,为了自己的长期职业规划。
4,实在编不下去了。。。
记得当年刚毕业的时候,有次hr和我谈薪,我的回答让hr一愣一愣的,因为所有回答全部出乎她的意料之外。其实这才是最真实的想法,但hr不喜欢听,非要听一些虚的。


--------------下面是今天的算法题--------------
来看下今天的算法题,这题是LeetCode的第542题:01 矩阵。
问题描述
来源:LeetCode第542题
难度:中等
给定一个由 0 和 1 组成的矩阵 mat ,请输出一个大小相同的矩阵,其中每一个格子是 mat 中对应位置元素到最近的 0 的距离。
两个相邻元素间的距离为 1 。
示例1:
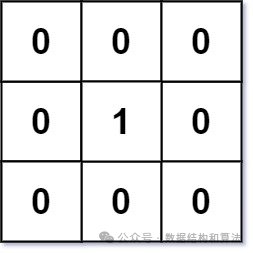
输入:mat = [[0,0,0],[0,1,0],[0,0,0]]
输出:[[0,0,0],[0,1,0],[0,0,0]]
示例2:

输入:mat = [[0,0,0],[0,1,0],[1,1,1]]
输出:[[0,0,0],[0,1,0],[1,2,1]]
m == mat.length
n == mat[i].length
1 <= m, n <= 104
1 <= m * n <= 104
mat[i][j] is either 0 or 1.
mat 中至少有一个 0 mat 中至少有一个 0
问题分析
这题让计算的是每一个位置离它最近的0的距离,因为0到他自己的距离最短,值为0,我们不需要计算,这里只需要计算 1 到离他最近的0的距离即可。
提到最短最近我们首先想到的是BFS,当然这题使用BFS是可以解决的,除了使用BFS还可以使用动态规划来解决,我们来看下动态规划的解决思路。
定义dp[m][n],其中dp[i][j]表示坐标(i,j)离它最近的0的距离。如果要计算坐标(i,j)离它最近的0的距离,那么这个距离肯定要经过他的上下左右4个方向中的一个,我们取最小的即可,也就是:
dp[i][j]=min(dp[i-1][j],dp[i+1][j],dp[i][j-1],dp[i][j+1])+1;注意这里不能出现数组越界,但还有一个问题,就是如果我们从上往下遍历,当计算到dp[i][j]的时候,dp[i-1][j]和dp[i][j-1]的值已经计算过了,但dp[i+1][j]和dp[i][j+1]的值都还没有计算,所以这个时候我们需要两次遍历,先从上往下遍历一次,然后再从下往上遍历一次即可。
JAVA:
public int[][] updateMatrix(int[][] mat) {
int m = mat.length, n = mat[0].length;
int[][] dp = new int[m][n];
int max = m + n;
// 先往上和左搜索,从左上角开始
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
if (mat[i][j] != 0) {// 当前位置只有1的时候才计算
int up = i > 0 ? dp[i - 1][j] : max;// 上
int left = j > 0 ? dp[i][j - 1] : max;// 左
// 选择两个方向的最小值加1
dp[i][j] = Math.min(up, left) + 1;
}
}
}
// 往下和右搜索,从右下角开始
for (int i = m - 1; i >= 0; i--) {
for (int j = n - 1; j >= 0; j--) {
if (mat[i][j] != 0) {// 当前位置只有1的时候才计算
int down = (i < m - 1) ? dp[i + 1][j] : max;// 下
int right = (j < n - 1) ? dp[i][j + 1] : max;// 右
// 选择四个方向的最小。
dp[i][j] = Math.min(Math.min(down, right) + 1, dp[i][j]);
}
}
}
return dp;
}C++:
public:
vector<vector<int>> updateMatrix(vector<vector<int>> &mat) {
int m = mat.size(), n = mat[0].size();
vector<vector<int>> dp(m, vector<int>(n));// 返回结果
int max = m + n;
// 先往上和左搜索,从左上角开始
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
if (mat[i][j] != 0) {
int up = i > 0 ? dp[i - 1][j] : max;// 上
int left = j > 0 ? dp[i][j - 1] : max;// 左
// 选择两个方向的最小值加1
dp[i][j] = min(up, left) + 1;
}
}
}
// 往下和右搜索,从右下角开始
for (int i = m - 1; i >= 0; i--) {
for (int j = n - 1; j >= 0; j--) {
if (mat[i][j] != 0) {
int down = (i < m - 1) ? dp[i + 1][j] : max;
int right = (j < n - 1) ? dp[i][j + 1] : max;
// 选择四个方向的最小。
dp[i][j] = min(min(down, right) + 1, dp[i][j]);
}
}
}
return dp;
}Python:
def updateMatrix(self, mat: List[List[int]]) -> List[List[int]]:
m, n = len(mat), len(mat[0])
dp = [[0] * n for _ in range(m)] # 返回结果
max = m + n
# 先往上和左搜索,从左上角开始
for i in range(m):
for j in range(n):
if mat[i][j]:
up = dp[i - 1][j] if i > 0 else max # 上
left = dp[i][j - 1] if j > 0 else max # 左
# 选择两个方向的最小值加1
dp[i][j] = min(up, left) + 1
# 往下和右搜索,从右下角开始
for i in range(m - 1, -1, -1):
for j in range(n - 1, -1, -1):
if mat[i][j]:
down = dp[i + 1][j] if i < m - 1 else max
right = dp[i][j + 1] if j < n - 1 else max
# 选择四个方向的最小。
dp[i][j] = min(min(down, right) + 1, dp[i][j])
return dp
笔者简介
博哥,真名:王一博,毕业十多年,《算法秘籍》作者,专注于数据结构和算法的讲解,在全球30多个算法网站中累计做题2000多道,在公众号中写算法题解800多题,对算法题有自己独特的解题思路和解题技巧,喜欢的可以给个关注,也可以下载我整理的1000多页的PDF算法文档。
数组,稀疏表(Sparse Table),单向链表,双向链表,块状链表,跳表,队列和循环队列,双端队列,单调队列,栈,单调栈,双端栈,散列表,堆,字典树(Trie树),ArrayMap,SparseArray,二叉树,二叉搜索树(BST),笛卡尔树,AVL树,树堆(Treap),FHQ-Treap
……
图的介绍,图的表示方式,邻接矩阵转换,广度优先搜索(BFS),深度优先搜索(DFS),A*搜索算法,迭代深化深度优先搜索(IDDFS),IDA*算法,双向广度优先搜索,迪杰斯特拉算法(Dijkstra),贝尔曼-福特算法(Bellman-Ford),SPFA算法,弗洛伊德算法(Floyd)
……
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











