







精品推荐:
《征服数据结构》专栏:50多种数据结构彻底征服
《经典图论算法》专栏:50多种经典图论算法全部掌握
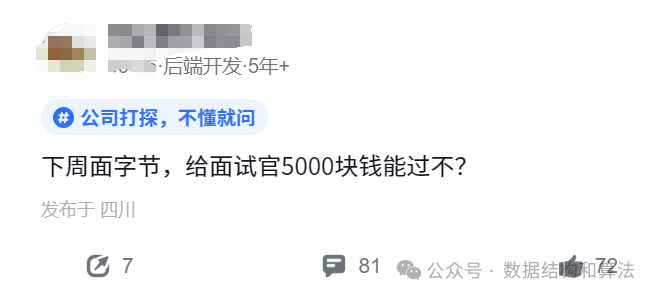
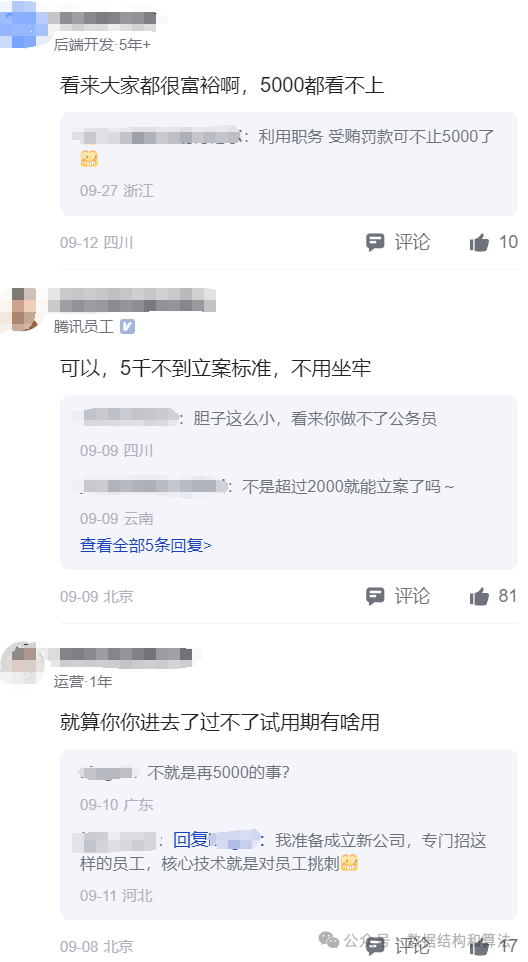
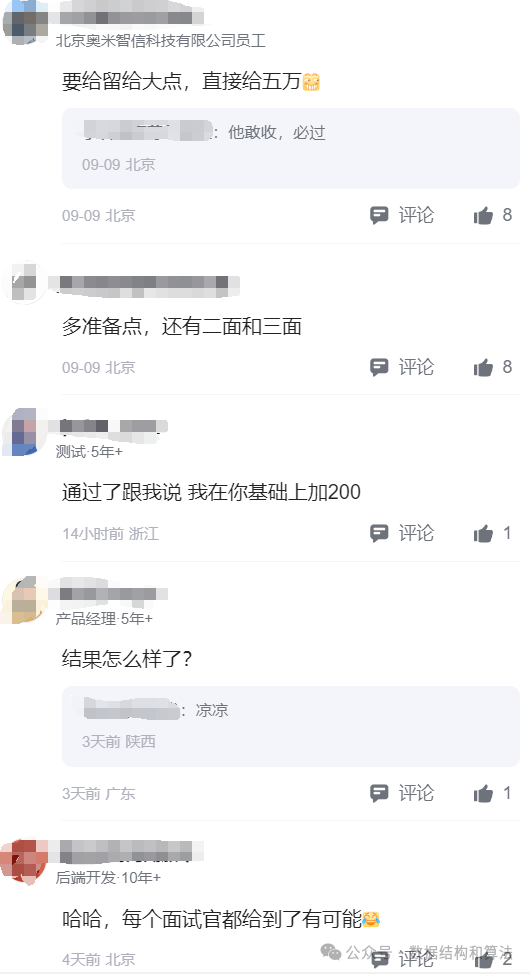
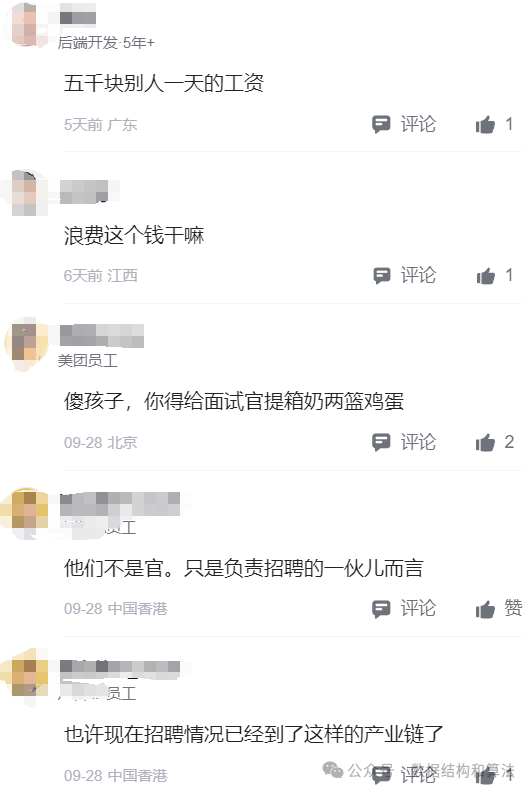
一网友下周要面试字节,问给面试官5000块钱能不能过。首先来说字节的面试官不可能就一个人,如果每个人都给5000,那也不少了,就算都给也不一定保证所有人都收,所以还是不要想一些歪门邪道的 ,提高自己的技能才是正道。
在说5000块钱对于字节面试官来说真的不算啥,徇私舞弊被发现是要被开除的,不可能为了5000块钱冒这么大风险。
--------------下面是今天的算法题--------------
来看下今天的算法题,这题是LeetCode的第347:前 K 个高频元素。
问题描述
来源:LeetCode第347题
难度:中等
给你一个整数数组 nums 和一个整数 k ,请你返回其中出现频率前 k 高的元素。你可以按任意顺序返回答案。
示例1:
输入: nums = [1,1,1,2,2,3], k = 2
输出: [1,2]
示例2:
输入: nums = [1,1,1,2,2,3], k = 2
输出: [1,2]
1 <= nums.length <= 10^5
k 的取值范围是 [1, 数组中不相同的元素的个数]
题目数据保证答案唯一,换句话说,数组中前 k 个高频元素的集合是唯一的
问题分析
这题让找出出现频率前 k 高的元素,我们首先计算数组中每个元素出现的频率,然后再查找出现频率最高的 k 个元素即可。
这里使用《最小堆》,当堆中元素个数大于 k 的时候,就把堆顶元素给移除,也就是把频率低的给移除,保证堆中的 k 个元素都是频率最高的。
JAVA:
public int[] topKFrequent(int[] nums, int k) {
// 统计每个数字出现的频率
Map<Integer, Integer> mp = new HashMap<>();
for (int num : nums)
mp.put(num, mp.getOrDefault(num, 0) + 1);
// 最小堆,根据频率排序
PriorityQueue<int[]> pq = new PriorityQueue<>(Comparator.comparingInt(a -> a[1]));
for (int key : mp.keySet()) {
pq.add(new int[]{key, mp.get(key)});// 添加到堆中
if (pq.size() > k)// 超过 k 个,移除堆顶元素
pq.poll();
}
//把堆中的元素转化为数组
int[] ans = new int[k];
int i = 0;
while (!pq.isEmpty())
ans[i++] = pq.poll()[0];
return ans;
}C++:
public:
vector<int> topKFrequent(vector<int> &nums, int k) {
// 先统计数组中所有元素的频率
unordered_map<int, int> mp;
for (int num: nums)
mp[num]++;
// 使用最小堆,根据频率排序,只能保存k个元素,
auto comp = [](const pair<int, int> &a, const pair<int, int> &b) {
return a.second > b.second;
};
priority_queue<pair<int, int>, vector<pair<int, int>>, decltype(comp)> pq(comp);
for (auto &entry: mp) {
pq.emplace(entry.first, entry.second);
if (pq.size() > k)// 堆中元素超过 k 个,移除多余的
pq.pop();// 移除堆顶元素。
}
// 把堆中的元素转成vector
vector<int> ans;
while (!pq.empty()) {
ans.push_back(pq.top().first);// 取出堆顶元素
pq.pop();// 移除堆顶元素。
}
return ans;
}Python:
def topKFrequent(self, nums: List[int], k: int) -> List[int]:
# 统计每个数字出现的频率
count_map = Counter(nums)
# 最小堆,根据频率排序
min_heap = []
for key, freq in count_map.items():
heapq.heappush(min_heap, (freq, key))
if len(min_heap) > k:
heapq.heappop(min_heap)
# 把堆中的元素转化为数组
ans = [item[1] for item in min_heap]
return ans
笔者简介
博哥,真名:王一博,毕业十多年,《算法秘籍》作者,专注于数据结构和算法的讲解,在全球30多个算法网站中累计做题2000多道,在公众号中写算法题解800多题,对算法题有自己独特的解题思路和解题技巧,喜欢的可以给个关注,也可以下载我整理的1000多页的PDF算法文档。
数组,稀疏表(Sparse Table),单向链表,双向链表,块状链表,跳表,队列和循环队列,双端队列,单调队列,栈,单调栈,双端栈,散列表,堆,字典树(Trie树),ArrayMap,SparseArray,二叉树,二叉搜索树(BST),笛卡尔树,AVL树,树堆(Treap),FHQ-Treap,哈夫曼树,滚动数组,差分数组,LRU缓存,LFU缓存
……
图的介绍,图的表示方式,邻接矩阵转换,广度优先搜索(BFS),深度优先搜索(DFS),A*搜索算法,迭代深化深度优先搜索(IDDFS),IDA*算法,双向广度优先搜索,迪杰斯特拉算法(Dijkstra),贝尔曼-福特算法(Bellman-Ford),SPFA算法,弗洛伊德算法(Floyd),卡恩(Kahn)算法,基于DFS的拓扑排序,约翰逊算法(Johnson)
……
















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











