






点击上方“海边的拾遗者”,选择“星标”公众号
第一时间获取价值内容

导读
最近做了些推荐领域的分布式相关工作,本文结合亚马逊首席科学家李沐发表的论文“Scaling Distributed Machine Learning with the Parameter Server”,来深入浅出地介绍分布式训练框架的架构及原理。
前言
众所周知,在机器学习和深度学习领域,分布式的部署已经成了一种必要条件,对个人来说也是一种工程能力。因为单机早已解决不了目前快速增长的数据和参数了。
实际工业场景中,训练数据的数量可能达到1TB到1PB之间,实际也可能不止,而训练过程中的参数数量则更加恐怖。而往往这些参数需要被所有的worker节点频繁地访问,这就会带来很多问题和挑战。为了解决这些棘手的问题,2014年分布式可扩展的Parameter Server被李沐等人提出,几乎完美地解决了大规模机器学习模型的分布式训练问题,时至今日,PS架构不仅被直接应用在各大公司的机器学习平台上,尤其是在搜索推荐领域,而且也被集成在TensorFlow,MXNet等主流的深度框架中,作为分布式训练最重要的解决方案。
本文要介绍的目录为:
简介
通信
物理架构
并行训练
效率与一致性的取舍
一致性哈希
向量钟
简介
Parameter Server架构由server节点和worker节点组成,其主要功能简单地介绍一下,分别为:
server节点的主要功能是初始化和保存模型参数、接受worker节点计算出的局部梯度、汇总计算全局梯度,并更新模型参数。
worker节点的主要功能是各自保存部分训练数据,初始化模型,从server节点拉取最新的模型参数(pull),再读取参数,根据训练数据计算局部梯度,上传给server节点(push)。
通信
整个架构由非常多的worker组成,那么通信的设计是非常重要的。server节点与worker节点之间的通信如下。
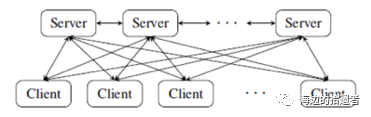
物理架构
在物理架构上,PS其实是和spark的master-worker的架构基本一致的,如下图所示:
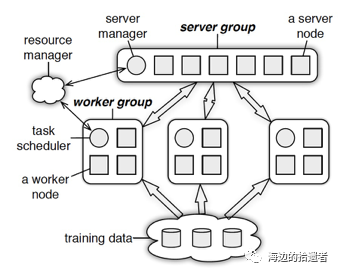
可以看出整个架构分为两大部分:server group和多个worker group,另外resource manager负责总体的资源分配调度。各自的职能分别如下:
server group内部包含多个server node,每个server node负责维护一部分参数,server manager负责维护和分配server资源。
每个worker group对应一个application(即一个模型训练任务),worker group之间,以及worker group内部的worker node互相之间并不通信,worker node只与server通信。
并行训练
PS的并行训练整体如下图所示:
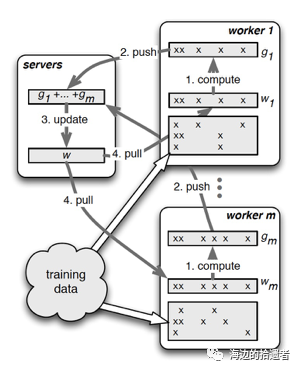
如上图所示,清晰地描述了PS的并行梯度下降流程,其中最关键的两个操作就是push和pull,这里的通信都是Range-based、Key-based或Row-based,可自行选取:
push:worker节点利用本节点上的训练数据,计算好局部梯度,上传给server节点。
pull:为了进行下一轮的梯度计算,worker节点从server节点拉取最新的模型参数到本地。
主要算法步骤如下:

效率与一致性的取舍
这里提下同步阻断式方法,spark并行梯度下降效率较低的原因就是每个节点都需要等待其他所有节点的梯度都计算完后,master节点汇总梯度,计算好新的模型参数后,才能开始下一轮的梯度计算,我们称这种方式为“同步阻断式”的并行梯度下降过程。
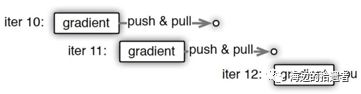
而PS提供的方法中有一种是用“异步非阻断式”的梯度下降替代原来的同步式方法。如下图所示,一个worker节点多次迭代计算梯度的过程,可以看到节点在做第11次迭代(iter 11)计算时,第10次迭代后的push&pull过程并没有结束,也就是说最新的模型权重参数还没有被拉取到本地,该节点仍使用的是iter 10的权重参数计算的iter 11的梯度。这就是所谓的异步非阻断式梯度下降方法,其他节点计算梯度的进度不会影响本节点的梯度计算。所有节点始终都在并行工作,不会被其他节点阻断。
在PS中为用户提供了多种任务依赖方式:
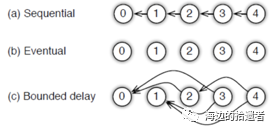
Sequential:这里其实是synchronous task,任务之间是有顺序的,只有上一个任务完成,才能开始下一个任务。
Eventual:跟sequential相反,所有任务之间没有顺序,各自独立完成自己的任务。
Bounded Delay:这是sequential跟eventual之间的trade-off,可以设置一个T作为最大的延时时间。也就是说,只有 T之前的任务都被完成了,才能开始一个新的任务。
一致性哈希
PS架构使用一致性哈希方法来保证各个server各自负责一部分Key;并且在分布式系统中,动态增加和移除节点的同时还能保证系统存储与key分配的性能效率,也就是在已有key不发生大的变化的情况下加入新的节点或删除已有节点。具体如下所示:
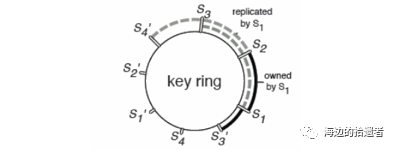
具体步骤为:
1.将模型参数的key映射到一个环形的hash空间,比如有一个hash函数可以将任意key映射到0~(2^32)-1的hash空间内,我们只要让(2^32)-1这个桶的下一个桶是0这个桶,那么这个空间就变成了一个环形hash空间。
2.根据server节点的数量n,将环形hash空间等分成n*m个区域,让每个server间隔地分配m个hash区域。这样做的目的是保证一定的负载均衡性,避免hash值过于集中带来的server负载不均。
3.在新加入一个server节点时,让新加入的server节点找到hash环上的插入点,让新的server负责插入点到下一个插入点之间的hash区域,这样做相当于把原来的某段hash区域分成两份,新的节点负责后半段,原来的节点负责前半段。这样不会影响其他hash区域的hash分配,自然不存在大量的rehash带来的数据大混洗的问题。
4.删除一个server节点时,移除该节点相关的插入点,让临近节点负责该节点的hash区域。
向量钟
PS架构使用vector clock,也就是向量钟技术来记录每个节点中参数的时间戳,能够用来跟踪状态或避免数据的重复发送。但是,假设有n个节点,m个参数,那么vector clock的空间复杂度就O(n*m)。
在push跟pull的时候同一个hash区域里面的参数共享的是同一个时间戳,这显然可以大大降低空间复杂度。

每次从一个range里再提取一个range,最多会生成3个新的vector clocks(一分为三)。假设k是算法中产生的所有的range,那么空间复杂度就变成了O(k*m),因为k远小于参数个数,所以空间复杂度大大降低了。
总结
题外话,看到过一些重构PS的工作,感觉主要是针对效率方面的,毕竟实际场景中serving阶段是比较耗时的,这块优化多follow一些相关研究还挺有意思的,共勉吧~
最后总结下整个PS的分布式训练流程:
1.每个worker载入一部分训练数据。
2.worker节点从server节点pull最新的全部模型参数。
3.worker节点利用本节点数据计算梯度。
4.worker节点将梯度push到server节点。
5.server节点汇总梯度更新模型。
6.goto step2 直到迭代次数上限或模型收敛。
参考文献
【1】Mu Li. Scaling Distributed Machine Learning with the Parameter Server.
【2】Joseph E.Gonzalez. Emerging Systems For Large-scale Machine Learning.
来都来了,喜欢的话就请分享、点赞、在看三连再走吧~~~


















 609
609

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









