







Spark采取了简单直观的数据并行的方法解决模型并行训练的问题,但由于Spark的并行梯度下降方法是同步阻断式的,且模型参数需通过全局广播的形式发送到各节点,因此Spark的并行梯度下降是相对低效的。
为了解决相应的问题,2014年分布式可扩展的Parameter Server被提出,几乎完美的解决了机器模型的分布式训练问题,时至今日,parameter server不仅被直接应用在各大公司的机器学习平台上,而且也被集成在TensorFlow,MXNet等主流的深度框架中,作为机器学习分布式训练最重要的解决方案。
一、Parameter Server的分布式训练原理


可以看到Parameter Server由server节点和worker节点组成,其主要功能分别如下:
- server节点的主要功能是保存模型参数、接受worker节点计算出的局部梯度、汇总计算全局梯度,并更新模型参数
- worker节点的主要功能是各保存部分训练数据,从server节点拉取最新的模型参数,根据训练数据计算局部梯度,上传给server节点。
在物理架构上,PS其实是和spark的master-worker的架构基本一致的,具体如图2
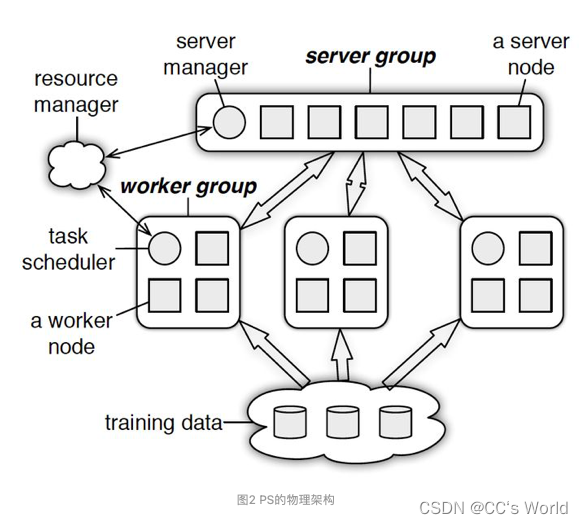
可以看到,PS分为两大部分:server group和多个worker group,另外resource manager负责总体的资源分配调度。
- server group内部包含多个server node,每个server node负责维护一部分参数,server manager负责维护和分配server资源;
- 每个worker group对应一个application(即一个模型训练任务),worker group之间,以及worker group内部的worker node互相之间并不通信,worker node只与server通信。
结合PS的物理架构,PS的并行训练整体示意图如图3:
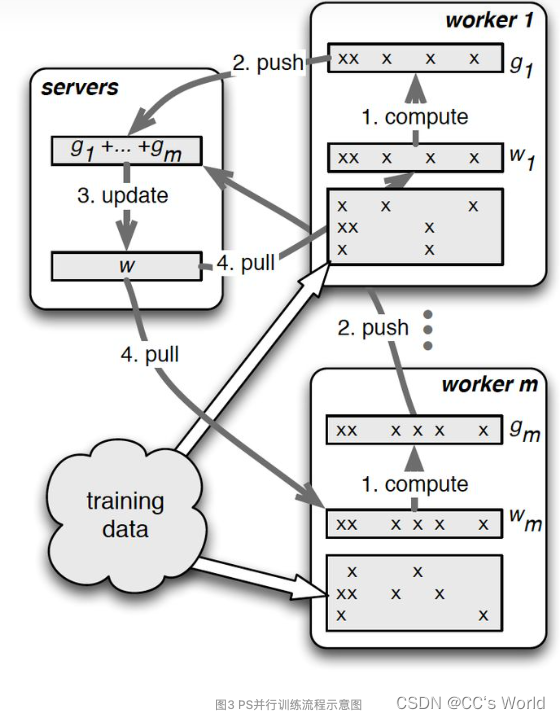
图3结合图2描述的并行梯度下降方法的伪码以及图2的PS物理架构,清晰的描述了PS的并行梯度下降流程,其中最关键的两个操作就是push和pull:
- push:worker节点利用本节点上的训练数据,计算好局部梯度,上传给server节点;
- pull:为了进行下一轮的梯度计算,worker节点从server节点拉取最新的模型参数到本地。
结合图3这里概括一下整个PS的分布式训练流程:
- 每个worker载入一部分训练数据
- worker节点从server节点pull最新的全部模型参数
- worker节点利用本节点数据计算梯度
- worker节点将梯度push到server节点
- server节点汇总梯度更新模型
- goto step2 直到迭代次数上限或模型收敛
二、一致性与并行效率之间的取舍
spark并行梯度下降效率较低的原因就是每个节点都需要等待其他所有节点的梯度都计算完后,master节点汇总梯度,计算好新的模型参数后,才能开始下一轮的梯度计算,我们称这种方式为“同步阻断式”的并行梯度下降过程。
“同步阻断式“的并行梯度下降虽然是严格意义上的一致性最强的梯度下降方法,因为其计算结果和串行计算的过程一直,但效率过低,各节点的waiting时间过长,有没有办法提高梯度下降的并行度呢?
PS采取的方法是用“异步非阻断式”的梯度下降替代原来的同步式方法。图4是一个worker节点多次迭代计算梯度的过程,可以看到节点在做第11次迭代(iter 11)计算时,第10次迭代后的push&pull过程并没有结束,也就是说最新的模型权重参数还没有被拉取到本地,该节点仍使用的是iter 10的权重参数计算的iter 11的梯度。这就是所谓的异步非阻断式梯度下降方法,其他节点计算梯度的进度不会影响本节点的梯度计算。所有节点始终都在并行工作,不会被其他节点阻断。
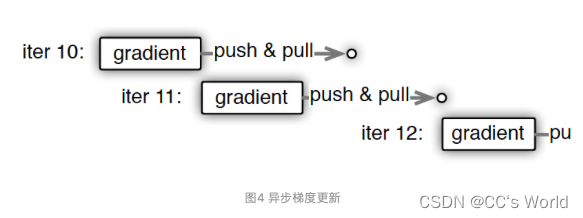
当然,任何的技术方案都是取舍,异步梯度更新的方式虽然大幅加快了训练速度,但带来的是模型一致性的丧失,也就是说并行训练的结果与原来的单点串行训练的结果是不一致的,这样的不一致会对模型收敛的速度造成一定影响。所以最终选取同步更新还是异步更新取决于不同模型对于一致性的敏感程度。这类似于一个模型超参数选取的问题,需要针对具体问题进行具体的验证。
除此之外,在同步和异步之间,还可以通过一些“最大延迟”等参数来限制异步的程度。比如可以限定在三轮迭代之内,模型参数必须更新一次,那么如果某worker节点计算了三轮梯度,该节点还未完成一次从server节点pull最新模型参数的过程,那么该worker节点就必须停下等待pull操作的完成。这是同步和异步之间的折衷方法。
三、多server节点的协同和效率问题
导致Spark MLlib并行训练效率低下的另一原因是每次迭代都需要master节点将模型权重参数的广播发送到各worker节点。这导致两个问题:
- master节点作为一个瓶颈节点,受带宽条件的制约,发送全部模型参数的效率不高;
- 同步地广播发送所有权重参数,使系统整体的网络负载非常大。
那么PS是如何解决单点master效率低下的问题呢?从图2的架构图中可知,PS采用了server group内多server的架构,每个server主要负责一部分的模型参数。模型参数使用key value的形式,每个server负责一个key的range就可以了。
那么另一个问题来了,每个server是如何决定自己负责哪部分key range呢?如果有新的server节点加入,又是如何在保证已有key range不发生大的变化的情况下加入新的节点呢?这两个问题的答案涉及到一致性哈希(consistent hashing)的原理。
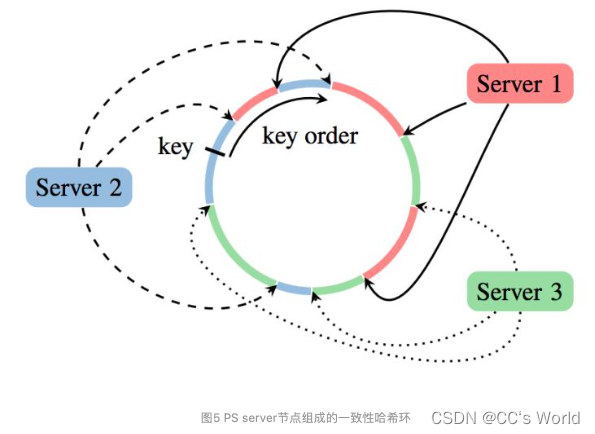
PS的server group中应用一致性哈希的原理大致有如下几步:
- 将模型参数的key映射到一个环形的hash空间,比如有一个hash函数可以将任意key映射到0~ ( 2 32 ) − 1 (2^{32})-1 (232)−1的hash空间内,我们只要让 ( 2 32 ) − 1 (2^{32})-1 (232)−1这个桶的下一个桶是0这个桶,那么这个空间就变成了一个环形hash空间;
- 根据server节点的数量n,将环形hash空间等分成n*m个range,让每个server间隔地分配m个hash range。这样做的目的是保证一定的负载均衡性,避免hash值过于集中带来的server负载不均;
- 在新加入一个server节点时,让新加入的server节点找到hash环上的插入点,让新的server负责插入点到下一个插入点之间的hash range,这样做相当于把原来的某段hash range分成两份,新的节点负责后半段,原来的节点负责前半段。这样不会影响其他hash range的hash分配,自然不存在大量的rehash带来的数据大混洗的问题。
- 删除一个server节点时,移除该节点相关的插入点,让临近节点负责该节点的hash range。
PS server group中应用一致性哈希原理,其实非常有效的降低了原来单master节点带来的瓶颈问题。比如现在某worker节点希望pull新的模型参数到本地,worker节点将发送不同的range pull到不同的server节点,server节点可以并行的发送自己负责的weight到worker节点。
此外,由于在处理梯度的过程中server节点之间也可以高效协同,某worker节点在计算好自己的梯度后,也只需要利用range push把梯度发送给一部分相关的server节点即可。当然,这一过程也与模型结构相关,需要跟模型本身的实现结合起来实现。总的来说,PS基于一致性哈希提供了range pull和range push的能力,让模型并行训练的实现更加灵活。
四、Parameter Server的技术要点总结
总结一下Parameter Server实现分布式机器学习模型训练的要点:
- 用异步非阻断式的分布式梯度下降策略替代同步阻断式的梯度下降策略;
- 实现多server节点的架构,避免了单master节点带来的带宽瓶颈和内存瓶颈;
- 使用一致性哈希,range pull和range push等工程手段实现信息的最小传递,避免广播操作带来的全局性网络阻塞和带宽浪费。
但要注意的是,Parameter Server仅仅是一个管理并行训练梯度的权重的平台,并不涉及到具体的模型实现,因此PS往往是作为MXNet,TensorFlow的一个组件,要想具体实现一个机器学习模型,还需要依赖于通用的,综合性的机器学习平台。















 440
440











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









